
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
Copies of the source code for this software may be downloaded from http://JayReynoldsFreeman.com/My/Software.html. If you cannot find that site or have difficulty using it, contact me by EMail at Jay_Reynolds_Freeman@mac.com.
A copy of the GNU General Public License is available while running the program, via menu item "Warranty and Redistribution" of the Wraith Scheme menu. You may also find the license on line at http://www.gnu.org/licenses.
The Wraith Scheme executable program itself is shareware: You are welcome to use Wraith Scheme for free, forever, and to pass out free copies of it to anybody else. If you would like to make a shareware donation for it, that's fine, and there is information in the program about how to go about it, but in no sense do I request, insist, or expect that you do so. Furthermore, Wraith Scheme is intended to be complete and fully functional as downloaded. There is nothing to buy, there are no activation codes required, and there are no annoying reminders about shareware donations.
Introduction
The Source Distribution
What's New
In Brief
Brief Technical History and Description of Wraith Scheme
Brief Introduction to Wraith Scheme Parallel Processing
On Reading the Code
Motivation and Beginnings
Language, Compilers and Code, Oh My
MPW C
GNU and Unix
Xcode, Cocoa, and more Unix
Scheme by its Bootstraps
Design Influences and Architecture
An SECD Machine as an Architectural Level
Tagged Avals
User Interface Architecture
Scheme Machine Assembly Language
Scheme Machine Microcode
The Scheme Machine
Bringing Up Baby
Views of the Architecture
Main Memory, the Memory Manager, and the Garbage Collector
How Multiple Wraith Scheme Processes Interact with Memory
Types and Typing in Wraith Scheme
Object-Oriented Code in Wraith Scheme
Wraith Scheme Makefiles and Their Uses
A Guide to the Directory Structure
Source Code Versioning for Wraith Scheme
Localizing the Build and Test Environment
Building and Testing Wraith Scheme
Concepts to Know About
Cdr-Coding
A Note About Forwarding Pointers
Symbols and the ObList
Layout of Scheme Main Memory
Memory Allocation and Cdr-Coding
World Files
Memory-Mapping and MMAP
Some Background for mmap
Permanent Bindings
Wraith Scheme In Unix Shells
The TTY Implementation
The NCurses Implementation
Files Used in the Cocoa Implementation
The Memory Manager
Allocation Caches
The Clowder
Clowder Responsibilities
Clowder Shared Memory Content
Locking Tagged Avals
A Cautionary Tale
Pointers from Scheme Main Memory
The World Handler
World Handler Issues
Pointers Within Scheme Main Memory
Mismatched Worlds
Big-Endian and Little-Endian
The Garbage Collectors
The Full Garbage Collector
Background
Single-Process Garbage Collection -- A Broad Look
Identifying Non-Garbage
Copying Across
Moving from Low to High
Updating Pointers
Expiring Forgettable Memory
Garbage Collecting of Ports
Bagging Garbage, Other Cleanup, and Compaction
Checking the Memory Spaces for Consistency
Multi-Process Garbage Collecting -- Issues
Multi-Process Garbage Collecting -- Coordinating
Multi-Process Garbage Collecting -- Sharing the Work
Multi-Process Garbage Collecting -- Parallel Worlds
Multi-Process Garbage Collecting -- A Sop to NUMA
Garbage Collection Summary
The Generational Garbage Collector
Generational Garbage Collection
Generations
Memory Space Use for Generational Garbage Collection
Extra Roots for Generational Garbage Collection
Identifying New Non-Garbage
Copying Down
Pointer Updates for Generational GC
Wraith Scheme Events
Background and Apologia
Pixie Scheme and Cocoa Events
Events in the Terminal Implementations
The Scheme Machine Event Loop in the Cocoa Implementation
The Cocoa Event Loop in the Cocoa Implementation
Coordinating the Cocoa Implementation -- Events
Coordinating the Cocoa Implementation -- I/O
The Wraith Scheme Interrupt System
SIGINT Interrupts
SIGALRM Interrupts
SIGUSR1 Interrupts
Summary of SIGUSR1 Interrupt Operation
Precautions for Using Interrupts
Environments and Environment Lists
Particular Data Structures
Local Types
Tagged Avals (Again)
File Descriptors
Data Descriptors
Memory Space Descriptors
Memory-Mapped Block Descriptors
Function and Special Form Descriptors
Type and Arity Checking
The Evaluator
The Evaluation Status Register
Evaluation Stack Frames
Tail Recursion
Adding a New Wraith Scheme Primitive
Initializing Wraith Scheme
Initializing -- Single Wraith Scheme Process
Initializing -- Multiple Wraith Scheme Processes
Initializing -- More about Synchronization
Initializing -- More about the Cocoa Implementation
Building the Default World
The Compiler
The Macro System
The Traditional Macro System
The Hygienic Macro System
Package Management
User Interface Design
Teletype Interfaces
A Teletype With Two Rolls of Paper
Menus, Buttons, and Drawers
An Instrument Panel
Browser Interfaces
A Magic Slate
Talking to the Magic Mirror
Tracking Typed Text
A Few Bells and Whistles
The Return of Pixie Scheme
Pixie Scheme Design Considerations
Pixie Scheme Scheme Machines
Pixie Scheme II
Pixie Scheme III
Things I Might Do in the Future
Things I Probably Won't Do in the Future
Acknowledgments
Bibliography
Welcome to the "Internals" file for Wraith Scheme, an implementation of the Scheme programming language for the Apple Macintosh™. Wraith Scheme was written by me, Jay Reynolds Freeman. By all means Email me about it if you wish.
I decided to write about the internals of Wraith Scheme for many reasons:
This material is more technical than the other Wraith Scheme documentation that I have written. Readers who do not have a certain amount of knowledge about programming in general and Lisp-class languages in particular, may find the going difficult.
I have tried to create the kind of document that I myself have always wanted, but never had, when I have found myself needing to come up to speed on a large and complicated piece of somebody else's code. This document is not a line-by-line guide to the code. It is partly a description of the architecture of the Wraith Scheme program, and partly a background document that gives medium to high-level information about how and why the code was written, and how it is supposed to work. Only you can judge how good a job I have done. By all means let me hear from you if something is missing, incomprehensible, or seems incomplete. I am sure the document has faults, if only because I am too close to my own work to have any sense of what about it is going to be most confusing to a newcomer. Yet I hope it will be useful, even so.
I think that the order in which I write about things herein is more or less the order in which a newcomer to the Wraith Scheme implementation should study them. Yet I could be wrong, and this document is so long that very likely nobody else but me will ever read the whole thing anyway. Indeed, there is probably more here than any one person could possibly want to know about Wraith Scheme, perhaps even me. Notwithstanding, it may help to have as much information in one place as possible.
This document mentions specific files and data structures in the Wraith Scheme source code. Source code is not provided in the download that includes the executable Wraith Scheme application; it is available in a separate, much larger download, from the "Software" page of my web site. The home page of that web site is http://JayReynoldsFreeman.com.
Don't be intimidated by the size of the source distribution. It contains many pictures, many long source files for testing, many long "gold" files for comparison with test results, and a lot of documentation. The actual source code -- C++, Objective C, and some Scheme itself -- comprises about 80000 lines.
The distribution as provided should build and run in approximately version 13.2 of Apple's "Xcode" development environment. That version of Xcode runs on macOS 11.6 ("Big Sur").
Some of the build targets in the Makefile do not require Xcode -- see the section on Wraith Scheme In Unix Shells, later herein. The present software distribution supports versions of Wraith Scheme that do not require the full Macintosh interface.
I do not presently plan to host an open-source development project. Notwithstanding, if there is sufficient interest, and if I can find a suitable place to put a large repository, I would be happy to do so.
If you have found a bug in Wraith Scheme and have code for a solution, or if you have some enhancement you would like to share, by all means let me know, for possible integration into my own next release of Wraith Scheme. I will of course give credit where it is due.
Here is a list of recent substantial changes in the Wraith Scheme "Internals" document, most recent first:
I believe Wraith Scheme is a complete implementation of the "R5" dialect of Scheme (major Revision 5 of Scheme). (The complete guide to that version is the 1998 Revised5 Report on the Algorithmic Language Scheme, edited by Richard Kelsey, William Clinger and Jonathan Rees. That report is available on several Internet sites, such as http://www.schemers.org.) There is one caveat to the word "complete": The R5 report describes a number of optional Scheme features, using language like "some implementations support ...", or something similar. Wraith Scheme does not support all of those features.
For further details as to how Wraith Scheme conforms to and enhances the Scheme specification of the R5 report, see other material that I have provided, such as the Wraith Scheme Help file and the Wraith Scheme Dictionary, both of which come bundled as part of the released program. The document you are reading has to do with the internals of Wraith Scheme, at the level of reading and perhaps even understanding the source code.
The version of Wraith Scheme for which this "Internals" document is prepared is Wraith Scheme 2.27, which is a 64-bit application for the Apple Macintosh, that requires at least macOS 11.6 ("Big Sur") and either Intel microprocessors or Apple's arm-based proprietary processors ("Apple silicon"). Earlier versions of the 64-bit application do exist, starting with 2.00, and there is also a 32-bit version, whose first release was 1.00 and whose most recent is 1.36 as I write these words. Much of the material herein will also apply to those earlier versions. I have not released the 32-bit versions as freeware. (They are not particularly secret; I am just too lazy to support two big open-source distributions). Even so, the descriptions of how things work that I provide in this document may apply to them.
Wraith Scheme was named after my late, lamented, scruffy gray cat, "Wraith". If you don't think that makes sense, remember that it runs on a computer named after a raincoat.
A version of this section also appears in the Wraith Scheme Help file.
I changed to 64 bits and to Snow Leopard or better to allow Wraith Scheme to have a larger Scheme memory than one Gigabyte, and to allow me to use some of the special Macintosh software features that are not available in earlier versions of Mac OS.
In consequence, for a C program, Pixie Scheme was remarkably easy to modify and maintain. For example, it took only a few hours to add support for IEEE 80-bit floating-point numbers to Pixie Scheme, and most of that time was spent writing functions that actually implement operations on these entities, not in tying 80-bit floats into the control-flow structure of the program. Wraith Scheme retains the same ease of modification.
The view is an interface built using Apple's Interface Builder application and its descendents in Xcode, together with code for a number of supporting controllers for specific components of the view. That code is mostly written in Objective C.
The main controller -- the one that sits between the model and the view -- has two parts. The first part comprises a fair number of semi-autonomous methods whose actions are triggered by various events, such as typing "return" in the Wraith Scheme Input Panel or operating one of Wraith Scheme's buttons or menu items. The second part is a timing mechanism, that polls the evaluator thread regularly, to see if it has anything for the controller to do.
A version of this section also appears in the Wraith Scheme Help file.
Since Wraith Scheme is named after a cat, I decided to continue the feline metaphor. The privileged Scheme process is called the "MomCat", and the others are called "kittens". The image of a mother cat trying to ride herd on a bunch of rambunctious offspring is perhaps appropriate. (A friend of mine once claimed to have a fifth-degree black belt in the little known Japanese martial art of ikeneko -- which means "cat arranging". Programmers will be familiar with the skill required. Managers of programmers will be extremely familiar with that skill.)
There is no way to add kittens to a group of parallel Wraith Scheme processes that is already running. You may remove a kitten from a group via, e.g., the "Quit" command from that kitten's Wraith Scheme menu, but there is no means to put back a kitten that is gone, or to add a new one if you need more, other than changing the Wraith Scheme preferences and restarting Wraith Scheme.
Each kitten has a number -- its kitten number -- that identifies it uniquely. The MomCat also has a kitten number, which is always zero, and the terms "MomCat" and "kitten 0" are synonyms. The other kittens are numbered consecutively from 1.
Plausible uses for parallel Wraith Scheme might include running completely separate programs, running distinct programs which all need to act on a common data structure, or using one Wraith Scheme process to inspect or monitor another. Separate Wraith Scheme processes may also be useful for monitoring or dealing with asynchronous input or interrupts.
Among the hidden virtues of this kind of parallelism are reduction in swapping due to sharing a common Scheme memory, and leveraging the Unix mechanisms to switch and schedule processes instead of having to write your own.
By "low-level measures", I mean, for example, that I have attempted to maintain the integrity of Scheme main memory by blocking conflicting simultaneous writes.
Thus, for example, if two or more kittens apply "set!" to the variable "x" at more or less the same time, the value of "x" after all the "set!" operations have returned will be a value that one of the kittens intended, but in the absence of additional locking or sequencing mechanisms imposed by the user, there is no guarantee which of the several values of "x" will obtain.
On the other hand, the storage location referenced by "x" should not end up in an invalid state, such as might occur if different portions of the data structure at that storage location had ended up written by different kittens, who were perhaps attempting to write different kinds of values at more or less the same time. Failure to guard against such a race condition might for example result in a tag that said "string" accompanying a data value that was in fact merely an integer, resulting in a crash when some subsequent operation attempted to read the "string" beyond the end of the integer. My means of blocking conflicting simultaneous writes is (knock on wood) intended to prevent such disasters.
Operations like "define", "set-car!", and "set-cdr!" -- indeed, everything that ends with a '!', and some others -- are similarly protected; that is, from the viewpoint of the Wraith Scheme evaluation process, they are what is called atomic operations.
Each application in the cluster accesses memory in two architecturally different ways. First, it accesses memory for its own private use -- notably but not exclusively for the text, heap and stack segments of its C++ and Objective-C operations. Second, it shares with the other applications in the cluster a large memory-mapped area which is a global resource -- Scheme main memory for all applications in the cluster. The protocol for accessing this resource involves lockless coding.
Furthermore, one application in the cluster -- the MomCat -- is special. The MomCat is responsible for coordinating the activities of the other applications in the cluster, when such coordination is required -- notably but not exclusively for garbage collection.
If you do decide to look at any of the source code for Wraith Scheme, you may need to know a few things about my style and preferences.
if( whatever ) {
stuff
more stuff
}
else {
other stuff
still more stuff
}
while( the world turns ) {
this
that
the other
}
I started programming with Fortran II (a most interesting language to use, as the machine we were using it on did not have a call stack) as an undergraduate at the California Institute of Technology in the mid 1960s, and continued to use only varieties of Fortran (generally with call stacks) up through the completion of my physics doctoral thesis project. I became more intrigued with programming languages as time went by, and by the early 1980s I was ready for some new ones. I learned C on a PC I had built at home, Steve Ciarcia's MicroMint MPX-16, running a 4.7 MHz Intel 8088 and CPM-86, using the DeSmet C compiler.
(What fun bringing up a computer from a bare board! I remember making a careful aesthetic judgment about what color bypass capacitors to use; I went for California-mellow earth-tone brown. Also, I am not sure the DeSmet folks ever forgave me for pointing out a typographical error in the source code for their compiler on the basis of a disassembly of generated code.)
A 16-bit C system was neat to learn with, but not quite as capable as I wished. Fortunately, my employers had a Digital Equipment Corporation 20/40 mainframe computer that mostly sat idle, and I had a VT-100 terminal connected to it sitting on my desk at work. At the time, the DEC-20 was considered a very serious machine, with a whopping 256K words of 36-bit memory. (No typo, I do mean "36 bits". Remember, if you don't have 36 bits, you aren't playing with a full DEC.) Although it did not have support for any language nearly as modern as C, there was some interesting older arcana to be had from the DEC User's Group, DECUS.
It had already occurred to me that a good way to widen my horizons as a programmer might be to try my hand at a language that was as different from Fortran as I could find. Now there was an obvious choice, because the DECUS tapes had MACLisp, a venerable and very fine classic Lisp implementation based in great part on work done at MIT during the previous decade. So I spent many hours before work in the morning, or after work at night (and it was not always entirely clear which was which), with a copy of Winston and Horn's "Lisp" in hand, learning the language and becoming impressed with its power and versatility, especially compared to Fortran II.
My next job involved helping to implement a data-analysis scheme based on category theory in Lisp. It would have been fascinating if I had understood it. The Lisp implementation was "RLisp", a chimera involving a rather standard Lisp with an Algol-60-like syntax layered on top of it. (Caution: "RLisp" now most often refers to a Lisp embedded in Ruby -- it didn't then.)
Then I got hired by FLAIR -- Fairchild Laboratory for Artificial Intelligence Research -- it would have been infelicitous to make an acronym out of Fairchild Artificial Intelligence Laboratory -- just about when Schlumberger bought Fairchild, spun off most of it, and renamed the AI lab to SPAR (Schlumberger Palo Alto Research). SPAR was a world-class facility, literally down the hill from Xerox PARC -- which led to discussion of whether SPAR meant Sub-PARc, and to frequent citation of the venerable Psalms 121:1, freely translated: "I will lift up mine eyes unto the hills, from whence cometh my inspiration." It had a veritable insectarium of wonderfully-named Symbolics 3600 Lisp machine workstations, like "Moaning Milky Medfly" or "Praying Green Mantis". (The basic namespace was insects, with one adjective to indicate whether the particular machine had a speaker or not, and another to indicate whether its display was monochrome or color, and yes, "Praying Green Mantis" was a deliberate pun.)
I was way over my head in terms of theoretical knowledge and Lisp coding skills, but I didn't tell anyone, and besides, what fun is swimming when you can touch the bottom with your feet.
Lisp continued to fascinate me, but the standard varieties of the language were evolving into monstrous constructs. Zetalisp, the Symbolics dialect when I first encountered the machines, was huge, and its closely-related replacement, Common Lisp, was bigger still. Furthermore, the language had a few warts that purists might object to, like not treating functions quite the same as other data, and like handling recursion with a big call stack when it wasn't strictly necessary.
I was becoming interested in enhancements to Lisp, to deal with things of personal interest, such as parallel programming. (Most of my career in computer science has been spent dealing with parallel hardware in one way or another.) That would require a Lisp implementation that I could modify, and the thought of doing so with something as gargantuan as Common Lisp was daunting.
About then, someone -- it may have been Judy Anderson -- suggested Scheme as a small, elegant Lisp. There was an implementation on the 3600s -- implementing one Lisp in terms of another is a time-honored tradition. I played with it and found it righteous. I bought a commercial implementation for my shiny new Mac II, but became suspicious of its quality when I asked if 1.0 was an integer and it said "no" (that is, (integer? 1.0) => #f) . I already had plenty of reasons to write my own implementation, but that was the straw that broke the camel's back, and I was off.
Wraith Scheme's source code comprises a whole lot of C++, modest amounts of Objective-C and of Scheme itself, and one file containing assembler embedded in C++ functions, whose purpose is to permit use of "locked" test-and-set and test-and-clear assembly language instructions for locking objects in Scheme main memory while they are being accessed. A historical perspective might help understand how all this stuff fits together, and why I did it the way I did.
When I started writing code for a Scheme interpreter, in 1987, it was a different era. C++ seemed promising, but there were no decent compilers for it yet. A Megabyte was a lot of memory, ten MHz was a really fast processor, "Gnu" was the common name of an esoteric species of silly-looking African ungulates, and "open-source" was a failure mode in MOSFET transistors.
Apple did support an object-oriented programming language -- Object Pascal -- but I had little experience with Pascal and did not particularly like it. Apple had a reasonable C compiler, bundled with its Macintosh Programmer's Workshop development environment, but it was not even ANSI-standard C yet -- function prototypes were optional, and so on through a long list of abominations. Mac programs were single-threaded, you were supposed to roll your own event loop, and oh, by the way, yes, it was indeed great fun hunting brontosaurus with all the clan.
But I knew C and had been programming in it for years, function prototypes or not.
So, after demonstrating enough stubbornness to terrify a cat and spending enough spare time to prove to anyone who might have cared that I desperately needed a life, I had in hand a reasonably functional R3 Scheme -- Pixie Scheme -- and was even bold enough to release it as shareware. It made almost twenty-five dollars altogether -- that is gross receipts, not net -- but the lift to my ego was priceless, and it was a lot of fun getting it going.
Then I began to suspect that a 16-MHz machine with only 5 MByte of usable address space was probably not sufficient hardware to tackle the artificial intelligence problems that interested me; at least, not with any program that I was capable of writing. (That was my 1987 model Mac II, with a RAM upgrade, and it was arguably the most powerful personal computer on the market at the time I bought it.) So I shelved Pixie Scheme and did other things for a decade or two.
Fast-forward to 2006, when I finally got around to replacing my tired Mac II with a shiny new Macbook 13. (One of the virtues of working in the computer industry is that you can get big companies to give you all the toys you want to play with, so you don't need to keep buying them for home.) It dawned on me that the most important change in personal computers in two decades had been to replace "Mega" with "Giga" in all the places that mattered. My new Macbook had 1000 times as much memory, 1000 times as much disk space, and by any reasonable criterion 1000 times as much processor power as its predecessor. Perhaps Pixie Scheme might run a little faster on such a machine.
How do you port thirty thousand lines of twenty-year-old code to new languages, new operating systems, new libraries, and new programming paradigms? I didn't know. I still don't. Fortunately, I didn't bother thinking about it -- if I had, I like to think I would have had enough sense to run screaming. I just pressed on regardless.
First, I had to recover the source. It was in a BinHex archive that I had squirreled away on a Unix machine, but somewhere along the line I had foolishly passed the archive through software that substituted something like user name and date for one of those useless two-character strings that nobody would ever care about except when it turns up in places like BinHex archives. I had to hand-edit the archive file before I could expand it successfully and retrieve the source.
I decided to port to the modern Mac by way of an intermediary with a classic Unix stdin/stdout interface. Thus I could get the heart of the code -- the Scheme machine -- running again, while using a well-established and uncomplicated user interface.
Ripping out the Toolbox calls was no problem. I had always anticipated that some day, Pixie Scheme might run in a different environment. So I had reasonably encapsulated the Toolbox stuff in a separate file with a tolerably well-defined interface to the rest of the code, kind of like the model-view-controller paradigm, but a bit before its time. Sometimes I do something right: It turned out not to be a big deal to install a simple stdin/stdout interface in its place.
My hand-rolled event loop remained not only viable but also very straightforward. It had only a few events that required reporting to the user, a few places to stop and wait for the next character, and a simple signal-handler for control-C, for when the user wanted to get the program's attention while it was doing something else.
In this form, my resurrected program came up and ran fairly quickly. The GNU C compiler compiled nearly all of the original code, with no changes.
I decided to press development forward on two fronts. I continued to use the Terminal version of the program to shake down and refine the Scheme machine, and started a separate line of development toward a thoroughly modern Mac graphical user interface (GUI) to wrap around it.
On the "Scheme machine" effort, I bit a big bullet: I changed all the .c file names to .c++ and ran them through the GNU C++ compiler -- I think it was 3.0 -- with "all" warnings enabled (-Wall), and fussed with the code till I got an error-free compile. That shook out a lot of fluff, but I didn't find any real crashers. I had of course been using lint-like utilities since square one of development, and had tried scrupulously not to cut corners in coding style. Been there, done that, got the tee shirt: It's bloody.
Sometime about there I decided to rename the project. Thus Wraith Scheme was born.
I found more errors later when I switched from a 32-bit application to a 64-bit one. I had created typedefs to call out "full-sized" words from the start, but there was nothing like changing "full-sized" from 32 to 64 bits to find places where I had not used them consistently.
On the interface side of things, I had used NeXT hardware and software in the mid 1990s. Thus I knew that Objective C was a straightforward insertion of a Lisp function-calling mechanism into plain vanilla C, and I was familiar with early versions of some of the Xcode tools, and with the enormous libraries of NS-what-have-you stuff that supported code development. I even remembered that "NS" stood for "Next Step". Thus I was off to a good start getting a Macintosh GUI written with these tools, but it took a while to shake off the rust. Furthermore, it rapidly became clear that the simplest way to adapt my Scheme machine so that it least gave the appearance of doing things <fanfare>The Macintosh Way</fanfare> would be to run both it and its hand-rolled event loop, in a separate thread. Synchronization and communication between that thread and the one running the UI was going to be tricky. I decided to procrastinate, and write another version of my Scheme, with a user interface that was more complicated that stdin/stdout, but less complicated than a full-blown canonical Macintosh application.
I ended up doing an implementation whose interface was based on an older and more widely-available Unix ASCII-graphics system: I got a version of Wraith Scheme up and running in a Terminal shell using ncurses. That was interesting in its own right -- I had never used ncurses before, and Apple's support for it had a few bugs. Yet the project gave me additional, valuable experience at abstracting the requirements for a GUI and for its encapsulating controller and interface code, away from the Scheme machine.
I have continued to maintain and test all these versions of Wraith Scheme: My regular builds create and test the one with the Mac GUI interface, the one with ncurses, and the one that just uses stdin and stdout. The two terminal versions lack much of the GUI window dressing of the Mac build, and they do not implement parallel processing. Nevertheless, they are occasionally useful when I break the Mac GUI build, and would be good place to start if I ever port Wraith Scheme to another architecture -- or if you do.
If someone out there is wondering why I didn't try an X11 graphical user interface, the answer is simple. I didn't know anything about X11, and I still don't.
As Wraith Scheme developed, I took to writing some of its code in Scheme itself. That worked fine, but there was an interesting problem when it came to the implementation of hygienic macros. The code to create and expand them is written in Scheme, and makes frequent use of Scheme constructs which themselves are defined as macros. Thus there is a chicken-and-egg problem: How can you use macros to expand their own definitions into a form where you can use them?
The solution I chose was bootstrapping, and I have since learned that that solution is common. I wrote some Scheme routines that would expand the code that defined hygienic macros into the underlying low-level constructs that do not use macros, and write out the expanded macro code into files. Getting those files right for the first time was quite a job -- I had to hand-expand all the macros. When it was done, though, I had an easy way to build Scheme worlds and propagate changes. When I create a Wraith Scheme world, I load in the expanded macro files, so that the macros can be used. Then I use my Scheme routines that expand macros, to generate new versions of the expanded files. If the new ones agree with the old ones, all is well.
Not every function in every file that goes through the bootstrapping process has its macros expanded. Not all of the functions are required to get the macro-processor and compiler running. Since the first bootstrap was done by hand, with some difficulty, I arranged to bootstrap only a minimal set of functions.
I used the same trick, of maintaining old files with the macros expanded and generating new ones in each build, for all the other Scheme code that goes into a Wraith Scheme world. I took care to provide plenty of software support in my own development environment, even above and beyond normal version-control stuff, to be sure not to overwrite any set of expanded files prematurely. I also keep a few recent versions of Wraith Scheme, complete with worlds, on hand, so that I can run my macro-expansion software on the relevant Scheme source if I have somehow broken the current build of Wraith Scheme.
I have often wondered whether bootstrapping works for chickens as well. All I really know is that I once heard Steven Hawking asked which came first, the chicken or the egg, and he answered that it was definitely the egg. So I guess I will go with that.
Technical Note: It eventually occurred to me that Hawking was absolutely right: The amniotic egg, with its waterproof enclosure, evolved more than 300 million years ago, but the chicken is a modern species. I wonder if anyone ever asked Hawking why the chicken crossed the road.
Probably the best single thing that happened to my Lisp-implementation project was that I was deprived of a personal computer at the time I was beginning to work seriously on it. I was in the process of moving from Palo Alto to Santa Cruz, and had started to box things up, including my home computer. Then, for one reason or another, the move got delayed for the better part of a year. With no computer at hand, I could not make the classic mistake of just starting to code -- instead, I had to do serious design, and think about what I was doing at an abstract level, and that was an enormous benefit.
Designing a Lisp implementation involves architectural decisions of many kinds, at many levels. For example:
Some of those questions are answered when discussing the type of Lisp to be implemented -- such as whether functions get treated as a different kind of entity than other data. Some -- such as how to reclaim storage, or "collect garbage" -- are a bit below the language implementation, but are usually described in terms of abstract algorithms at a level considerably higher than machine language or hardware. Some, such as how the user interacts with the system, are at an architectural level even higher than the language itself. Some have to do with deeply-buried details of how the system works, details that might not ordinarily be the least bit visible to a user.
Fortunately, much of my professional work had dealt with architectures explicitly, and many of the sources I had been reading to learn about Lisp focused intensively on one or another specific architectural level. Thus I was nudged into thinking about my nascent design in terms of the different layers of the system architecture -- how would each one work, and how would they communicate with one another. That helped a lot.
At some point I should probably mention that both of my parents were architects -- the kind who design buildings. Maybe that helped with my mind-set. Or maybe the old joke about programmers, woodpeckers, and the destruction of civilization struck a little too close to home.
One reference that was particularly useful was Peter Henderson's Functional Programming Application and Implementation. Henderson's focus was on applicative programming, encompassing the particular meaning (of several that are common for the term) that the value associated with a variable name never changes once it is assigned.
Lisps in general and Scheme in particular are not applicative languages. Notwithstanding, Scheme could reasonably be said to be almost one, in the sense that Scheme -- well, R3 Scheme, at any rate -- differs from a pure applicative language only in having a few well-defined operations -- all the ones that end with a '!' -- that change the values associated with variables.
Furthermore, what Henderson did to illustrate a functional language, was to describe the implementation of a small Lisp-like functional language based on the machine language of a particular kind of virtual Lisp machine -- an imaginary CPU -- called an SECD machine. Before I go into the details of what all that is about, let me state clearly the major point that sank home from this illustration:
Thus, getting a bit ahead of myself, the broad structure of my clever plan was to:
An SECD machine is a relatively simple construct that sounds a lot like the kind of toy-like CPUs that many of us studied during our introduction to computer hardware. S, E, C, and D are registers in the virtual hardware, each pointing to a push-down stack or list in the virtual machine's memory. The letters stand respectively for Stack, Environment, Continuation, and Dump.
The Stack is not a function-call stack, it is the kind of stack for arithmetic calculations that you encounter in Forth or in an RPN calculator. Thus, if you want to add A and B, the code for the virtual machine looks like this:
PUSH A PUSH B ADD
whereupon the sum of A and B is left on top of the stack.
The Environment register points to some kind of data structure for use in looking up the values bound to variables. In a lexically scoped language, such as Scheme, it might point to a big list that was the concatenation of all the environments from innermost out to top level, or perhaps it would point to a list of those environments, depending on the implementation.
The Continuation is perhaps best thought of as "where the program counter points". It represents an instruction stream, typically what is required to finish the function currently being processed.
The Dump corresponds more or less to a function-call stack: When you call a function, you wrap the current Stack, Environment, and Continuation up in a package of some sort -- typically a list -- and push it onto the Dump. When the called function returns, you pop the Dump and restore those registers from what you get. Note in particular that every function application can have its own Environment in which to evaluate variables, and that on the occasion of a tail-recursive function call, you do not strictly need to push anything onto the dump at all. Note further that having an empty continuation -- nothing more left to do in the current function -- at the time you call another function, is a sure-fire run-time indicator of a tail-recursive call.
Again getting ahead of myself, it is worth noting that in a Lisp implementation with garbage collection, S, E, C, and D are all "roots" for the traverse to find things that are not garbage. Any substantial implementation will likely have other roots as well.
I indeed first implemented Pixie Scheme -- Wraith Scheme's predecessor -- as an SECD machine, according to the plan a few paragraphs up, with all four registers being pointers to push-down lists in Scheme main memory. That soon changed, however, in the interest of optimization for speed. Rather early in Pixie Scheme's development, I combined S and D into a true stack -- a large block of contiguous memory addresses outside Scheme main memory. I made a special register, R, as an accumulator, to hold the values that might normally go on top of the stack. Furthermore, while still developing Wraith Scheme as a 32-bit application, for similar reasons, I reimplemented the C register as a stack of pointers to executable code primitives instead of using a register pointing at a list of such primitives in Scheme main memory. Both of these stacks must be copied into Scheme main memory when it is necessary to save a continuation for any purpose, and every entry in each stack is itself a root for garbage collection.
When necessary to talk about these different stacks explicitly, I will refer to the combined S/D stack as the "Scheme machine stack", and to the stack that implements the continuation as the "continuation stack".
My SECD machine implementation actually has a number of other registers as well. I shall discuss many of them presently.
Also important was how the implementation identifies the kinds of objects it deals with. This issue spans several architectural layers: At a low operational level, it is undesirable to attempt to dereference anything that is not a valid pointer. Slightly higher up, the Lisp system may need to identify what kinds of objects it encounters in order to perform operations on them correctly and to display them properly, and perhaps to advise the user of errors in their use.
I decided early on that my Scheme implementation ought to have a low-level typing system that was as bullet-proof as I could make it, if only to save me from some of my own programming errors. Using some kind of tag to identify each object was the most powerful and extensible approach I knew of. I expected I was going to need a few bits for the garbage collector and for cdr-coding, and I did not want to have to keep masking off a few bits of pointers and such before I used them, so I implemented all the objects in my system as C structs containing two items.
The first item was the tag, which at the logical level is a set of bits with various meanings, among which is identifying what the second item of the struct is supposed to be. That second item was either a fundamental data element like a 32-bit integer, a 32-bit float, a character, or some other such thing, or else a pointer to something too large to fit in the struct itself. (The current implementation uses 64-bit quantities instead of 32-bit ones.) The fundamental objects are what would be called "rvals" in other programming languages; that is 'r' for "right", meaning things that go on the right side of an assignment operator. Many of my pointers corresponded to "lval"s, on the left side of an assignment operator, which represent addresses at which an rval may be stored, but some were a combination, such as a pointer to a cons cell, which is both a fundamental type and an indication of a place in memory where things may be put.
Since my struct encompassed pointers, data items, and things in between, depending on the tag bits, I coined for it the suggestive name "tagged aval", with the "a" standing for ambiguous, or perhaps for ambidextrous -- something that could be either an rval or an lval. The first line of actual code I wrote for my Scheme implementation was in fact the relevant C typedef:
typedef struct {
Tag t;
void *p;
} taggedAval;
which only becomes completely defined when I add:
typedef unsigned int UnsignedWord; typedef UnsignedWord Tag;
When contemplating those typedefs, it may help to remember:
Thus, I originally had Tag typedef'd only a byte long, but when I realized what the compiler was doing I declared it a full word, in the hope that some day I would find use for the extra bits. (I eventually did, but now I have changed the implementation to use 64-bit words, so I still have vastly more tag bits than I know what to do with.)
Most Wraith Scheme tagged avals are composed of two 64-bit words -- one for the tag and one for the aval, but there is a special kind of tagged aval called a "byte block", whose length may differ. A byte block is composed of a tag of type "byteBlockTag" immediately followed by one or more 64-bit words. The tag and all the words are adjacent in Scheme main memory. The first word past the tag -- the one that would be the aval in a more typical tagged aval -- contains an integer that is the number of 64-bit words, in addition to the tag, that the byte block contains. Thus for example, a byte block composed of five 64-bit words side by side will have a tag as word 0, will have the integer "4" in word 1, and will have words 2, 3, and 4 available to store data.
Tagged avals of type "stringTag" are used to store text strings, and have the same structure as byte blocks. A tagged aval of this type is in essence a byte block by another name.
I certainly wanted a more capable computer than my MPX-16 for my Scheme implementation. Its Intel 8088 processor could address more than the traditional 64 KBytes of memory, but Intel's early implementation of segment registers made it awkward to do so. Fortunately, a serious breakthrough machine had just appeared on the personal computer market, with a flat addressing system for a much larger memory space, and with an expandable hardware system that might actually allow MBytes, or even tens of MBytes, of RAM, for anyone rich enough to afford all those capacious memory chips.
The new computer was Apple's Macintosh II, with an early Motorola 68020 processor and an optional 68881 floating-point coprocessor, and with built-in hard disk options to 80 MByte. Mine came with an entire megabyte of memory, and I soon added four more megabytes. This gargantuan machine could surely handle a Scheme implementation. Stop laughing! Furthermore, Apple showed signs of supporting would-be Macintosh programmers with a serious development environment, Macintosh Programmer's Workshop. It wasn't Unix or TOPS-20, but after all, what could you expect from a PC? I had placed an order for one of these hot new machines as soon as they were announced. In consequence, I never did unpack my MPX-16 after I got settled in Santa Cruz.
The down side of using the Macintosh, of course, was having to cope with the frustrations of Apple's point-and-click graphical user interface (GUI). My computer use has always been heavily text-oriented, and I am a fairly fast typist. It always seemed like a waste of time to move my hands away from the keyboard to mess with a mouse, and when learning a new program it always took me forever to memorize what all the icons and symbols meant. (Even after more than thirty-five years using Mac-like GUIs, I still feel that way.) Furthermore, the programming interface to the Mac GUI was complicated and clumsy to the point of being Byzantine. But if an awkward user interface was the price I had to pay for a powerful machine, so be it; I do not regret being a Macintosh user, interface flaws notwithstanding, and I do acknowledge that my opinions on the subject are a minority viewpoint.
In any case, my decision to buy a Macintosh had a strong influence on the high-level architecture of my Scheme implementation. My dislike of mice and menus and my wariness about the programming interface made me shy away from writing a Mac-style application for as long as I could. That was a long time, because Macintosh Programmer's Workshop offered a way to write programs that used a text-based user interface and ran in something much like a traditional Unix shell. On the other hand, I knew I was probably going to have to bite the bullet eventually, and wrap something Mac-like around my Scheme machine.
Therefore, even while working up a user interface that in essence used stdin and stdout, I had to plan for something quite different in the future. So I wrote my early code with the calls to read and write text carefully encapsulated, to make it easy to substitute something fancier later on. I am not sure that anyone had clearly articulated the model/view/controller style of program design in 1987, but sloth, fear and loathing conspired to coerce me into writing my Scheme implementation in that manner, even without clearly understanding what I was doing.
That program structure paid enormous dividends down the road, when it came time to strip out the calls to the primitive Macintosh Toolbox of 1987 and replace them with an interaction with the much more sophisticated, much more powerful, and much more Byzantine Macintosh GUI of the early twenty-first century. It is quite possible that if I had been stereotypically enamored of the Macintosh Toolbox in 1987, I would have ended up writing a Scheme application so inextricably intertwined with it that it would have been all but impossible to port the code to the very different interface architecture of today.
(I hope no one takes me to task for calling Apple's software Byzantine. After all, it is worth something to have the might and majesty of the entire Byzantine Empire on your side.)
So I guess my advice to programmers who worry about maintaining proficiency and keeping up with the latest technology is, drag your feet and whine a lot. You will probably do just fine.
Henderson's SECD implementation of his virtual machine for functional programming got me used to thinking in terms of primitive operations for that construct; that is, used to thinking in the assembly language of the virtual machine itself. So when implementing that machine in a real programming language, on real hardware, to use as the architectural underpinnings of my Scheme machine, the question came up of how to distinguish the virtual machine level clearly in the code I would be writing.
Looked at in one way, such a distinction is an oxymoron. After all, the code I was writing was all C (later switching to C++), so what difference could it make? My answer was, that to get best use of the virtual machine required me to be able to see clearly when, where and how I was using the abstraction it represented in the code I created. There were no doubt going to be constructs from both higher and lower levels in the program architecture mixed in -- it was indeed all C -- but best practice required me at least to try to keep their use separate and in some sense orthogonal to the virtual machine instructions themselves. To do that well required me to be able to see those latter instructions clearly, at a glance.
My usual C/C++ coding style features identifiers composed mostly of lower-case letters, with either capitalization or underscores used to indicate word breaks, depending on what I had for breakfast that morning. To give the virtual machine assembly language a very different appearance and syntax, I decided to use tokens that were all upper-case, and to implement them as preprocessor macros -- the latter largely to get away as much as possible from superfluous parentheses and semicolons.
For example, the macro to push the contents of the accumulator of my Scheme machine onto the stack -- that is, onto the 'S' of the SECD machine -- is, rather unsurprisingly ...
PUSH
... which the preprocessor expands into ...
( *(--S) = R );
... in which R is the accumulator (which holds a taggedAval), and S is a pointer into a big array of taggedAval that represents the stack. (Yes, there are checks for stack overflow and underflow here and there.)
What I ended up doing with stuff like that was implementing Scheme operations in terms of the virtual machine assembly language. For example, here is how my Scheme implements the Scheme procedure "+". Don't worry for now about how the different macros expand (and I remind you again, that it is all ultimately C or C++), just look at it as a sample of assembly-language programming in a simple machine that uses a run-time stack for arithmetic operations.
/**** addCode -- Add the numbers stacked and return the sum,
except that if there are no numbers, return zero. ****/
PROC( addCode )
ZERO_FIXNUM_P
JUMP_FALSE( oneOrMore )
CONTINUE
oneOrMore:
ONE_FIXNUM_P
JUMP_TRUE( noMore )
EXCHANGE( R, STACK( 1 ) )
ADD
SWAP
DECREMENT_R
JUMP_LABEL( oneOrMore )
noMore:
POP
CONTINUE
END_PROC
The procedure starts out with an arbitrary number of addends pushed on the stack, with the actual number of addends in the accumulator. (I will defer for the moment, discussion of how the system type-checks its arguments, and how the stack and accumulator get set up that way.) It returns the result of all the adds in the accumulator.
Thus if you had entered the Scheme expression "(+ 1 -2 3 456.78e9)", the accumulator would start out containing a tagged aval that represented the exact integer 4 (how many addends there are), and from the top down, the stack would contain tagged avals for 456.78e9, 3, -2, and 1, and then anything else that might have been on it on it before the addends got pushed. I suspect you can see how "addCode" works, at the virtual machine level, without having to know how it expands to C in detail. That is what I intended by setting up the macros for virtual machine assembly language.
To see how good this abstraction is, and how useful, consider: In the thirty-odd years since I wrote "addCode", my Scheme implementation has changed from a pre-ANSI-C program written for a 32-bit architecture, with three numeric data types (32-bit fixnum, 32 and 80-bit flonums), to a C++ program written for a 64-bit architecture, with four entirely different numeric data types (64-bit fixnum, 64-bit flonum, complex (containing two 64-bit numbers), and rational (ditto)). Yet the only change in "addCode" came when I introduced the macro "SWAP" as an abbreviation for "EXCHANGE( R, STACK( 0 ) )". The point is, that even with all those lower-level changes in the last two decades, the virtual machine itself did not change -- or at least, the part that deals with simple stack-based arithmetic operations did not change -- and the representation of Scheme machine operations in terms of simpler primitives of the virtual machine remained constant.
The present source code for Wraith Scheme contains some 10000 lines of virtual-machine assembly-language routines like "addCode", and many of them have been unchanged since the earliest days of Pixie Scheme, in the late 1980s. The relative constancy of this body of code over time has been a great contribution to the maintainability, extensibility, and portability of the implementation.
I spent a fair part of the 1980s and 1990s writing microcode professionally. That experience also contributed to my ideas about the architecture of my Scheme implementation.
Technical Note: "Microcode" is a layer in the software architecture that runs between "machine language" and hardware. A '1' in the binary expression of a microcode instruction typically means that five volts -- or whatever -- gets applied to a particular circuit of the processor during that clock cycle. A '0' grounds the same circuit.
Every machine-language instruction that a microcoded processor encounters causes a corresponding small program of microcode to run, which actually does what the machine language instruction indicates. In that sense, the microcode is the actual "machine language" of the underlying hardware: The microcode is used to implement a virtual machine, which is the machine that an assembly-language programmer or a compiler-writer sees; it is the machine that is described in the assembly-language manual, and the like.
My colleagues used to say of me, "Jay Freeman -- where hardware meets software -- not a pretty sight!" ... and that was on days when they were polite.
Processors do not have to be microcoded, of course, but during that era, many were. I worked on microcode for for an array of custom bit-serial processors that Dick Lyon developed for speech analysis at SPAR, and later for MasPar's highly parallel single-instruction multiple-data (SIMD) machines, the MP-1 and MP-2.
The principle benefits of my microcode experience were that I was no stranger to the idea that there might be yet another layer of software between assembly language and the machine, and that I expected that some of that software might be very complicated. I suspect that many programmers will look at assembly language and think that what has to happen to make any given instruction work is simple -- take the "PUSH" example in my Scheme machine's assembly language, described above. That isn't so. For example, the MasPar machines that I worked on had assembly-language routines for many floating-point operations. I recall that the one for 64-bit square-root took almost 2000 microinstructions to implement. (It was an unrolled loop, with many instructions per bit of the result. The main hardware resources we had to work with were a shift register and a simple, four-bit-wide ALU.)
Or consider "ADD", in the implementation of Scheme's "+" procedure in the previous section. That "assembly language instruction" (repeat one more time, with feeling, "It's all just C!") might have to deal with operands of different sizes or types -- it could be asked to add a fixnum to a float, for example -- and it might not know till it was done what kind of numeric type it had to use to hold the result. Furthermore, it has to deal with Scheme's "exact bit", and with the possibility of nans, infinities, and underflow. That is not all simple.
My Scheme implementation's microcode, of course, is not implemented on hardware. It is probably most sensible to think of it as being implemented "on" C++.
The point was, that my predisposition to consider that microcode might be (a) there and (b) complicated, made it easy to dodge the occasional temptation to introduce complexity at the level of the virtual SECD Machine. I had no objection to using a complicated microcode routine to implement what appeared to be a simple and straightforward assembly-language instruction; I was used to that.
Furthermore, the use of a microcode layer in the architecture factors complexity into separate domains, and thereby makes it more manageable: Architectural layering serves the "KISS" principle (Keep It Simple, Stupid), by separating one big complicated mess into many smaller and simpler ones, with well-defined connections between them. Thus, the virtual-SECD-machine implementation of "+" can use "ADD" when it needs to, without worrying about how it works, and "ADD" can do its job without worrying about how many addends there are left to go and how they got set up on the stack. Thus when all is said and done, the user can write Scheme programs, and use "+" with fair confidence that it will behave as the Rn report specifies.
One further trick about microcode had caught my fancy, and influenced my Scheme implementation. I had read about one of the early Xerox workstations -- I think it was the Dorado, but I do not remember for sure -- that had microcode that could trap to high-level software. That is, when the microcode hit something it could not handle, it could run a routine written in assembler or a compiled language to help out. In the same way that I say, "It's all just C", microcoders who write that style of hardware microcode might say "It's all just electrons".
I used that approach in the code I was writing, regularly. The "microcode" routines often include SECD Machine assembly-language instructions, and some of the "assembler" routines include specific calls to large C/C++ routines that are not wrapped up in all-caps macros.
I frequently use the term "Scheme machine" to refer to the thread of a Wraith Scheme process that is running Wraith Scheme's read/eval/print loop, and to the code that is running there. The Scheme machine is the heart of Wraith Scheme: it is the interpreter that takes text strings with lots of parentheses, and processes Scheme procedures and special forms based on what they contain. You can think of the user interface, whether it is something as simple as stdin/stdout or as fancy as the canonical Macintosh GUI, as merely a collection of support infrastructure for the Scheme machine, to feed it coal and get rid of ashes and exhaust fumes.
I have tried to keep the Scheme machine as independent of the user interface as possible. The idea is to have the interface between those two software components of a Wraith Scheme implementation clearly visible, with the details of each well hidden from the other, both at the programming interface and at program-building time. Doing so is good design practice in its own right, and also facilitates possible future ports of Wraith Scheme to other interface architectures.
The notion of abstracting the Scheme machine away from the rest of the program that uses it has been extremely powerful. As I write these words, this Scheme machine has run on seven different processor hardware architectures, with six different user interfaces. What is more, the same source code has compiled in two different programming languages.
(The processor architectures are Motorola 68XXX with 16-bit word and 24-bit address space, Motorola 68XXX with 32-bit word and 24-bit address space, PowerPC III, Intel x86 32-bit, Intel x86 64-bit, the the ARM-class processor used in the early iPad, and Apple's recent ARM-based proprietary processors ("Apple silicon"). The user interfaces were those of the three different Pixie Schemes, that of Wraith Scheme using the Macintosh GUI, Wraith Scheme with a stdin/stdout user interface, and Wraith Scheme with an ncurses interface. The bit about two different programming languages is stretching a point, but only a little: The original source code was written and compiled in pre-ANSI C, but when I ran it through the GNU C++ compiler it basically compiled straight away, with no fatal errors.)
In my opinion, a major reason why the Wraith Scheme / Pixie Scheme project did not die at birth was that I stumbled on a software development plan that did not require that the whole program get written and start to work before any of it could be tested. An all-at-once approach would likely have resulted in me having to deal with thousands of bugs all at once, long after the time when the faulty code that produced them was fresh in my mind. Projects have failed for such reasons, and smart programmers have turned in their resumes when asked to work on code that was developed that way. I came up with a rather ad-hoc alternative development plan for Pixie Scheme that avoided those pitfalls. In broad terms, the plan was as follows:
LOAD( 2, R ) ;; Put integer 2 in the accumulator, "R". LOAD( 2, B ) ;; Put integer B in the "B" register (which no longer exists). ADD ;; Add B to R, and leave the result in the accumulator. DISPLAY ;; Print out the contents of the accumulator.
That code results in a readable and automatically checkable printout of "4". The point is, it permits testing of Scheme primitive operations without a Lisp-style storage allocator, without a garbage collector, and without any of the mechanisms of a read-eval-print loop.
By this time, I had a large automated regression test suite of tests of Scheme primitives, that all ran in a text shell under control of a simple shell script. I could diff the results against "gold" files to verify that things were still working, and could easily add more tests as I developed new primitives.
I am sure that there were many other possible ways to bring up Pixie Scheme one piece at a time. The point is, that I used one of them! The code did not all have to start working at once, and it was much easier to get it going in small increments.
When it came time to reimplement Pixie Scheme as Wraith Scheme, I used the same general kind of approach. I tried to work out incremental development plans for each major change, and I made sure to keep a substantial suite of automated tests handy, and to run it frequently.
The architecture of Wraith Scheme is complicated. A complete diagram of it would probably have so many pieces that no one would dare to look at it. In this section, I provide a number of different diagrams, with explanations, that emphasize different parts of the program. All of these diagrams and explanations are simpler than reality, but I hope they will help.
A key issue in any Lisp implementation is how it interacts with memory. I do not mean hardware memory, or even the address space of the language in which the implementation is written -- those are at a lower architectural level. This memory -- Scheme main memory -- is the address space of the SECD virtual machine that underlies Wraith Scheme. It is a large area that contains only Lisp objects -- tagged avals, in the case of Wraith Scheme. Other places in that machine may contain tagged avals: The registers of the machine do, as do the stacks that implement 'S' and 'C', but any pointer in any tagged aval must point into Wraith Scheme main memory.
The issue of interacting with memory becomes even more complicated when several separate Wraith Scheme processes interact with memory that is shared between them. So for a start, let's assume that only one Scheme process is running, and ignore the stuff for coordinating between separate Scheme processes.
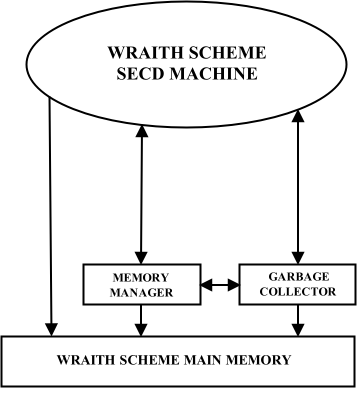
One Wraith Scheme process interacting with Scheme main memory,
using the memory manager and the garbage collector.
In most circumstances, any portion of the Wraith Scheme code may have access to any part of Wraith Scheme main memory, to read or write it, or for any other purpose. That access is represented in the figure by the direct arrow from the oval on top to the wide box at the bottom. The arrow is single-ended because the "memory" is a dumb object -- implemented as a C++ struct comprising a huge block of "flat" memory and a small amount of auxiliary information; it has no procedures of its own, and no way to invoke code in any of the other architectural blocks shown.
There are two exceptions to direct access. The first has to do with allocation of memory. Wraith Scheme main memory is empty when it is first created, at the time when the Wraith Scheme process is initialized. An object called the memory manager -- implemented as a singleton instance of a C++ class -- contains routines to allocate space of any desired size in Wraith Scheme main memory, and return a pointer to it to the caller. The rest of Wraith Scheme allocates memory by using the memory manager as an intermediary. The memory manager also includes procedures to initialize memory, to provide information about it, and to test its contents for consistency and correct form.
The garbage collector -- another singleton instance of a C++ class -- also has substantial responsibilities for dealing with Scheme main memory. Basically, when the memory manager runs out of allocatable memory -- that is, when an allocation request is about to fail for want of memory -- it asks the garbage collector to collect garbage, and attempts the allocation again afterward. (If there still is not enough memory, Wraith Scheme will print an error message and return to the top-level loop.) The garbage collector uses some of the memory manager procedures for its work. Other code may also ask for a garbage collection, even when there is plenty of unallocated memory left.
I should mention that putting the label "Wraith Scheme main memory" on a single block in an architectural diagram is a substantial oversimplification. Wraith Scheme uses a form of garbage collection algorithm that requires two main memory spaces, only one of which is in use at any given time. Furthermore, it uses substantial additional blocks of tagged pointers, and of other memory, for other purposes in memory management and in garbage collection; we will get to those later.
The interaction of Wraith Scheme with main memory becomes much more complicated when more than one Wraith Scheme process (kitten) is involved. There are critical sections to be locked, synchronizations to be achieved, and deadlocks to be avoided. For such purposes, I created an entity called the clowder to mediate and coordinate interprocess communication and interprocess competition for resources. ("Clowder" is a slightly archaic term for a group of cats.)
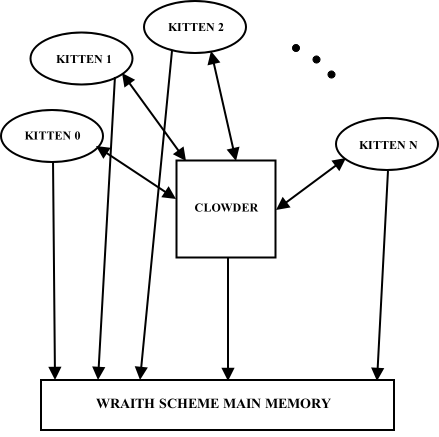
Several Wraith Scheme processes interacting with Scheme main memory,
emphasizing the role of the clowder.
Thus for example, the clowder mediates between simultaneous requests by different kittens to allocate memory by allowing only one to occur at a time, locks access to individual objects in Scheme main memory during critical sections, and schedules and synchronizes the collection of garbage from the separate, private registers and stacks of each kitten.
The clowder does not actually block any Wraith Scheme process's access to Scheme main memory; rather, it deals with simultaneous requests for memory access, or near-simultaneous requests, by granting only one of them. It is up to the kittens -- actually, to the C++ code which implements the Wraith Scheme processes -- to respect those grants and denials of requests for access.
Although the clowder is logically a single separate entity which communicates with Wraith Scheme processes and with Wraith Scheme main memory, its implementation is a bit different.
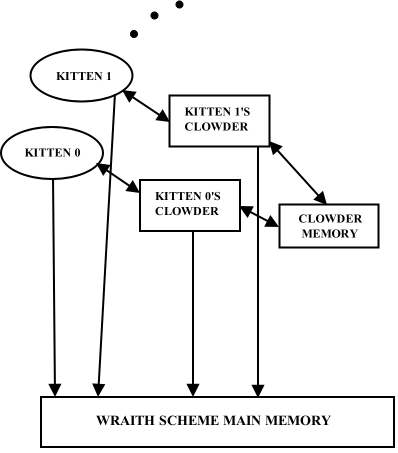
Several Wraith Scheme processes interacting with Scheme main memory,
showing clowder memory and separate clowders.
Each separate Wraith Scheme process -- each kitten -- has as part of the process its own, separate instance of a C++ class called Clowder. Each such instance communicates with clowder memory, with Wraith Scheme main memory, and with its kitten.
Wraith Scheme main memory and clowder memory are created and initialized by kitten 0 -- the MomCat -- which is always the first of a group of parallel Wraith Scheme processes to be launched. These memory regions are group resources -- mmapped -- so that all kittens may access the same content. The other kittens need only be apprised of the location in memory of these regions, in order to use them.
There is an even more detailed view of this part of the architecture that may be useful. Let us now look more closely at just one kitten out of many.
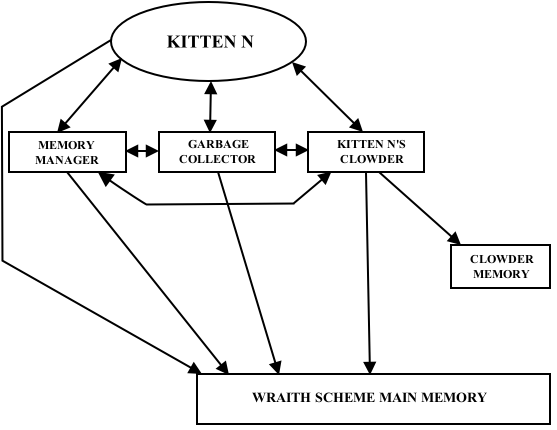
Closeup of one of many Wraith Scheme processes interacting with Scheme main memory,
showing its clowder, memory manager, and garbage collector.
The point of this rather messy picture is to show that the given Wraith Scheme process -- kitten N -- must use its memory manager and garbage collector to interact with Scheme main memory, as before, but with an additional complication: Since that memory is now shared with other, parallel, Wraith Scheme processes, all components of the process shown must use that process's clowder to arrange for locking objects for use in critical sections and for synchronization. Only the clowder's procedures talk directly to the shared clowder memory.
By way of example, if a given Wraith Scheme process wishes to read or write some object in Wraith Scheme main memory, it must first use one of the Clowder procedures to obtain a lock on that memory object. Once the lock is obtained, the Wraith Scheme process does what it needs to with the memory object in question, and then calls another clowder procedure to release the lock. This mechanism is a protocol -- it requires the developer (me) to make sure that the C++ code that implements the Scheme machine makes the proper calls to the Clowder procedures that establish and release locks.
How "typed" things are, and how typing works, varies considerably at different levels in the Wraith Scheme architecture:
Readers familiar with modern object-oriented programming languages will likely be puzzled by the Wraith Scheme source code. They will find lots of situations where I use many copies of certain data structures, with carefully controlled procedural access to their content. That sounds like a good reason to write code using some kind of object, yet I haven't used C++ classes in any of the likely places. What is more, the only places where I did use C++ classes were for a few rather large and clunky things that mostly show up as singletons, which are not usually high on one's list of stuff to implement with classes. What is going on?
Wraith Scheme is written in an object-oriented manner, but most of the code dates from a time when I did not have a suitable object-oriented language to write in. (The GNU folks were working on g++, but it was still pretty buggy, and Apple had not ported it to Macintosh Programmer's Workshop. Apple did have a good object-oriented version of Pascal, but I had a feeling that Pascal's days were numbered.) Thus I dealt with objects in an earlier style. Most of the key objects, that are used widely in Wraith Scheme, were originally implemented as instances of particular kinds of C structs, with access to their content by way of functions whose arguments frequently included a pointer to a specific instance of the struct in question. Some structs contained places for pointers to functions, so that I could write code like
thing->function( arg1, arg2, ... );
This is of course the kind of code that an early implementation of C++, based on macros and preprocessing, would have generated.
I left the original code in this form even after I got hold of a functioning C++ compiler, with no more change than substituting inline functions for macros, and changing a few struct slots to be unions in order to cope with the rather more strict casting rules of C++. There were several reasons why I kept the old code and coding style:
There are some real C++ classes in the Wraith Scheme source code, but as I write these words there are only four of them. There probably should be more. The history here is that I originally used the common practice of encapsulating big blocks of related code in separate files, each with a header that defined the public interface to its functionality. When it came time to upgrade my Scheme implementation from Pixie Scheme to Wraith Scheme, it was appropriate to refactor several of those files, and it was natural to turn them into separate classes at the time. I of course also expect to use classes for new large blocks of related code, but there has only been one of those so far, for the clowder.
There are other, smaller blocks of code in Wraith Scheme which might reasonably also be converted into classes, but I haven't gotten around to doing that yet.
All the "real C++" classes are used only as singletons. (Remember, that means one instance per Wraith Scheme process, but there may be many communicating Wraith Scheme processes active at the same time.) Each is discussed in detail elsewhere herein, but in summary, they are:
That is not to say that the view and controller are vanilla in entirety. They contain some serious weirdnesses, discussed elsewhere in this document. Yet their eccentricities are tidily packed up in a reasonable object-oriented piece of code, with only a few loose ends to hint at what is going on inside.
In brief, I have set up Wraith Scheme's build, test and software-archiving operations to be handled by the Unix "make" utility, with several Makefiles and many make targets. I use "git" for source code control. I invoke Apple's Xcode development system to build the version of Wraith Scheme that has a standard kind of Macintosh user interface, by means of "xcodebuild", launched as a Unix command from within make. (There are also make targets for a couple of other Wraith Scheme versions, that do not involve using Xcode.) For the record, in case you didn't know, "make", "git", "Xcode", and "scodebuild" are programs well known within the Unix or Macintosh developer communities.
There isn't any provision for configuring the Makefiles to run in more than one hardware/software environment; to the best of my knowledge, Wraith Scheme has only been built and run on Macintosh computers so far. There isn't much local configuration to be done when switching from one Mac to another, either. There are, unfortunately, some absolute paths here and there in the tests, but they need to be there. They are used in tests that verify that the Scheme primitives that deal with pathnames handle absolute paths correctly.
On my own computer, the name of the directory containing all of the material for the 64-bit Wraith Scheme project is "WraithScheme.64". The directories within it that developers will need to know about, that I will possibly mention elsewhere in this document, are listed below, with short comments about what is in each one. Anyone wishing to try building or developing Wraith Scheme on his or her own might reasonably be advised to duplicate this directory structure as a starting point.
WraithScheme.64 -- contains the whole project WraithScheme.64/ArmTestResults -- test "gold" files which are different in the arm64 architecture WraithScheme.64/"Auxiliary Directories" WraithScheme.64/"Auxiliary Directories"/CocoaShadowDir -- target for a partial snapshot used in backing up the project WraithScheme.64/CocoaSource -- source and header files for the Objective-C part of Wraith Scheme WraithScheme.64/ExtraTests -- one of several directories containing tests WraithScheme.64/include -- include files for the C++ part of Wraith Scheme WraithScheme.64/SchemeSource -- Scheme code used in Wraith Scheme WraithScheme.64/SchemeSource/Compiler -- Wraith Scheme's simple compiler WraithScheme.64/SchemeSource/TestFolder -- another directory of tests WraithScheme.64/source -- source files for the C++ part of Wraith Scheme WraithScheme.64/Tests -- the main directory for Wraith Scheme tests WraithScheme.64/Tests/TestFolder -- one more directory of tests WraithScheme.64/WraithCocoa -- what Xcode thinks of as the project directory for Wraith Scheme; contains many resources WraithScheme.64/WraithCocoa/ColoredLights -- images used for the blinking lights on the Wraith Scheme Instrument Panel, and for the sense lights WraithScheme.64/WraithCocoa/English.lproj WraithScheme.64/WraithCocoa/English.lproj/SampleSourceCode -- sample programs included in the distribution WraithScheme.64/WraithCocoa/English.lproj/Tutorials -- tutorials to help with learning Wraith Scheme WraithScheme.64/WraithCocoa/English.lproj/"Wraith Scheme Help" -- the main directory for Wraith Scheme's on-line documentation WraithScheme.64/WraithCocoa/English.lproj/"Wraith Scheme Help"/HelpImages -- images used in the Wraith Scheme Help document WraithScheme.64/WraithCocoa/English.lproj/"Wraith Scheme Help"/InternalsImages -- images used in the Wraith Scheme Internals document
There is also a similar directory tree for the Pixie Scheme II project.
"Pixie Scheme II" -- contains the whole project "Pixie Scheme II"/AuxiliaryDirectories "Pixie Scheme II"/AuxiliaryDirectories/CocoaShadowDir -- target for a partial snapshot used in backing up the project "Pixie Scheme II"/English.lproj "Pixie Scheme II"/English.lproj/"Pixie Scheme II Help" -- the main directory for Pixie Scheme II's on-line documentation "Pixie Scheme II"/English.lproj/"Pixie Scheme II Help"/HelpImages -- images used in the Pixie Scheme II Help document
It might also help to know that in my personal file system, the absolute path to the roots of both of these directories "WraithScheme.64" directory is
/Users/JayFreeman/Developer/Scheme/WraithScheme.64
Note also that I use two kinds of "include" files. As a personal convention, I often put C++ "extern" declarations into a file whose suffix is ".e", for inclusion in files where those externs will be needed. There are plenty of ".e" files in the Wraith Scheme "include" directory, in addition to the ".h" files that are more conventionally found in such places.
The reason why there are so many directories containing tests, is that they are required in order to test that the Scheme primitives dealing with path names can deal correctly with relative paths, subdirectories, parallel directories, and so on.
My Wraith Scheme development environment is presently set up to save files via "git". I also take occasional snapshots of the whole directory system, and I use Apple's "Time Machine" backup program as well.
I won't attempt to dictate your choice of a version-control or archiving system, but I do recommend that you use one.
Localization of the environment should consist of no more than renaming some absolute paths. Unfortunately, there are a fair number of them. Fortunately, they are all pretty easy to find, just by grepping for "/Users/JayFreeman", which is the start of the absolute path to the "WraithScheme.64" directory. The full path involved is "/Users/JayFreeman/Developer/Scheme/WraithScheme.64". You will have to replace such absolute paths with whatever is appropriate on your system.
The Makefiles themselves are pretty good about using relative paths, though they do need a couple of absolute ones. For example, the Makefile in the "source" directory uses a rather conventional
WRAITH_SCHEME_DIR = /Users/JayFreeman/Developer/Scheme/WraithScheme.64
The Makefile in the "Tests" directory also has several absolute paths.
Note that the various tests for Wraith Scheme must test that the Scheme primitives that deal with pathnames deal correctly with absolute paths. So both files of test code and "gold" files of test results contain numerous absolute paths. You can find them by cd-ing to the "Tests" directory and then doing, perhaps,
You could probably use a "sed" script to change them all; I myself do things like that with EMacs macros.
By far the most common "make" target that I use is "make tests", in the source directory: That builds and tests three versions of Wraith Scheme. As I write these words, that command takes over five hours to execute on a 2019-model Mac Pro with 12 cores and 192 GByte of RAM. Those times increase enormously on a less powerful machine.
The source Makefile also contains targets that build the various versions of Wraith Scheme separately, and that create new world files for Wraith Scheme to use. For example, the command to build the version of Wraith Scheme that runs in a Terminal window with straight stdin/stdout I/O is
Note that if you wish to use either the TTY implementation or the NCurses implementation of Wraith Scheme, you will need a world for it to use, as described above, and that world will need to be placed in the same directory where your tty or ncurses implementation is, in order for Wraith Scheme to find it.
Furthermore, for reasons that are mostly historical, the only straightforward way to build the standard world, that is packaged as part of the Wraith Scheme application and that is required by all the implementations of Wraith Scheme in order to run properly, is to have a version of the Wraith Scheme TTY implementation handy, and use that in connection with "make new_world_64". For practical purposes, you "cd" to the Wraith Scheme source directory and there type
make ws_tty_64 make new_world_64
As provided by me, the Wraith Scheme source directory contains an assortment of files used by these commands. You can read the Makefile to see what they are.
After "make new_world_64" has run, you will find a new world extant in the source directory. Then, to build the Cocoa implementation of Wraith Scheme, use Xcode, or try the makefile target "make ws_cocoa".
It should go without saying that all these Makefile targets depend on having the directory structure that dangles from "WraithScheme.64" match the structure I described above, with all the expected files in the right place. I think I ought to say it anyway, and what do you know -- I just did.
You may recall that building new versions of Wraith Scheme requires bootstrapping, using previously-expanded versions of macros and some other Scheme source code files, that define much of Wraith Scheme's functionality. The "make tests" command creates new versions of these expanded files, and warns you if they are different from the old versions.
If for some reason you need to make new "official" copies of the expanded macro files -- perhaps you have changed the source code for the macro implementation -- the way to do so is to launch a functioning Wraith Scheme and load into it the file "BootstrapOperations.s", from the SchemeSource directory. There is a Makefile target to do that for you, but I usually do the load by hand, from within Wraith Scheme, and watch the process, just to make sure it goes well.
Be sure to save recent copies of versions of Wraith Scheme that have passed all the tests. If you ever need to make new expanded macro files and do not have both a functioning Wraith Scheme and a functioning world file for it to use, you are in trouble, and a saved copy of the complete Mac-interface Wraith Scheme application has both inside it. Make sure that your saved copies are recent, so that you won't hit the second-order problem of having only an old copy of Wraith Scheme that has somehow been made obsolete by your recent development work. Don't forget to rename them to something else, so that Mac OS doesn't somehow get confused and launch an old copy of Wraith Scheme by mistake.
The command to make a new "curses" version of Wraith Scheme is
The command to make a new "cocoa" version of Wraith Scheme is
Many of the test commands are set up to log results in two files in the test directory, "Test.log" and "Tests.Combined.log". When I am running tests, I usually have terminal windows open where I can "tail -f" one or both of these files, so I can see what is happening.
The various tests generally are set up to feed Wraith Scheme a file of Scheme code to execute, and use Scheme's "transcript" mechanism to log the results to a file. They then compare the test results to a gold file, and show any differences in "Test.log", which is presently copied to "Tests.combined.log".
There are over a million lines of test code in the Wraith Scheme test directory, but don't panic -- most of it was generated by short C or C++ programs, and requires little understanding or maintenance to use. The real problem with this volume of test code is not that there is too much of it, but that there is not enough.
The source Makefile also contains a hodge-podge of short targets, which I put in at one time or another for some convenient reason. I won't describe them all, but for example, there are some to build and run short snippets of code I used when I was suspicious of compiler or library bugs. There are also targets to build the programs that generated most of those millions of lines of test code.
There are a few computer-science concepts, mostly from Lisp, that I must take special care to introduce, not because they are neat in their own right (and I think they are), but because they are necessary to an understanding of how some of the Wraith Scheme code works, and why it works the way it does. I will describe them in this section.
Cdr-coding is a means of economizing memory use and improving locality of reference in the main memory of a Lisp implementation. The basic data structure of Lisp-class languages is actually not a list but a binary tree. Lisp lists tend to be very lopsided binary trees, in which any given node of a tree is much more likely to have a right child than a left child; that is, lisp lists are binary trees that tend to be long to the right and short to the left.
Lisps traditionally implement the nodes of their binary trees as "cons cells". A cons cell comprises two adjacent things in memory, each large enough to contain a pointer. Just exactly what each of those things is varies from implementation to implementation, but in Wraith Scheme, a cons cell comprises two tagged avals side by side.
A cons cell and the two items it contains are collectively called a dotted pair. For example, a cons cell whose first element is 1 and whose second element is 2 would be written in traditional Lisp notation as (1 . 2). Any list may be built from regular cons cells whose first elements are the consecutive elements of the list and whose second elements are pointers to other cons cells. When the second element of a dotted pair is a pointer to a list, then the dot and the parentheses of the list pointed to are omitted in traditional Lisp notation. Thus instead of writing
(1 . (2))the traditional Lisp notation is
(1 2)and instead of writing
(1 . ())we just write
(1)
Note: To remember how this traditional notation is used, first consider the line of poetry by Robert Burns (which I slightly misquote): "If a body meet a body, comin thro' the rye ...". Now transmogrify it slightly: "If the cdr has a cdr, do not print a dot ...".
A list made this way comprises cons cells scattered through memory.
The left part of the cons cell represents the item at a given position
in the list, and the right part contains a pointer to the next cons
cell, and thereby to the next item in the list. For example, here
is a picture of three nodes of a list made up of cons cells so
connected. The items in this part of the list are the letters "CAT".
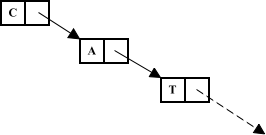
Three items of a list, using traditional cons cells.
Note that there is considerable memory overhead for representing a list this way -- in addition to whatever storage is required for the letters 'C', 'A' and 'T', the list needs storage for three pointers as well. Note also that those cons cells could be a long way apart -- going through the list might well require cache reloads or memory swapping.
The idea of cdr-coding is, wherever possible, to place the consecutive
items of a list in adjacent memory locations, as if they were an
array, and use a few bits per item to keep track of what is going on.
These bits will tell whether the next item of the list is adjacent to
the current one, or whether you have to dereference a pointer to get
to it, or perhaps to advise that the present tagged aval
is not even part of a list at all; that is,
that it is an atom. With as much cdr-coding as possible, a list
containing the letters of "CAT" takes the form shown in the following
picture, with the extra bits shown as little black squares attached to
the objects, just to remind you that they are there.
Three items of a list, using cdr-coding.
The memory overhead for this form of storage is a lot less -- six bits as opposed to three pointers. Furthermore, the list elements are side by side in memory. A section of a list stored in this manner, with the elements adjacent, is said to be cdr-coded.
Lists may be stored using combinations of the two mechanisms.
For example, here is a list of the letters in "CATMEOW", stored
as two separate cdr-coded blocks, connected by one pointer; that is,
the last element of the "CAT" part of the list is in essence
an ordinary cons cell.
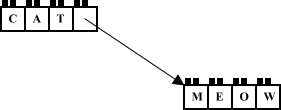
A list with two cdr-coded blocks.
This list might have been constructed as two separate pieces, at different times, with other memory allocated in between, before the two parts were connected. Lists of this kind are quite common.
Wraith Scheme only uses three of the four possible values of the cdr-coding bits in the "tag" portion of tagged avals. The symbols I use, and their meanings, are:
The Wraith Scheme garbage collector is quite careful not to take apart cdr-coded blocks, and where possible it tries to cdr-code things that were not cdr-coded before. For example, it might compact the two cdr-coded blocks in the "CAT"-->"MEOW" list, shown above, into a single block. In order to understand what the garbage collector does, and why, it is necessary to understand cdr-coding. We will get to the garbage collector later herein.
Forwarding pointers can be confusing. There is only one circumstance in routine operation when Wraith Scheme has cause to create a forwarding pointer; namely, when setting the cdr (Scheme procedure "set-cdr!") of a list. There are two reasons why: First, the memory cell containing the car of the list as given may be cdr-coded carCdrNil, in which case there is probably no place to install a new cdr; that is, the memory cell adjacent to the car of the given list is probably already used for something else. Second, if the car of the given list is cdr-coded carCdrNext, we cannot just overwrite the content of the adjacent memory cell (where its current cdr is stored), because for all we know, Wraith Scheme may have stored a pointer to the current cdr somewhere, and changing the cdr should not change what that pointer points to.
The solution in both cases is the same: We cons up (create) two new, unused memory cells, copy the content of the first cell of the given list into the first such cell, cdr-code that cell carCdrNext, put the new cdr into the adjacent new cell, cdr code that cell notCar, and put a forwarding pointer to the first of the two new cells in the place where the original, uncopied car of the list was.
(There is actually a special case. If the new cdr of the list is the empty list, then we can simply re-cdr-code the first cell of the given list to be carCdrNil.)
I said "routine operation" a few paragraphs back because when the Wraith Scheme garbage collector is running, it has occasion to use forwarding pointers to remind itself about things that need to be copied around. I won't discuss those cases here.
Symbols are Scheme objects whose main property is that they have a string of text -- a name -- associated with them, and whose main use is to have values bound to them. Thus when I say, informally, "let frob be 3", what I am doing is creating some kind of association of two Scheme objects -- a symbol whose name is "frob", and the number 3. When I say "let's add a and b", what I mean is, let us look up the value bound to the symbol whose name is "a", and add it to the value bound to the symbol whose name is "b".
What Wraith Scheme calls a symbol is a tagged aval whose tag contains the type code bits for "symbol", and whose aval is a pointer to a short list. The first item in that list is the string that names the symbol, the second is a hash value for that string, and there may be other properties of the symbol stored afterward, as well.
Wraith Scheme adopts a convention used in many Lisp implementations, that there will be only one symbol with any given name. The next few paragraphs explain how that convention is made to work.
When Wraith Scheme binds a value to a symbol, it creates another short list, one of whose items is the value (the value may be a pointer to some larger Scheme object, or just an atomic tagged aval), and another of which is a pointer to the symbol in question. That short list ends up in the environment in which the binding was made. Thus even if there is only one symbol named "frob", there may be many bindings of that symbol to a value -- many pointers to that symbol -- in many different environments. (Just how you look up the value of a symbol in a particular environment, and which environment you ought to be using, is a separate question that I will not discuss right now. The point is, that because pointers to the same symbol may occur in many different environments, there can be many values associated with just one instance of a symbol.)
To make these mechanisms work, Wraith Scheme needs some sort of data structure which holds the unique copies of all the symbols that Wraith Scheme has, and keeps them organized in a way that makes it easy to find whether or not there is already a symbol with a particular name. In the Lisp world, such a data structure is traditionally called an "ObList", which is short for "object list.". Wraith Scheme implements its ObList as a complicated object in Scheme main memory: It is a hash table -- a vector indexed by hash value -- each of whose elements is a list of all symbols in use whose names hash to that particular value. Wraith Scheme's SECD machine has a register called "ObList", whose sole purpose is to store a pointer to that vector.
Yet there is a problem: What does Wraith Scheme's garbage collector do with the ObList? If it considers the ObList register as a root of the search process whereby objects that are not garbage are detected and so marked, then clearly, every symbol that has been used will be declared non-garbage -- they are all in the ObList hash table. That will be true even if a symbol was created for some temporary purpose that has long since been accomplished, and all the code or other data structures that use it are garbage. Putting symbols in a garbage-collected ObList of this kind is thereby a potential "memory leak", in the sense that symbols so stored can never be reclaimed by garbage collection, even when there is no further use for them. This is an important point, because Wraith Scheme's hygienic macro system uses a lot of temporary symbols.
On the other hand, what if Wraith Scheme did not use the ObList register as a root for finding non-garbage? That would be a disaster, because the structure of the ObList hash table would be destroyed! It would start as a big vector of lists, but when it came time to garbage collect, most of the time only some of the items in it would not be found to be non-garbage, so that after garbage collection had finished, all that would remain of the hash table would be a bunch of disjoint pieces.
My solution to this problem is that most of the time, the ObList register is not used as a root for finding non-garbage. The ObList hash table gets rebuilt during garbage collection, with the only symbols in the rebuilt version being those that were discovered not to be garbage in the course of using all the other roots for finding non-garbage.
What was that about "most of the time"? Well, occasionally, Wraith Scheme copies the ObList register somewhere else temporarily, for processing -- perhaps for looking up a symbol. At those times, the situation is too messy to make the trick of rebuilding the ObList hash table work, and the garbage collector throws up its hands and does use the ObList register as a root for finding non-garbage. Fortunately, copying out the ObList register is a well-defined process, so the Wraith Scheme code can set a flag to tell the garbage collector what to do. Furthermore, it doesn't happen very often, so that the ObList hash table is rebuilt, with useless symbols expunged, regularly.
To understand how the Wraith Scheme garbage collector works, it may help to know that the Wraith Scheme memory manager allocates memory starting at the high-address end of Scheme main memory, and working downward. That is, main memory typically looks like this:

Layout of Wraith Scheme main memory.
Lists are often constructed from tail to head. That is, the user creates a list, then conses something onto the front of it, then something more, and so on. One simple example of this process is the Scheme code
(cons 1 (cons 2 (cons 3 '())))
When that code is executed, it first conses 3 to the empty list, creating the list "(3)", then conses 2 onto the head of that list, creating the list "(2 3)", then finally conses 1 onto the front of the whole, creating the list "(1 2 3)". It is not obvious at a glance what the rather simpler list-building code
(list 1 2 3)
does, but in Wraith Scheme, it executes the conses in the same order.
Considering that Wraith Scheme allocates Scheme main memory from high addresses to low, and that cdr-coded blocks have their elements ordered from low address to high, there is an opportunity to create cdr-coded blocks rather than ordinary cons cells whenever lists are being created from tail to head, provided that no other consing is going on at the same time. Let's see how that might work. Suppose Wraith Scheme has to execute the Scheme code
(cons 1 bar)
in which "bar" is a pre-existing list. First suppose that bar was created long ago, so that when it is time to cons 1 onto its head, bar is buried deep within allocated Scheme main memory, like this:

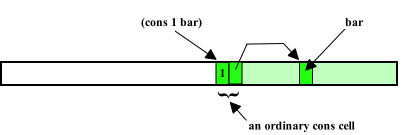


Before "consLuckOutOneTaggedAval" begins to answer the question of whether the passed address is the low end of allocated memory, it locks the memory allocation system, so that if multiple Wraith Scheme processes are running, no other process can sneak in an allocation of its own while the allocator is responding to the query about lucking out. That lock gets released before "consLuckOutOneTaggedAval" returns.
A world file is a stored representation of the entire content of the Lisp main memory of a running Lisp program, in a form that can be reloaded into a different instance of that program than the one from which it was saved. That is, you can save a world, turn off the computer, then later restart it, restart your Lisp program, load in the saved world file, and have all the data structures you had built and functions you had created right there, ready for you to use again.
World files are sort of like the "saved games" of many computer games, of the particular variety in which you can restart any given saved game as often as you like. Furthermore, they are just as useful as saved games at saving your neck if something goes wrong.
World files are also useful for "checkpointing" a long and complicated process. The idea is that if you save a world file regularly, at well-established points in the computation, then if the power goes off or your computer crashes for some other reason, you can go back to the last checkpoint and pick up where you left off: You will not lose all of the work done thus far in the process, only what was done since the last checkpoint.
Wraith Scheme's world files are useful only for saving and restoring the state of Wraith Scheme as seen when the top-level loop is waiting for you to type something. World files in general need not be so limiting; with more work I could have created a mechanism that could save a world file in the middle of the evaluation of an arbitrary Scheme procedure, and that would reload and restart the evaluation right where it had left off. I simply didn't bother to do that.
One thing I did do was create a mechanism to load a world and then automatically start evaluation of a particular function in that world, without the user needing to type anything into the top-level loop. A world file of this kind is in effect a stand-alone Wraith Scheme program, which will start running as soon as it is loaded, and the particular function is analogous to "main" in C or C++. In that situation, the rest of the saved world combines the roles of a big library of procedures to call, and a framework (in the sense of Macintosh programming) in which they run.
(For the record, the function is named "e::main", and it must have no arguments. If that function is defined in a Wraith Scheme environment when a world is saved, it will run automatically when that world is loaded. Only the MomCat will execute "e::main", though that procedure may of course tell any kittens which may be present to do things.)
A Wraith Scheme world can only be loaded into the same version of Wraith Scheme from which it was saved. The Wraith Scheme main memory into which the world is loaded must be large enough to hold the world. There is no requirement that there at least as many Wraith Scheme kittens running as there were when the world was created, but if the loaded world contains code that requires more kittens than are present, then that code will of course not run.
The large chunks of memory shared by Wraith Scheme processes running in parallel are obtained from the operating system by the Unix "mmap" function. This function has been around a long time, but many programmers -- including me -- are not particularly familiar with it. I thought I ought to tell you something about how it is used in Wraith Scheme, but Since I myself am a relative newcomer to the use of "mmap", I must advise you to keep an eyebrow skeptically raised while you read my explanations.
In my opinion, the man pages and on-line documentation for "mmap" are not entirely adequate. Nevertheless, as I understand it, the rules and intent of "mmap", at least for the way I used it in Wraith Scheme, are as follows:
int *myMMappedBlock = (int *)mmap( 0x10000000, 0x50000, <other stuff> );
The "other stuff" includes some mode bits -- "mmap" has lots of mode bits, and I am not even going to think about going there in this document. There is more to the "other stuff", however:
After all that is said and done, all the processes that have mmapped the block can use it like any other big chunk of memory.
There is one rather sneaky aspect of how Wraith Scheme handles the files associated with memory-mapped areas. As part of keeping the user's file system tidy, Wraith Scheme attempts to unlink the files used by the memory manager as well as the files used by the clowder, on two occasions; namely, when Wraith Scheme is making a normal exit, and when Wraith Scheme is just starting up.
The part about "normal exit" is probably unsurprising, but the part about "just starting up" has an interesting consequence: Suppose that one user has somehow gotten two or more entirely different sets of Wraith Scheme processes going; that is that he or she has somehow managed to launch two or more sets of MomCat and kittens. Then, each launch will unlink the memory-mapping files that the others are using and create new files of the same names for itself, but as long as the other processes are still extant, their own memory-mapped files will not disappear, they will remain available for their use. (That is because "unlink" works by decrementing a reference count; the files don't go away till it hits zero.)
Thus one user can in fact operate two or more separate families of Wraith Scheme cats without their memory-mapped areas getting mixed up. I would feel very clever if I had made that happen deliberately, but I did not. It was one of those rare cases in which an unanticipated side effect is not only benign but also beneficial.
The Unix "mmap" function is in my opinion poorly documented and seems to be little used, or at least little understood. Its original purpose seems to have been to direct the operating system to copy an entire file into a contiguous area of a process's address space, so that its contents could be read and written as elements of a big array, or perhaps a big struct, instead of forever having to seek back and forth in the file and use functions like "read" and "write". For many uses of files, such an interface much simplifies and speeds up file access.
When the file is loaded in, the operating system retains the ability to "page out" portions of the file that are little used. In doing so, the operating system uses the file itself as the "swap space" for the paged-out portions.
More than one process can use the same mmapped file. The operating system keeps track of the actual physical address of the file image, maps an appropriate portion of each process's virtual address space to the physical image of the file, and tells the process where it is via the value returned from "mmap" itself. This mechanism is very useful -- perhaps when the file is a big database that is required by several different processes. The processes that use the file have to make sure to use an appropriate protocol that will not get the database mixed up because of near-simultaneous writes and so on, but they would have to do that even if they were accessing the file on hard disc.
When two processes use "mmap" to share memory, they kind of use the function backwards from its original intent. One of the processes creates a scratch file of the appropriate length, and writes it full of zeros (or whatever). Then all of the processes mmap the scratch file to their own address space, wherein it becomes an area of memory that is shared by all processes.
Wraith Scheme has a mechanism to declare that a binding of a symbol to a value is permanent and will not change. The intent of this mechanism is to permit the Wraith Scheme compiler to substitute permanent values of symbols for the symbols themselves, and thereby speed things up at run-time. This mechanism is implemented by the Wraith Scheme enhancement procedure, "e::set-permanent!".
As part of porting Wraith Scheme to the modern Macintosh, I created two versions of it that run in a Unix shell (also known as a Macintosh Terminal application shell) with very simple user interfaces. To understand what these are and why they work the way they do, remember that the most important thing on my mind at the time was getting the Wraith Scheme "Scheme machine" to run in a Unix environment. I needed some sort of user interface to do that, and the Macintosh Toolbox calls left over from Mac OS version 4 -- that's 4, not 10.4 -- sure weren't going to help very much. I also wanted to sharpen up and clarify the programming interface between the Scheme machine and the user interface, and perhaps think a little about keeping Wraith Scheme a terminal application of some sort instead of porting it all the way to the Macintosh GUI, but those considerations were secondary.
The two terminal applications that I developed at that time are still extant, albeit with all their limitations. I build and test them routinely. They might make interesting starting points for ports of Wraith Scheme to other environments. To understand how the different implementations are created from what is substantially one body of code, note that:
USE_TTY_IO
USE_CURSES_IO
USE_COCOA_IO
The first two flags are passed to the compilation via the source Makefile. The third is provided through the "Preprocessor Macros" entry in the "Build" panel for the information window of the "Wraith Scheme" target in the Xcode Wraith Scheme project.
The first, and simplest, of the two terminal-shell versions of Wraith Scheme is the "tty implementation", which I sometimes call the "stdin/stdout" implementation.
Technical Note: The abbreviation "tty" stands for "teletype", which is in essence a typewriter that types onto a long scrolling sheet of paper, that can be controlled remotely, for instance by a computer. By extension, computer programs that type text onto a scrolling window -- like a Unix shell -- are said to use a "tty" interface.
The tty implementation uses C++'s "stdin", "stdout", and "stderr" I/O channels to deal with text input and output. It has a very simple single-character command interface for asynchronous commands, described in"CommandInterface.c++", that is based on a signal handler for SIGINT, which is sent by control-C. It has no buttons and menus, makes no use of the mouse, and does not implement parallel processing.
All functions that are defined in the macOS implementation of Wraith Scheme are present in the tty implementation, but the ones that have to do with the Macintosh version of Wraith Scheme's user interface do not work, they do nothing.
To get the program to see "control-C", you must type a carriage return after typing control-C.
The program responds to the command-tail flag "-h" with a conventional "usage" message.
The tty implementation does not do parallel processing -- there is just the MomCat, with no kittens.
The second of the two terminal-shell versions of Wraith Scheme is the "ncurses implementation".
Technical Note: "ncurses" is an old ASCII-graphics package (and a descendant of an even older ASCII-graphics package called "curses" -- "ncurses" stands for "new curses"), which is designed for terminals in which the primary output is text but there are means to move the cursor around so as to draw text at different places on the screen. Use of ncurses allows a program to create a quasi-graphical user interface by drawing "ASCII graphics" systematically.
The ncurses implementation uses ncurses text input and output functions to deal with text input and output. It has the same very simple single-character command interface for asynchronous commands, based on a signal handler for SIGINT and described in"CommandInterface.c++", that the tty implementation has. It also has no buttons and menus, makes no use of the mouse, and does not implement parallel processing.
The program responds to the command-tail flag "-h" with a conventional "usage" message.
The ncurses package is powerful enough that I could have used it to put ASCII-graphics buttons and pull-down menus in the ncurses implementation of Wraith Scheme. I just didn't get around to doing that.
All functions that are defined in the macOS implementation of Wraith Scheme are present in the ncurses implementation, but the ones that have to do with the Macintosh version of Wraith Scheme's user interface do not work, they do nothing.
The ncurses implementation does not do parallel processing -- there is just the MomCat, with no kittens.
The file structure and build command for the Cocoa version of Wraith Scheme are different from those used in the TTY and NCurses implementations. Files "CocoaIO.c++" and "EventsForCocoa.c++" are used to build the code that runs in the Scheme machine, but instead of the very simple single-character command interface, described in"CommandInterface.c++", a whole bunch of Objective C files are used to build the Macintosh GUI part of the application. Furthermore, the whole application is built in Xcode, using Xcode's ability to work with straight C++ files in addition to Objective C files. I originally wrote an AppleScript application, "BuildScheme.app", which the source Makefile invoked when it needed to built the Cocoa application, but I have since switched to using Xcode more directly.
Each Wraith Scheme process has a memory manager, a singleton instance of C++ class MemoryManager. The memory manager is very straightforward, but cheer up, things will get much more complicated shortly. Its main tasks are the initialization of Scheme main memories and the allocation of space therein. It communicates and coordinates with the clowder, the garbage collector, and the world handler.
The Wraith Scheme processes have several separate "memories", that the manager manages. Two are for Scheme main memory. They are called current space and alternate space, and they are shared between all extant Wraith Scheme processes. The memory manager also handles some shared scratch space used for garbage collection. For convenience, the stacks that implement the "S" and "C" registers of each process's SECD machine are instances of memory space, though most of the MemoryManager methods are not used for them. These latter two stacks are not shared, they are in the private address spaces of their respective processes.
Allocation is straightforward. Normal allocation starts at the high-address end of Scheme main memory and works downward. As an optimization for speed, there are separate routines to allocate several commonly-used amounts of memory. There is also a routine to allocate from the low-address end of memory up, which is used in the copy-across phase of garbage collection.
Tagged avals allocated by the memory manager have both their tag portion and their (adjacent) aval portion 64-bit aligned. Such alignment is required by the 64-bit atomic operations used to lock objects in Scheme main memory, so that a write by one Wraith Scheme process does not interfere with a read or write by another.
The memory managers use a locking mechanism, provided by the clowder, to lock access to shared memory, so that simultaneous allocation requests from different processes do not conflict with one another. the same mechanism is used when checking to see whether cdr-coding is possible, that is, whether the tagged aval currently being allocated is immediately adjacent to a tagged aval it is being consed with.
Much of the complexity in class MemoryManager is in the initialization routines, which must set up shared memory. They use the Unix "mmap" function, with the absolute addresses and sizes of shared memory areas passed to the initialization routine as parameters. These areas are created by a file "MemFill.s", used in building Wraith Scheme: It is an assembler file containing a couple of ".zerofill" directives, that create blocks of shared memory. I pass an appropriate "-segaddr" to the linker via the "Other Linker Flags" entry in the Xcode build rules for target "WraithScheme".
The memory manager uses one trick as a speed enhancement. Each kitten always has access to a piece of Scheme main memory in which it may allocate space for Scheme objects without worrying about any other kitten interfering. This saves time, because without the guarantee of non-interference by others, only one kitten at a time could allocate space in memory: There would have to be a locking mechanism, and managing such locks in parallel processing takes many processor clocks. I call these reserved pieces of memory "allocation caches".
When there is no more room in an allocation cache, the kitten using it gets a new one, and the mechanism for obtaining new allocation caches does indeed require a lock. Fortunately, the cache sizes that I use have space for thousands of Scheme objects, so the locking mechanism is not required very often.
If a kitten needs to allocate more memory than even an empty allocation cache can hold, it uses the locking mechanism and allocates the required space outside of its cache.
When generational garbage collection is in use, allocation caches are created in the active generation. At the start of each generational garbage collection, any unused portion of any allocation cache is declared to be garbage, so that it does not get copied into the aging generation. At the end of that garbage collection, each kitten gets a brand new allocation cache, in the new active generation.
When full garbage collection is in use, there is no need to declare allocation caches to be garbage at the start of garbage collection: Each one is maintained until it runs out of space.
Let's get part of this over right away. The word "clowder" means "a group of cats" -- like a "flock" of birds or a "pod" of whales. You may have gathered that I am rather fond of cats, so when I needed a word to describe the data structures and methods that Wraith Scheme uses to coordinate the activities of a group of parallel Scheme processes -- the MomCat and her kittens -- "clowder" was a natural choice.
Each Wraith Scheme process has a singleton instance of C++ class Clowder, to handle interprocess communication and synchronization. The clowders' duties include:
All clowders share two highly structured pieces of memory, shared by means of the Unix "mmap" function. The first piece of memory, although shared among all Wraith Scheme processes, is considered private to Wraith Scheme in the sense that there is no reason intended for other processes also to memory-map it. It comprises precisely one instance of C++ struct "clowderFileContent", as defined in "Clowder.h", and holds many of the the shared data elements that are required for the purposes just mentioned. It contains:
The second piece of shared memory-mapped memory that the Clowder controls is considered public, in the sense that there is a good reason why other processes might also to memory-map it. It contains the table of interrupt flags used by the Wraith Scheme interrupt system, and also a table of the Unix process identifications for all Wraith Scheme processes. Any process that wishes to use the interrupt system will probably need to memory-map this area.
The mechanism to lock tagged avals in Scheme main memory is fundamental to the operation of Wraith Scheme as a parallel Scheme. Without it, that memory may become corrupted if more than one Wraith Scheme process attempts to modify the same tagged aval at the same time. The locking and unlocking functions touch Scheme main memory, and are called from many locations throughout the code. In order to keep code that has to do with parallel processing in a single place as much as possible, the source code for the functions is contained in two files: File "Clowder.c++" contains pure C++ source code for this purpose, and file "Assembler.c++" contains several C++ functions which have assembly-language statements embedded within them.
Important considerations for the operation of the locking mechanisms include:
The locking code does a variety of administrative things as it runs, but with that stuff glossed over or omitted, the essence of it is the following:
while( locked test-and-set did not get the lock bit
sleep for a short random interval
set the tag-field records of which kitten locked the tag, and of
where in the source code it was locked from.
The unlocking code just clears the record of where the tag was locked from, and clears the lock bit.
The arm64 architecture has the disturbing habit of allowing processors to write data to memory in a different order than the execution of the instructions causing those writes. Thus Wraith Scheme's locking and unlocking code uses memory barriers to ensure that lock bits actually protect the data they are intended to protect.
Technical Note: I am not quite being fair to the arm64 architecture. The reason for allowing out-of-sequence writes is that instruction execution is orders of magnitude faster than memory access: Thus it makes sense to allow the processor great freedom to schedule memory accesses at the most opportune times, even though it does make life difficult for poor people programming parallel process procedures.
To use terms widespread in parallel processing, any attempt by two or more Wraith Scheme processes to access the same object in Wraith Scheme main memory simultaneously constitutes a race condition: The outcome depends on the order in which the different processes achieve access. Wraith Scheme provides no built-in mechanism for guaranteeing the result of a race condition, or for protecting a user's Scheme program from unintended consequences of such a condition, but it does provide -- or at least attempts to provide -- means to keep Wraith Scheme itself from crashing in consequence of a race.
Similarly, the locking operations that Wraith Scheme uses internally, to provide critical-section access to each separate object in Wraith Scheme main memory, are designed not to deadlock: With very rare exceptions (which are carefully studied by me), no Wraith Scheme process holds more than one such lock at a time, and when it obtains such a lock it releases it very soon.
I will now tell a horror story, a tale of two mistakes. The first mistake was that when I first wrote the blocking code, I introduced a subtle bug. (There were actually many bugs, but most of them were not subtle, and thereby were easily found, and thereby are not horror stories.) I was using a library routine for atomic compare and swap of the entire tag (which Apple no longer provides), and instead of writing
thePresentTag = (volatile Tag)(... *pointer ...);
result =
OSAtomicCompareAndSwapLong(
thePresentTag,
(thePresentTag modified)
pointer
);
what I actually wrote was more like
result =
OSAtomicCompareAndSwapLong(
(volatile Tag)(... *pointer ...),
(((volatile Tag)(... *pointer ...)) modified),
pointer
);
Some use of "volatile" is appropriate, because other Wraith Scheme processes might decide to do something to where that pointer points, and without the use of "volatile", a compiler might optimize out all the pointer dereferences in the loop. Notwithstanding, the second piece of code is wrong. As near as I can tell, the generated code dutifully dereferenced the pointer twice in setting up the arguments for OSAtomicCompareAndSwapLong, but once in a very, very, very great while another process altered what the pointer pointed to in between those two dereferences. Thus inconsistent values got passed to OSAtomicCompareAndSwapLong, and disaster occurred.
The second mistake was far worse, and far subtler. When I started working on the locking code, my development machine was a 2006 model Macbook 13, with just two processor cores. Even though I was testing the parallel implementation as thoroughly as I could, sometimes with days of beating on it, my test suite running on the Macbook did not find this bug. It didn't show up at all until shortly after I had bought a new Mac Pro, which had 8 cores with much faster processor and bus speeds. By that time the offending code was months old, and I had made many changes and bug fixes in the meantime, so that it was not simply a matter of backing out recent changes to find out what had caused the problem. In addition, the bug occurred only very infrequently, and depended on the stochastic interaction of complicated asynchronous processes. Thus, it took a lot of thought and testing to chase it down, and there was a lot of code to investigate. It ended up taking three months of pretty much full-time effort to find the problem with the locking mechanism.
Technical Note: Can you say "parallel debugger"? Don't worry, no one else can, either...
Now, the Mac Pro ran my parallel test suite nearly ten times as fast as the Macbook 13, so perhaps the failure of the problem to show earlier was due to bad luck that is statistically highly unlikely. Or perhaps it was a coincidence: Maybe I made some other change to the code, that happened to exacerbate the bug, at about the time I bought my Mac Pro.
On the other hand, consider: Each Wraith Scheme process takes three threads, and even with no other user applications running, the Macintosh has lots of stuff to do by itself. It was probably extremely rare for two threads representing the two Scheme machines of two separate Wraith Scheme processes actually to be running at the same time, on the two cores of my Macbook 13. Furthermore, I have a nagging worry that perhaps the Unix scheduler, that switches processes and makes parallel processing possible on a machine with few cores, may operate in such a way as not to allow this bug to occur. I am not nearly enough of a kernel hacker to know. Yet if the scheduler is not making fine-grained random decisions about when to swap processes in and out, then a machine with only a few cores might be expected to do a very poor job at finding this kind of bug in parallel programs.
In any case, the second mistake may well have been a failure to observe a rule that might artfully be stated as follows:
In a non-parallel Lisp or Scheme implementation, there is no reason why all the pointers contained within the main memory have to point into that same main memory. It may be very useful to store in main memory a pointer to something that lies elsewhere -- perhaps a pointer to the entry point for an executable routine that implements one of the primitive operations, or to a "FILE *" structure, or perhaps to something as simple as a particularly useful numerical constant.
When separate processes share the same main memory, that doesn't work. Each process will have its own copy of the executable routine, or whatever, and there is no guarantee that corresponding copies will have been loaded at the same addresses in their respective address spaces.
Technical Note: If you are not convinced that corresponding copies are likely to end up at different addresses, consider: The process whereby Mac OS launches an application does a great deal of "system" work -- and a great deal of memory allocation -- long before it gets around to dealing with the part of the application that the developer wrote. Are you really willing to bet that that behavior will always be the same, even during consecutive launches of the same application?
Both Pixie Scheme and the original, non-parallel version of Wraith Scheme used such pointers, but only for one purpose. Dereferencing such a pointer was how the Scheme machine learned what compiled C or C++ code to run, in order to execute a Scheme primitive operation, like "+" or "display".
The fix for parallel processing was simple: I arranged it so that Wraith Scheme contains a table of pointers to primitive operations. The order of primitives in that table is fixed, and is under my control, so I can guarantee that any index into the table references the same primitive in all Wraith Scheme processes that are running. So instead of storing a pointers to primitive routines in Scheme main memory, Wraith Scheme stores table indexes, which each Wraith Scheme process can use to look up in its own table of pointers to primitives, with confidence that the code will be correct. For historical reasons, the table of pointers is created and managed by the Wraith Scheme world handler.
What about those "FILE *" pointers? Well, each Wraith Scheme process has a table of all the ports that it has opened. That table is not in Scheme main memory. For each such port, the table stores a pointer to the associated FILE structure, as well as other information. (I have made no attempt to share FILE structures across parallel processes. It can be done, I just haven't done it.)
What is stored in a tagged aval in Scheme main memory that represents a port is both the kitten number of the kitten that opened the associated file, and an index into that kitten's table of ports. Thus any attempt to use a Wraith Scheme port involves a check that the kitten wanting to use the port is the kitten that created it, followed by a table lookup in that kitten's table of ports, based on the stored index.
Wraith Scheme stores no other non-main-memory pointers in Scheme main memory: Such data as strings and numerical values are stored within Scheme main memory, not by pointers to areas outside of Scheme main memory.
Each Wraith Scheme process contains a singleton instance of class WorldHandler, but only the MomCat can save and load Wraith Scheme worlds. Saving and loading worlds is a matter of dealing with a specialized kind of binary file, which contains a modified image of all allocated objects in Wraith Scheme main memory, plus some incidental data. Before every world save, Wraith Scheme does a garbage collection, so the allocated objects will be well-compacted and free of garbage; thus the saved worlds will be small.
The main issues in dealing with world files are:
Dealing with pointers to locations in Scheme main memory is straightforward. In the copy of Scheme main memory that is saved as a file, each pointer is replaced by the offset from the high end of Scheme main memory, of the location to which it points. It is easy to convert back and forth between offsets and actual pointers when saving and loading worlds.
The main issue with version compatibility of worlds is the ever-growing number of Scheme operations that Wraith Scheme provides. Portions of Wraith Scheme are written in Scheme, and are contained within the default world that is loaded whenever Wraith Scheme starts. These portions would not be present if the user happened to load a world created by an earlier version of Wraith Scheme. The loaded world would very likely work, but the user would have inadvertently, and perhaps unknowingly, created a down-rev version of Wraith Scheme by loading such a world.
There is another case, that is worse. A user might attempt to load a world saved by a recent version of Wraith Scheme, into an older version of the Wraith Scheme program. Such a world would not work, because the new primitive operations, that the newer version of Wraith Scheme provided and that the saved world expected, would not be present in the older version of the program.
I have made a design decision not to allow the load of such "mismatched" worlds. That decision is awkwardly enforced: The only criterion is whether the number of Scheme primitives expected by the world is the same as the number provided by the Wraith Scheme implementation into which the world is supposed to be loaded. (Actually, the size of the table of primitive addresses that the world handler builds is what is compared.) That works, because every Wraith Scheme release to date has had more primitives than its predecessor. I should probably get around to doing something more systematic.
The reason the table of pointers to Scheme primitives is created and maintained by the world handler is historical. Before I made Wraith Scheme a parallel system, the Wraith Scheme main memory contained actual pointers to the compiled C++ routines that implement Scheme primitives. The world save and restore mechanism needed to replace those pointers by indexes into a table of pointers, in order to have stored worlds that did not contain any pointers of any kind. As discussed above, when I converted Wraith Scheme into a parallel implementation, I started keeping those table indexes in Scheme main memory at all times, and resolved them at run-time by using the table that had already been set up to be built for use by the previous mechanism for saving and loading worlds.
As I write these words, there is no need for any 64-bit version of Wraith Scheme to deal with big-endian hardware. Those versions all require a Macintosh that runs on either an Intel processor or an ARM-based "Apple silicon" processor, and all those processors are little-endian. Furthermore, all Wraith Scheme saved worlds are little-endian, and have always been so.
Notwithstanding, the 32-bit versions of Wraith Scheme were Universal Binary™, hence could run on both Intel processors and Power PC processors. The latter are big-endian. Any Wraith Scheme world saved by a 32-bit Universal Binary version of Wraith Scheme could load and run on either an Intel processor or a PowerPC processor.
The mechanism to accomplish this feat still exists in the 64-bit version of Wraith Scheme -- just in case it ever turns out to be needed -- but it is untested in any 64-bit implementation. There are a bunch of routines that rearrange the bytes of things, and there is a call to the Macintosh routine "NXGetLocalArchitecture" to figure out what the run-time hardware actually does. The appropriate routines are called when saving or loading worlds from big-endian platforms.
I say again, this mechanism was tested thoroughly, and worked, on the 32-bit Universal Binary versions of Wraith Scheme, but it is not tested on any 64-bit platform. Indeed, as I write these words I have no idea whether the PowerPC architecture swaps the two 32-bit words of a 64-bit quantity, or not. I am not sure that I even want to know.
If you want something to worry about, there are other kinds of byte-ordering than what is commonly meant by "big-endian" and "little-endian". (Does anyone remember the PDP-11?) If you ever want to modify Wraith Scheme so as to be able to load and save Wraith Scheme worlds from one of these other kinds of platform, you are on your own.
Incidentally, as I write these words, Apple is using the term "Universal Binary" to mean something different from what it once did. That term now indicates compiled code that will run on current Macintosh computers with Intel Processors and also on current Macintosh computers with "Apple silicon" processors.
As of Wraith Scheme 2.10, Wraith Scheme has two different garbage collectors, which interact. First, there is a full garbage collector, which can operate entirely on its own, and which is the single garbage collector that was featured in all previous Wraith Scheme releases. Second, there is a new, optional, generational garbage collector, which interacts with the full garbage collector to improve response time at the expense of overall average speed. That is, (1) when the generational garbage collector is running, Wraith Scheme will make large numbers of very brief generational garbage collections instead of small numbers of more time-consuming full garbage collections, and (2) the total time required to complete any given Scheme program, including both the time spent processing and the time spent garbage collecting, will usually be somewhat longer when the generational garbage collector is turned on.
To simplify the description of the two garbage collectors, I will first describe the full garbage collector by itself, and then get on with the description of the generational garbage collector.
When I was first learning Lisp, garbage collectors had the reputation of being slow and disruptive: Lisp machines had a few megabytes of memory, hundreds of megabytes of hard disk space, and processor clock rates of a few megahertz. Lisp main memory sizes often pushed the limits of disk size. Trying to do a stop-and-whatever garbage-collection of that much virtual address space with that little RAM meant that the process swapped to death. The industry had developed all kinds of incremental and generation-counting garbage-collection algorithms to try to reclaim memory a little at a time, without bringing your work flow to a screeching halt. Notwithstanding, smart Lispers would always remember to start a full garbage collection before they left for lunch, before they went home at the close of the day, and especially at the close of business on Friday, for those of us who took weekends off.
It really did take that long. I am not kidding!
Pixie Scheme, as originally written, did not have that problem: It couldn't -- the Macintosh computers of the mid 1980s didn't swap. All of Scheme main memory had to be in RAM. (Those Macs did have the most complicated overlay system in the history of known space, but let's not go there, and if you are new enough to computer science not to know what an overlay system is, you are fortunate indeed.)
With everything in memory, there was no swapping price to pay for multiple passes through Scheme main memory, or for having the garbage collector's working set strewn all over the place, and there are several otherwise useful tricks in garbage collection that do those things. Thus Pixie Scheme ended up with a garbage collector whose design had given no consideration to swapping problems, that ran with everything in RAM, and that did in fact run relatively fast. (Whether you take "relatively fast" to mean that the garbage collector was fast or that the rest of Pixie Scheme was slow, depends on how badly you wish to hurt my feelings.)
When I ported the program to the modern Macintosh, it encountered a true swapping environment for the first time. I did do a considerable rewrite of the garbage collector then, but I did not make any substantial changes or optimizations that would reduce the amount of swapping and thereby speed up the collection of very large Scheme main memories. Thus the present Wraith Scheme garbage collector remains very much a collector best suited to Scheme main memories that are smaller than the amount of installed RAM. It still works when it has to swap a lot, but it slows down more than it would if I had designed it for such environments to begin with.
The terminology of garbage collection is over half a century old. There are so many variations on the original simple algorithms that it can be very misleading to use any of the well-established terms, so I will avoid them. I am going to describe the Wraith Scheme garbage collector by successive approximations, starting with a broad, simple view of how it works when just one Wraith Scheme process is running.
Wraith Scheme uses a stop-and-do-something garbage collector. When there is reason to do any garbage collection at all, Wraith Scheme will halt all normal processing while garbage collection is happening.
The Wraith Scheme garbage collector is a copy-across variety: Wraith Scheme has two blocks of memory of equal size available for use as Scheme main memory, but at any one time, only one such block actually contains Scheme data that are in use. The roles of the two blocks are interchanged during every garbage collection. I generally refer to the one in use as the "current space", and most often refer to the other one as the "alternate space".
What gets copied across is, of course, everything in the current space that is not garbage. A garbage collector that moves non-garbage from where it was to a new location is sometimes called a "scavenger".
Three things trigger Wraith Scheme garbage collection.
The issue with ports is that the underlying C++ code to read and write files and the like uses C++ "FILE *" structures, and as a general rule it isn't safe to assume that a program can get as many of those as it wants. Each Wraith Scheme process limits the number of FILE * structures in use at any one time by using pools of input and output ports to draw on when a new port is needed: Each Wraith Scheme process has a fixed-size pool of "fileDescriptor" structs available for its use, each of which may use a "FILE *" structure if it requires one. There are presently eight input ports and eight output ports, plus a few special-purpose ports. The number "eight" is rather arbitrary, and is easy to change in the source code.
When a new port is needed and none of the right type are available, Wraith Scheme will garbage collect. As part of the process, any open ports that are found to be garbage will be closed, and the associated instance of "fileDescriptor" struct, in the pool, will be marked as available for reuse.
In broadest outline, and omitting many essential details in order to see the large-scale shape more clearly, the Wraith Scheme garbage collection process has three steps:

After the first stage of garbage collection.
Non-garbage in bright green.

After the second stage of garbage collection.
Copied non-garbage in bright green.

After the third stage of garbage collection.
New current space has only non-garbage.
Note carefully that the garbage collection algorithm being described is not "greedy" about copying during the phase when non-garbage is being identified. Many scavenging garbage collection algorithms copy items of non-garbage as soon as they are identified, or perhaps as soon as all of their children have been scanned. The present algorithm does not do that -- it identifies all non-garbage before moving any of it.
The pattern of Lisp objects and pointers thereto in a Lisp main memory is generally a directed cyclic graph with many roots, with each node in the graph having at most two children -- e.g., a cons cell might have two pointers, or a cdr-coded cell implicitly points to its neighbor.
One simple algorithm for identifying non-garbage is depth-first search with coloring, starting at each SECD machine register and each occupied slot in the S and C stacks. The search bottoms out whenever it comes to a node that is an atom, or that is already colored. It marks every node found as non-garbage; the bit that it uses to do so constitutes the "coloring" of the depth-first search algorithm.
Alas, Lisp main memories are usually much larger than typical stack spaces in most programs, so this algorithm is rarely implemented as a simple recursive function call. There are a variety of devious algorithms for storing back pointers to nodes temporarily in the places that had forward pointers, and the like, but I find most of them hard to understand, hard to debug, and hard to adapt to different purposes. I wanted to keep things simple, so I used a couple of Wraith Scheme's multitude of extra tag bits to record which child of a node the directed search was investigating, and used the alternate space to store back pointers.
The extra bits are what I call "recursion bits", and there are two of them. They are globally cleared before each garbage collection, then set and cleared in the course of each depth-first search. One is set whenever a tagged aval is left in the "car direction", that is, whenever the algorithm goes from a tagged aval which contains a pointer to the tagged aval that it points to. The other is set whenever a tagged aval is left in the "cdr direction", which is what happens when the cdr-coding bits indicate that a tagged aval is either part of a traditional cons cell or part of a cdr-coded block, and the algorithm goes from the tagged aval to the one adjacent to it. Both bits are cleared when the algorithm finally backtracks away from a tagged aval, having bottomed out.
Garbage-collection bits, or "gc bits" for short, are cleared globally before each garbage collection. Wraith Scheme actually uses two such bits, but only one matters for this particular subsection. The algorithm sets a tagged aval's gc bit the first time it sees that tagged aval. The algorithm bottoms out either when there is no place to go -- it has come to a tagged aval from which there is no place to go in either the "car direction" or the "cdr direction" -- or when it is about to go to a tagged aval that already has its gc bit set.
To see how using the alternate space to store back pointers works, consider the following. Let C be the address of the low end of the current space, and A be the address of the low end of the alternate space. Those are global constants. Now, suppose we are working with a particular location in current space; that is, we have a pointer to a particular tagged aval in current space. Let the value of that pointer be X. Now we can always do pointer arithmetic (making sure we have cast all pointers to the same type, of course), and consider the offset S of X from the start of current space, and write:
X = C + S
We solve that for S, and then then we can use the location at the same offset in alternate space, at actual address
X' = A + S
to store anything we like that is no bigger than the size of a tagged aval.
The algorithm to find non-garbage is iterative, and it is called many times, starting from each of the root locations for the search for non-garbage. There are a few initialization steps: When it starts, it must immediately check whether the given root contains an atom, in which case there is nothing to be done, or if not, whether the storage location in Scheme main memory to which it points has already been discovered to be non-garbage (e.g., by searching from a previously-investigated root), in which case there is also nothing to be done.
Then the algorithm enters a loop. At the start of each pass through the loop, the code has either started investigating a brand new tagged aval, that it has never seen before, or is investigating one that it has previously seen but whose state is now different -- one or both of the recursion bits have been set. The major variables that the code keeps track of are (1) a pointer to the tagged aval being investigated, (2) a pointer to the last one investigated, (3) a pointer to the next one that is being considered for investigation, and (4) a pointer to the location in the alternate memory space that is at the same offset from the low end of that space as the tagged aval being investigated is from the low end of the current memory space.
The code simply checks the values of the two recursion bits, and does what is appropriate. There are four combinations of values:
This code also does some administrative work as an aid to debugging. It keeps track of whether the number of tagged avals entered in the cdr direction is the same as the number exited, and it returns the total number of non-garbage tagged avals found so that the garbage collector can notice if it has somehow missed some garbage in subsequent processing.
One concern with using the alternate space as a scratch area might be poor locality of reference, with consequent speed loss due to swapping or cache misses. Indeed, any algorithm that stores its working set haphazardly is likely to cause page faults and cache misses. (Note in passing, that one of the virtues of storing things on a stack is improved locality of reference.) Notwithstanding, there is a saving throw: When the present algorithm cdrs up and down a list, and that list is cdr-coded, the list itself will be in a very local area of memory, and furthermore, the associated back pointers stored in the alternate space will also be in a local area of memory, though a different one. Many caching and paging systems will be able to take almost as much advantage of a working set contained in two compact regions of memory, as of a working set contained in just one such region. Lists are generally long in the cdr direction but short in the car direction, and Wraith Scheme does use cdr-coding, so that situation is often present.
The copying of non-garbage from the current space into the alternate space takes place during several sweeps through all of current space, from low addresses to high ones. Furthermore, successive items are copied to destinations that start at the low-address end of the alternate space, instead of allocating from the high end downward, as in normal memory allocation. There are several reasons for doing the copy this way. The two most important ones are first, to not take cdr-coded blocks apart, and second, to combine small cdr-coded blocks into larger ones when possible.
To see how a cdr-coded block might get taken apart, suppose there were a completely cdr-coded list named "C" in memory, with two named sublists "A" and "B" contained wholly within it, and that all of A, B, and C were not garbage. The following figure illustrates what the structure of list "C" might look like in that case. As illustrated, list B is identical to about the last 60 percent of list C, and list A is identical to about the last 30 percent of C. List A is also approximately the last half of B.
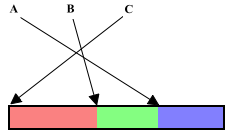
A cdr-coded block with three pointers into it,
before garbage collection.
Now suppose that we were using a "greedy" copy algorithm, that copied non-garbage as soon as it found it, and that it happened to come across the three list pointers "A", "B", and "C" in that order. First it would copy "A", and that would be fine. The small cdr-coded block that is colored blue in the figure would be copied over all at once. Then it would encounter "B", and copy the cdr-coded block that is colored green in the figure, but at the end of the green block it would have to put in a forwarding pointer to the start of the blue block, so that "B" would contain the portion of list structure that it shares with "A". Then it would encounter "C", and copy the red cdr-coded block, but would have to append a forwarding pointer to the start of the green block. All this is shown in the figure below.
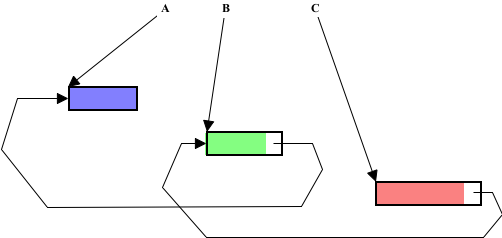
A cdr-coded block with three pointers into it,
after an inauspicious garbage collection.
Do you see what has happened? The original cdr-coded block has been taken apart by garbage collection, into three separate cdr-coded blocks, with forwarding pointers connecting them. The amount of memory space required to store the overlapping lists A, B, and C, is larger after garbage collection than it was before.
It should also be clear, that a garbage collector that copies greedily, and that dealt with cdr-coded blocks in this way, might result in Scheme main memory being larger after garbage collection than before it. That could happen if there were not much actual garbage to begin with, and if many cdr-coded blocks were taken apart as just shown. The garbage collector might even fail completely -- it might end up trying to use more memory as the destination for its copying than the alternate space had available. Such an uncompacting garbage collector would be a serious contender against the celebrated pessimizing compiler, for the award for the silliest piece of system software ever written.
I will leave it as an exercise for you, to determine just how it was that I became aware of the possibility of an uncompacting garbage collector. Please don't tell anyone else when you have figured it out.
I will develop the algorithm for how Wraith Scheme actually does copy-across, one step at a time. First, recall that copy-across uses sweeps of current space from low memory to high -- from left to right, in the figures that follow. These sweeps occur after non-garbage has been marked. In such a sweep, there is no way that the algorithm can jump into the middle of a non-garbage cdr-coded block; it must encounter the block at its "car" end, which is the one at low memory, or on the left in the following figures.
That idea alone is sufficient to make sure that garbage collection does not take apart any cdr-coded blocks, but there is more. Consider a list composed of several cdr-coded blocks linked together, like the one in the following figure. That list consists of three cdr-coded blocks. Each of the first two ends in a traditional cons cell whose second item is a forwarding pointer to the start of the next block.

A list comprising three cdr-coded blocks,
before garbage collection.
We might consider modifying the algorithm so that when it encounters a series of cdr-coded blocks chained together, like this one, it copies them all into one larger cdr coded block. Since the copy-across goes to destinations at increasing addresses in the alternate space, there is no problem creating the large block: The copy of the second block will adjoin the end of copy of the first block, and the copy of the third block will adjoin the end of the copy of the second block. The result will look like the following figure:
A list comprising three cdr-coded blocks,
after garbage collection.
The copied list is shorter by the size of two "forwarding-pointer" tagged avals, and has more locality of reference than did the original. After the copy of multiple blocks, the "copying" scan of the current space will pick up after the end of the first block copied, and continue. We will be setting a second gc bit in all the copied cells, so the scan will know when it comes to the blocks that have already been copied, and can skip them. Unfortunately, there are now a couple of problems.
The first problem is, what do we do when a forwarding pointer at the end of a cdr-coded block points into the middle of a non-garbage cdr-coded block, rather than to the beginning of one, as shown in the next figure? In this case, if we blindly copy that portion of the second block that is the second portion of the long list, we will be taking apart the second block.

A list comprising two cdr-coded blocks,
which should not be joined.
In this particular case, it is not obvious that taking the second block apart causes any harm -- it looks like we will save a forwarding pointer in one place at the expense of adding one somewhere else. Yet it is not hard to imagine circumstances in which there were lots of pointers into the middle of a cdr-coded block, which would be subdivided into many pieces on copying, and would end up taking much more space after garbage collection than before. We have already seen that that is a no-no.
The fix here is to make an additional pass before we start to do any copying at all, and use another one of all those tag bits to mark the starting points of non-garbage cdr-coded blocks. The algorithm used in the extra pass is a little state machine, like the kind used in compilers to keep track of where strings or comments start and end, only we are concerned about where cdr-coded blocks start and end. Every time the extra pass encounters the start of a cdr-coded block, it sets the special bit in the tag, so that the algorithm to copy chained-together cdr-coded blocks can tell whether forwarding pointers point to the start of a block or to the middle of one.
The second problem is, what happens if the blocks are chained together in the wrong order? In the next figure, we have a two-block list in which the second block of the list is at a lower memory position than the first one. The copying algorithm just described will copy the low-address block -- the green end portion of the list -- then, somewhat later, will copy the starting portion, and will have to keep the traditional cons cell at the end of the starting portion. It looks as if there is no way ever to compact the list.

A list comprising two cdr-coded blocks,
which won't get joined without a little more work.
The fix here is randomness. Instead of one "copy-across" sweep, we will make two. In the first sweep, every time we see the start of a cdr-coded block, we will use a randomly distributed probability distribution to decide whether to copy it across then or not. In the second sweep, we will pick up all the cdr-coded blocks that we missed on the first one.
In the example just given, if we randomly happen to copy the low-memory block first, then the list will not be compacted. We will either also randomly happen to copy the high-memory block the first time we see it, or will get it for sure on the second pass, but in either case the two blocks will still be separated, and linked by a forwarding pointer, after all copying is done.
If we randomly happen not to copy both blocks during the first sweep, then we also do not compact the list -- we will then end up copying both blocks during the second sweep, and we will see the low-memory block first.
The case that makes the difference is if we randomly do not copy the first block during the first sweep, but we do copy the second block then. When we do that, the part of the algorithm that copies all linked blocks whenever possible will take over; it will copy the first block immediately after reaching the end of the second block, and will compact the two together in the alternate space.
The point of this algorithm is that memory compaction of this kind does not need to take place all at once; that is, all in a single garbage collection. Eventually, as many different garbage collections take place, the dice will roll in just the right way to join together any pair of cdr-coded blocks that are chain-linked end to end. Using a random process to perform the compaction saves worrying about an enormously complicated, and probably slow, algorithm to do maximal compaction in a single garbage collection.
Note that the randomization does not have to be particularly good for this mechanism to work. What Wraith Scheme actually does is a speed hack to save the time of repeated calls to "rand" or "random": At the start of each garbage collection, Wraith Scheme makes one call to "random", and circularly shifts the resulting integer, one bit at a time, every time during the first "copy-across" pass that it sees a cdr-coded block. It uses the least-significant bit of the shifted integer to decide whether or not to copy the block in question. Thus the probability distribution is 50/50, and cdr-coded blocks 32 apart will get treated the same way (since "random" returns a 32-bit quantity).
Just what probability distribution is best depends on the probability that blocks are connected in the "wrong" direction, but 50/50 is not bad and works satisfactorily. I am sure that it is possible to construct a pathological case involving cdr-coded lists with blocks interleaved 32 apart, such that no amount of garbage collection will ever join up separated blocks, but it is not very likely to occur in practice, and remember that cdr-coding optimally is, after all, an optimization -- the garbage collector will collect garbage quite reasonably even if no joining of blocks takes place at all.
The algorithm for copying across has another valuable feature: It tends to preserve locality. Non-garbage objects that were close together in the old current space, before garbage collection, will tend to be close together in the new current space, after garbage collection. The compaction of many linked short cdr-coded blocks into fewer long ones complicates the matter, of course.
Locality is preserved because of a property of the first copying sweep that I did not mention during the preceding discussion of compacting cdr-coded blocks. In addition to randomly copying some of the cdr-coded blocks, that first sweep also copies all non-garbage objects that it finds that are not cdr-coded blocks. Since the sweep starts at the low end of current space and proceeds linearly, it will encounter non-garbage objects which are close in the heap at close intervals in the copying process, and will thereby copy them into close locations in the alternate space.
This part of garbage collection is trivial. It is just a block move, with all pointers into the memory space updated appropriately. The complete set of non-garbage, that has been copied from the (old) current space into the low end of alternate space, gets slid up till it is touching the high end of alternate space. Thus, after swapping the roles of current space and alternate space at the end of garbage collection, further allocation can take place in the (new) current space in the usual way, in which the low end of allocated Scheme main memory grows toward ever-lower addresses.
In principle, this is straightforward, but it has to be done correctly. Important points include the following:
There are such pointers because of circumstances like the following: Consider a non-garbage tagged aval, of type "pointer to list". When it was in the current space, before being copied, it contained a pointer to the car of the list, which was a tagged aval that was also located in the current space. When the tagged aval of type "pointer to list" is copied into the alternate space, the numerical value of the pointer that it contains does not change; that pointer still points back into the (old) current space, to where the car of the list is (or was, before it itself got copied). It might look like this:
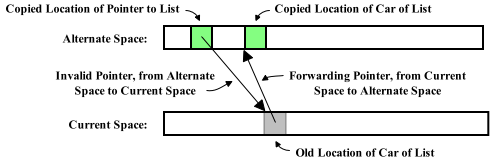
A forwarding pointer that needs to be spliced out.
The fix here is a pass through alternate space after the completion of the "copy-across" phase, that examines every pointer in alternate space, and "splices out" every pointer into the old current space that it finds. That is, every such pointer presumably points to the previous location of some tagged aval that was itself not garbage and so has by then been copied into alternate space. A forwarding pointer to its new location in alternate space has been left behind, in its place. "Splicing out" replaces the value of the invalid pointer, that points from alternate space into old current space, with the value of the forwarding pointer that now is stored at the current space location in question. At that point, the pointer into current space is gone, and the pointer in alternate space looks like this:

The forwarding pointer has been spliced out.
Incidentally, there have been many previous two-space garbage-collection algorithms that use pointers, or pointer chains, that pass back and forth between the two spaces in both directions. One early and well-known one is due to Cheney. (I believe the reference is Cheney, C. J., November 1970, "A Nonrecursive List Compacting Algorithm", in Communications of the ACM 13(11): 677-678.)
As an enhancement, Wraith Scheme has something called "forgettable memory", discussed at great length elsewhere (notably in the Wraith Scheme Help file). In essence, an item of forgettable memory consists of some Wraith Scheme data "inside a box", with things arranged so that at after a certain future time the contents of the box will become garbage, and will be collected, unless something other than the box itself has a non-garbage pointer to the box's contents.
During garbage collection, each item of forgettable memory in use is examined to see whether or not it should be "expired" -- that is, whether it should become garbage because its time has passed. The means for doing so is a pass through all of memory just after the normal process of identifying non-garbage has completed, and before anything has been copied from the current space to the alternate space. After all forgettable memory has been checked to see whether it is about to expire or not, and the pointers from "boxes" to their content marked as non-garbage only if either the content is already marked as non-garbage, or if the forgettable object itself is not due to expire. Then the rest of garbage collection can proceed normally.
Recall that each Wraith Scheme process has only a fixed number of ports available for its use. After all non-garbage has been moved to its final position in the alternate space, ports that have become garbage are closed, and any files associated with them are closed as well. The ports are then returned to the pool of potential ports for possible reuse.
I must be careful about nomenclature here. What Wraith Scheme calls a "port" is a tagged aval of a particular type, which contains a reference (an index into a table) where the actual data about the port may be found. The tagged avals are in Scheme main memory. The table of port information is not in Scheme main memory, it is a C++ data structure that is part of the Wraith Scheme program. It is this latter data structure to which I refer when I mention a "pool of potential ports".
The garbage-collection mechanism here is that all ports in the pool are temporarily marked "not in use"; that is, all entries in the C++ data structure are so marked, using flags in the data structure that are provided for that purpose. Then a pass through the alternate space finds any port tagged avals that are present; they are not garbage, because if they were, they would not have gotten copied to the alternate space in the first place. The pool entry for every port tagged aval thus found is marked "in use". Finally, any file associated with each port in the pool that has not been marked "in use", is closed.
After all non-garbage has been marked, the garbage collector makes a pass through the current space and, where possible, merges many small adjacent items which are garbage into single large instances of a type of Wraith Scheme tagged aval called a "byte block". You might consider this process to be a form of "bagging garbage".
The principle virtue of a byte block for this purpose, is that it can be arbitrarily long, and its length is embedded in it in a way that is easy to read. Changing many short items of garbage into a single long byte block allows the subsequent passes through the current space to be much faster: They can skip huge byte blocks that are garbage in one jump, rather than deal separately with all the individual small pieces of garbage of which the byte block was originally composed.
The garbage collector makes several other passes through the current space even when only a single Wraith Scheme process is running. Furthermore, as we shall soon see, it makes many more such passes when several Wraith Scheme processes are operating in parallel.
In fact, as a speed hack, I have combined the "bagging garbage" pass with the first other pass through the current space that takes place after non-garbage has been identified. Furthermore, the first such pass when just a single Wraith Scheme process is running is different from the first such pass when many kittens are active: Objects in Wraith Scheme main memory are not locked when only one Wraith Scheme process is running, so the garbage-collection passes that count memory locks may be omitted in that case. In any case, the C++ function names "markNonGarbageCCNBlocksInSpaceAndMergeGarbage" and "countNonGarbageLocksAndMergeGarbage" should be sufficient to indicate what is going on.
After moving all the non-garbage to the high-address end of the alternate space, there are a few assorted additional compaction and cleanup tasks to be done. Each takes a separate pass through the alternate space.
The compactions have to do with tidying up the ends of lists into the most compact form allowed by cdr-coding. First, every instance of a forwarding pointer that is cdr-coded car-cdr-nil, that points to an instance of the empty list that is cdr-coded not-car, is replaced by an empty list that is cdr-coded car-cdr-nil. Second, every instance of a tagged aval that is cdr-coded car-cdr-next and has the next tagged aval an empty list that is cdr-coded not-car, has its cdr code changed to car-cdr-nil. Both of these compactions will create a little garbage in the alternate space, but the next garbage collection will of course clean that up.
The cleanup has to do with making sure all the bits used in garbage collection are correctly set for resuming normal operation of Wraith Scheme.
I have written a GarbageCollector method called "checkSpace" that does a lot of consistency testing of the space it is asked to investigate. This procedure may change from time to time, depending on what I am worried about, so I am not going to document it in detail here. I will also not tell you just where it is called, because I have set up the garbage collector at various times to call it in various places, depending once again on what I am worried about. The source code for the garbage collector has several such calls #ifdef'd out.
The garbage collector also has some other internal consistency checks built in. For example, the total number of non-garbage objects found during the depth-first recursion algorithm is recorded, and compared to the total number of non-garbage objects moved from the current space to the alternate space. If those numbers do not match, there is a problem, and the garbage collector will report it.
Similarly, though I have not yet started talking about how the garbage collector works when there is more than one Wraith Scheme parallel process running, suffice it to say at present that when there are parallel processes running, there are locked objects of various kinds in Scheme main memory. The garbage collector contains code to verify that there are the same number of locked objects after garbage collection as there were before, and to complain if that is not so. (Note that it might be a serious error if a locked object somehow became garbage.)
So far, all the discussion of garbage collection algorithms has been in the context of a single Wraith Scheme process. Yet Wraith Scheme is a parallel Scheme, and there may be many Wraith Scheme processes running at once, all sharing the same Scheme main memory. How does garbage collection work then? There are several problems to be addressed:
Multi-process garbage collection requires the active participation and cooperation of all kittens (including the MomCat). No one kitten can garbage collect all by itself. They all have to stop whatever they are doing and agree that they are ready for the task. When all are set to go, the MomCat takes charge of garbage-collection operations, issuing instructions to various kittens as required but doing the bulk of the work herself. The way that works involves several steps:
It is important to know that calls to "triggerGC" are sprinkled throughout the C++ code of Wraith Scheme, in sufficiently many places that every kitten will encounter them frequently. Thus when one kitten requests garbage collections, all the other kittens will shortly discover that garbage collection has been requested, and will be executing code called from "triggerGC" to make one happen. Near the start of the section on Wraith Scheme Events, I describe how the Wraith Scheme scheme machine runs a rather inside-out event loop, which includes frequent calls to functions that detect and process events. Function "triggerGC" is one such function.
Failure to put calls to "triggerGC" in all the right places might create a race condition that would end in a deadlock -- garbage collection requested but one or more kittens unaware of the request and thus not cooperating to make it happen, while all the other kittens sit and wait. As far as I know, I have done my job with placing "triggerGC", but knock on wood ...
If the kitten is not the MomCat, it enters a Clowder C++ function called "kittenHandleGCSequenceMessages", in which it simply spins, awaiting directions from the MomCat. The spin loop checks for a message from the MomCat (delivered via a kitten-specific location in Clowder memory), then switches on the type of message received. Each switch case typically involves doing some garbage-collection task and acknowledging the message (via another kitten-specific location in Clowder memory). One particular message from the MomCat indicates that the garbage collection is all done, and the case for that message exits the spin loop, so that "kittenHandleGCSequenceMessages" and then "triggerGC" can return. After "triggerGC" has returned, the kitten continues whatever it was doing when just before it entered "triggerGC".
If the kitten entering "triggerGC" is the MomCat, it has more work to do, and more decisions to make:
There are plenty of chances for parallel processing in Wraith Scheme garbage collection, but I made a design decision not to take full advantage of that opportunity. The garbage collector is complicated and was difficult to debug, and furthermore, the time required for it to operate has never been a large proportion of Wraith Scheme's total wrist-watch run time. So it seemed that I could obtain a more robust and maintainable implementation by allowing one privileged process -- the MomCat, or kitten number zero -- to do most of the work, sequentially, and I did.
There are still things for the other processes to do. They for the most part comprise simple synchronization operations, or moves of data items between the private address spaces of the individual processes and the shared area where the MomCat can get at them.
Each Wraith Scheme process has its own set of roots of the depth-first search process that finds non-garbage, and its own set of file descriptors used by the ports that the particular process has opened. These data items are not in shared memory; how does Wraith Scheme garbage collection deal with them?
For the separate sets of roots, the solution is to do lots of copying. The memory shared by all Wraith Scheme processes includes not only the current space and alternate space, but also some scratch area. Each of the parts of the algorithm involving the roots, that was described in detail above, is performed many times over, by the MomCat. The first time performs the algorithm portion as described above, using the MomCat's own roots. Then, for each additional Wraith Scheme process that is running, that process is instructed to copy its roots into the shared memory area, where the MomCat performs the algorithm portion using the copies. Finally, if the algorithm portion is one that changes the copied roots -- by altering pointers within them -- then the process from whence they came is instructed to copy the roots back, new pointers and all.
For the file descriptors, each process is instructed to go through Scheme main memory in the manner described earlier, looking at just its own ports, and close any files associated with ports that are garbage.
To a certain extent, this means of performing parallel garbage collection substitutes tedium for complexity. The separate parallel processes are certainly capable of carrying out their own depth-first search and related operations, since they can see their own roots and Scheme main memory as well. Yet tedium seemed preferable, when it came to getting a rather unusual garbage collector up and running reliably.
NUMA is an abbreviation for "Non-Uniform Memory Access". It refers to situations in which a particular processor can access one piece of memory faster than another, because of some feature of how the hardware works or of how it is connected together.
In some sense, that is old hat: After all, it takes a lot longer to get at bits on a hard disk than bits in RAM, and cache hits provide faster access than cache misses, and so on. The more current issue is different, though: The problem is, that with many CPUs in a given system, and a whole lot of RAM, hardware designers may be forced to use circuit designs in which the latency and bandwidth between processor and memory chips vary from processor to processor, and from memory chip to memory chip.
I have helped design systems with as many as a quarter of a million processors and a petabyte of memory -- over ten to the fifteenth bytes -- and believe me, stuff like this was an issue. Small computers, like Macintosh computers and other workstations of 2022, are not quite there yet, but I suspect they will be, soon enough.
So I decided to introduce into Wraith Scheme a very rudimentary system to associate specific items of data with specific processors that are likely to use them, and to group those items close together during the copy-across phase of each garbage collection. I did it mostly to keep myself honest, and to force myself to think about the problem: There are no widely available run-time tools that I know of, that might actually place particular blocks of data in memory locations that are particularly easy to access by processors likely to use that data. Yet I think there will be, some time.
The system is simple. Each Wraith Scheme tagged aval has a field in it that shows what processor last "touched" the tagged aval. At present, a tagged aval is touched when it is first allocated, and subsequently whenever it is locked for critical-section access. I made the plausible but not entirely convincing guess that the last process to touch a data item would be the next one that wanted it, and thereby separated the "copy-across" phase of garbage collection into consecutive passes. The first pass copies all the data most recently touched by Wraith Scheme process zero, the next copies data most recently touched by process one, and so on. Thus data recently touched by a given process are close together in the new current space, just after garbage collection.
I should mention that this refinement of the algorithm does not take apart cdr-coded blocks. Even if such a block happens to contain elements most recently touched by different processors, all of it -- the entire, un-separated block -- will be copied across as one entity, and will be a single cdr-coded block in the alternate space.
This refinement does interfere with compaction of cdr-coded lists, however. If two cdr-coded blocks are linked together tail to head, but their first items were most recently touched by different processors, then the two blocks will sometimes end up in different processors' copied areas, with a forwarding pointer connecting them. It depends on whether the last process to touch the first block has a smaller or larger kitten number than the last process to touch the second block.
For example, suppose the first, car-end block in a linked chain of cdr-coded blocks happens to have its first item most recently touched by Wraith Scheme process zero. If so, then that block and all the other blocks chained to it will end up copied into the kitten-zero section of alternate space.
Alternatively, suppose the first block has its first item most recently touched by Wraith Scheme process one, so that the NUMA mechanism considers that it "belongs" to Wraith Scheme process one, but the second block in the chain belongs to kitten zero. Then the first copying pass, the one that creates the kitten-zero section of alternate space, will ignore the first block, but it will copy the second block -- and the whole chain of blocks attached to its end -- into the kitten-zero section of alternate space. The next pass will pick up the first block, since it belongs to kitten one. That pass will copy the first block to the kitten-one section of alternate space, and will leave a forwarding pointer at its end that points into the kitten-zero section of alternate space, where the second block is.
Note that each pass, that creates an area of alternate space populated by entities belonging to a particular Wraith Scheme process, is really composed of two passes. The randomization process described earlier, to help with compacting linked blocks that occur last-block-first in current space, is still in use, and is used separately when creating each such area of alternate space.
I have been using terms like "kitten-one section" in a manner that suggests that there might be C++ code to access, manipulate or describe them. That's not so -- I am just using these terms to describe how non-garbage is moved around in kitten-specific bunches.
I suggest that there are three points you should take away from the preceding discussion of Wraith Scheme garbage collection:
Good luck.
Generational garbage collection is based on the observation -- well known in the Lisp community -- that most Lisp objects are very short-lived: They become garbage soon after they are created. So if there is some way to examine only those objects that are relatively new, a garbage collector can collect a great deal of garbage in a relatively short time. The more often such collections are made, the quicker they will be, because there will be fewer new objects to examine. We speak of consecutive "generations" of objects being created, and the rule of thumb is that a generation does not have to be very old before a large proportion of the objects in it have become garbage.
From the user's viewpoint, the big advantage of generational garbage collection is response time: The individual generational garbage collections are all very brief, so there is little or no perceived delay while the system is garbage collecting. In contrast, with a large main memory in use, the time required for many Lisp systems to do a full garbage collection is often long enough to be a bother -- it used to take hours on a Symbolics 3600.
On the other hand, the total time required for many short garbage collections is often somewhat greater than the time required for a single long one that collects the same amount of garbage, and there is usually some additional overhead for the Lisp system to keep track of newly-created objects. Thus the overall speed of a Lisp system with a generational garbage collector may be slower than the speed of a similar Lisp system that uses only a full garbage collector.
Wraith Scheme's generational garbage collector is optional: There is a check-box in the Wraith Scheme preferences to determine whether it runs or not. (The generational garbage collector cannot be turned off and on while Wraith Scheme is running; it is a launch-time option.) Thus the user can decide for himself or herself, how to make the tradeoff between overall speed and response time.
There is a more to it than the simple picture outlined in the preceding section. The generational garbage collector cannot examine objects too soon, or it will waste time looking at things that are still in use. Furthermore, the system must have some place to put objects that are still not garbage even after a properly-timed garbage collection, so that it will not waste time examining them again and again. There are a number of related ways to approach this issue -- as described for example by Jones and Lins [1996]. Perhaps the best way to explain further is to give an analogy for the specific kind of generational garbage collector that Wraith Scheme uses.
Suppose you have an office with two desks and a big file cabinet. Suppose also that even though things are important when they first come up, they tend to get old fast -- they become garbage soon. So what you do is use one desk, letting stuff pile up on it as you do your job. Every so often it gets too crowded to do any more work, so then you switch to the other desk. Most of what is on it has been sitting long enough that it's garbage, so you throw it away, and what is not garbage you put into the file cabinet for permanent storage. That way you have a clean desk to work on again. You can of course go look at things in the file cabinet or on the old, cluttered desk whenever you need to. Whenever the desk you are working on gets full, you repeat the switch-and-clean routine. The desks are small enough that cleaning one is relatively quick and easy, so you don't get behind on your work when you are doing it. There is no escaping the fact that when the big file cabinet fills up, cleaning it out will be a messy job that will take a long time, and your work will have to wait while you do it, but using the two desks in alternation, as just described, will keep that from happening too often.
Wraith Scheme's generational garbage collector works like that. The two "desks" are called "generations". One is what I call the "active generation" -- it is where new objects are presently being created, or in Lisp terminology, it is where consing is presently taking place. The other desk is the "aging generation" -- it is where objects are left to sit around for a while, with the hope and the expectation that many of them will become garbage before long. The "file cabinet" is what I call "tenured space", with a certain tongue-in-cheekiness toward the worlds of academe: An object that has been moved into tenured space is guaranteed a relatively long lifetime even if it should become worthless -- become garbage -- after it has "gotten tenure".
Wraith Scheme does generational garbage collection whenever it is necessary. It works just like the desks: Whenever active space fills up. so there is no more room there for consing, Wraith Scheme collects garbage in aging space, and moves all the non-garbage left over in aging space into tenured space. Then Wraith Scheme "switches desks": Through the miracle of swapping pointers, the roles of active space and aging space are interchanged after each generational garbage collection. The old aging space is simply emptied out and used as the new active space.
I must hasten to add that the mechanism just described is by no means the only way to do generational garbage collection. There are many other ways, involving different numbers of generations and differing critera for when to move objects from one generation to the next. One might say that there can be many rungs on the ladder that leads to "tenure". Notwithstanding, there seems to be empirical evidence (see Jones and Lins [1996] again) that a simple two-generation system, such as that used by Wraith Scheme, gets most of the advantage that can be had from generational garbage collection. Furthermore -- trust me -- even this relatively simple generational garbage collector was a challenge to implement.
Truth is in the details, of course, and as we shall soon see, most of those details have to do with various forms of bookkeeping and with specialized algorithms for implementing the garbage collector. One detail, however, is visible even at the level of this simple introduction: Suppose there is need to allocate storage for a Wraith Scheme object that is larger than the size of the active generation, such as a large vector. What happens if object simply won't fit, even if the active generation is new and empty? What Wraith Scheme does in such a case is allocate the object in tenured space. That in turn means that if the new object does become garbage shortly, it will not be collected until the next full garbage collection. That's the breaks!
I found it easier to implement the occasional full GCs that are required by the generational garbage collection system, if the active generation, the aging generation, and tenured space were all part of one continuous block of memory. For that reason, when generational garbage collection is in use, the active and aging generations are created as reserved portions of what would otherwise be the complete Scheme main memories of Wraith Scheme. The following figure shows the memory map of one such complete Scheme main memory.

Memory Space Layout for Generational Garbage Collection.
Consider a specific example: Suppose the Wraith Scheme preference for main memory size is set to 20 megabytes. Then the complete long thin rectangle in the preceding figure will have a size of 20 megabytes. Wraith Scheme will reserve two portions of that memory as generations for the generational garbage collector. Thus a smaller amount of memory remains available for tenured space. Suppose for purposes of discussion that the two generations each have size 1 megabyte, so that the tenured space size is 18 megabytes.
Furthermore, the memory allocation system must be a little cautious about how much of tenured space is actually available for allocation: Suppose that a full garbage collection took place in the worst-case situation in which both the active and the aging generation were full, and that nothing in either of those generations, or in tenured space, was garbage. In that case, for the garbage collection to succeed, it would have to start out with tenured space having enough extra room for the entire content of both the active generation and the aging generation. For that reason, in the example, the memory allocator considers the available size of tenured space to be not 18 megabytes, but 16 megabytes. More generally, the size of the available memory in tenured space is taken to be the size of Wraith Scheme main memory minus four times the size of a generation.
Let's watch the major steps in a generational garbage-collection cycle. In the figure immediately below, the active generation is at extreme left, the aging generation is next to it, and the tenured generation takes up the rest of the main memory space. Colored areas indicate memory that is in use. The active generation is a bit more than half full, and there is plenty of room in tenured space.
Generational GC: Active generation not yet full.
At the stage shown in the next figure, the active generation has become full, and in consequence, generational garbage collection must take place. There is plenty of room in tenured space, so that generational garbage collection in fact can take place.
Generational GC: Active generation full, garbage collection required.
In the next figure, the generational garbage collector is running, and has found some objects in the aging generation that are not garbage. Those objects are shown in dark blue.
Generational GC: Non-garbage (dark blue) found in aging generation.
In the final figure of this series, the non-garbage objects that were in the aging generation have been copied into tenured space, where they are shown as dark green. What used to be the aging generation is now empty, and has become the new active generation, in which subsequent allocations will take place. The old active generation has been set aside to age -- it is now the aging generation. There is still plenty of room in tenured space, but when tenured space gets full, the system will have to do a full garbage collection to see if it can make more room there.
Generational GC: Non-garbage (dark green) moved to tenured space,
old aging generation has been cleared and made the new active
generation, old active generation is now aging.
Since Wraith Scheme has at its heart a register-based virtual Scheme machine, there is a natural and obvious way to identify what objects are or are not garbage: The Scheme machine can only access main-memory objects that it can reach from its registers; either they are either directly pointed to by some register, or are at the end of some kind of chain of pointers that started in a register. There is a slight complication, because the Scheme machine also includes two stacks -- one like the regular call/operation stack of C++ and one that corresponds to the "C" register of the SECD machine upon which Wraith Scheme is based, but in effect those stacks are stacks of registers, so the idea is still the same.
In garbage-collection systems, the places from which the chasing-down of pointer chains must begin are often called roots. That term is used both for registers and for other kinds of pointer-chain start points that are used in other kinds of Lisp implementations.
The Wraith Scheme full garbage collector identifies garbage in precisely this way. It follows pointer chains from each register, including everything in each of the stacks, and marks everything in Scheme main memory that it finds. When the process is finished, anything that remains unmarked is garbage.
When it comes to generational garbage collection, there is a problem. Generational garbage collection is supposed to run fast because it only needs to garbage-collect newly-created objects. Unhappily, the process of following pointers from the Scheme machine registers may have us repeatedly wandering back and forth through all of tenured space in order to find out what pointer chains end in the generations, and that kind of wandering is slow.
The fix is to keep a record of pointers that go from tenured space to the generations. That record -- I am avoiding the term "list" because it may not be implemented as a list -- comprises a set of additional roots for the mark-non-garbage phase of generational garbage collection. The way it works is, we go through each element of our grand unified collection of roots in turn, and start tracing pointers from it. We bottom out when we hit a leaf, and we also bottom out whenever we hit tenured space. Bottoming out when we hit tenured space is okay because objects in tenured space "have tenure" -- the generational garbage collector is going to assume that they are not garbage, even if they are. With this mechanism in place, all the tracing of pointer chains that we have to do is in the aging and active generations, and that is quicker, if only because they are small.
Furthermore, it is an empirical fact that there usually are not very many pointers that lead out of tenured space. They typically occur as the result of "set!", "set-car!", "set-cdr!", or some other operation that changes a binding, and such operations are usually infrequent. Thus their usually won't be many such additions to the set of roots, and we usually won't have far to go when we trace a pointer from one of them.
So how does Wraith Scheme keep track of such pointers? Let me first describe a common method that I did not use. That method involves the use of what is logically an array of bits, one for each address in tenured space. A bit is set to TRUE if that address contains a pointer out of tenured space, and is set to FALSE otherwise. Since addresses in Wraith Scheme 2.0 are 64 bits long, and since tagged avals are at least 128 bit long, the space required for the necessary bits is quite small compared to the space required for all of tenured space.
Sometimes the granularity of the bit array is coarser -- one bit being set to TRUE may tell you that somewhere in a small region of addresses, there are one or more pointers out of tenured space, and you will have to investigate the details separately. For compactness, such logical arrays of bits are usually implemented as arrays of bytes or of some larger data type, with assorted shifting and anding employed to break out specific bits when you need them.
That all works fine, but there are a couple of problems. First, even 1/64 or 1/128 of a 64-GByte main memory is a fair amount of space, and you do have to look through all of it to find the pointers you have taken note of. Second, the bit-twiddling required to convert between bits and the actual addresses that they represent does take time.
Fortunately, a couple of features of Wraith Scheme combine to make possible an alternative solution, which I believe is faster. The alternate solution is to maintain a push-down stack of the actual addresses in tenured space, of pointers that lead out of tenured space. In the typical case in which the number of pointers that lead out of tenured space is very small, that stack will be much smaller than the space required for a table of bits, and furthermore, the literal addresses required will be available without having to do bit manipulation.
There are two problems with such a mechanism: Where do you put the stack, and how do you keep it from overflowing with duplicate entries? These problems are both of the kind that probably only crop up in contrived, worst-case scenarios, but that doesn't mean we can ignore them.
The "where do you put it" problem has to do with the situation in which the number of pointers that lead out of tenured space is large. It is easy to imagine a contrived program that does nothing but overwrite all the pointers in tenured space that it can, with pointers to some object in the active generation. The pointers might all point to the same location, but the stacking mechanism doesn't know that (and it would take lots of extra, time-consuming operations, to have it find out), so in principle the stack might include all the addresses in tenured space. That situation probably does not occur often in practice, but we might worry about the prospect of having to allocate space for a gargantuan stack, just to allow for the rare cases when we need it.
The "overflow with duplicates" problem is even worse. It is easy to imagine a Lisp program that overwrote the same tenured-space address with a pointer into active space, an arbitrarily large number of times. A naive mechanism for stacking addresses, that blindly pushed every address it was given onto the stack, would soon overflow any finite stack, and a mechanism that searched the stack (or kept it sorted) in order to avoid duplicate entries, would be slow.
By coincidence, Wraith Scheme has features that allow it to get around these two problems. The "where do you put it" problem goes away when we remember that Wraith Scheme uses two main memory spaces for its copy-across full garbage collector. They are both the same size, and the only time when both of them are needed is when doing a full garbage collection. When the generational garbage collector is in use, we can use the "other" main space for the stack, without any conflict. When it becomes necessary to do a full garbage collection, the stacked pointers are not of any particular use anyway, so at that time we can just overwrite any stacks that are in the other space, and use that space for its originally intended purpose.
What is more, Wraith Scheme never creates a Scheme object that is any smaller than twice the size of an address -- the smallest tagged aval that is possible has one eight-byte aval and an eight-byte tag as well. That means that the "other" space has room enough for not just one, but two complete stacks, each of which contains every tagged-aval address in tenured space. And it turns out that there is need for two such stacks, as we shall soon see.
So the availability of the other space gives us plenty of room for our stacks, even in the worst case, provided that we can solve the duplicate-entry problem that might lead to overflow. The solution to that second problem is to remember that Wraith Scheme's tagged avals have an abundance of tag bits, and to use one of them to record the fact that the address of that tagged aval has been pushed onto the stack. All the stacking mechanism has to do is check whether that bit is on, and not push the address in question if it is.
The reason two stacks are useful is as follows: We need an "old" stack, which has valid addresses in it, and a "new" one, that is empty, during generational garbage collection. After the non-garbage in aging space has been copied into tenured space, then the pointers that led from tenured space into aging space are invalid and useless. We don't need them any more. Yet we do still need any left-over existing pointers that lead from tenured space into active space. What Wraith Scheme does at this time is simply go through the old stack looking for addresses whose pointers lead from tenured space to active space, and push just those addresses into the new stack. Then the old stack gets cleared and is ready to become the new stack the next time around.
A more complicated but possibly faster solution would be to have two stacks always in use -- one for each of the two generations. The mechanism to stack addresses would put an address in one stack or the other, depending on where its pointer led. We would clear whatever stack happened to be in use for the current aging generation, after each generational garbage collection. I may yet do that, but I haven't done it as I write these words.
There is one additional speed optimization layered on top of the stack mechanism: Each kitten has its own local cache of addresses to be pushed into the global address stack. When a kitten's cache becomes full, all of the addresses in it are pushed onto the global stack at once. The caches are also flushed at the start of each generational garbage collection. Using caches this way avoids the time spent in memory locking operations, and in contention for access to the global stack itself, that would obtain if new addresses to be stacked were pushed onto the global stack one at a time.
As I write these words, each local cache is large enough to contain 16384 addresses. That size is large enough so that in my standard suite of regression tests, the caches never fill up in between generational garbage collections; cache-flush operations only occur at the start of each generational garbage collection. It would be easy to write a pathological Scheme function that rapidly overflowed the local caches, though, so it is still important to have the full, global stack mechanism available in case of need.
The process whereby the generational garbage collector identifies and marks non-garbage is very similar to the process -- already described above -- used by the full garbage collector. The major differences are:
Once the non-garbage in the aging generation has been identified, it must be moved to tenured space. I call this process, "copying down" the non-garbage. I hasten to add that the term "down" has nothing to do with whether the address ranges in question are high or low; it merely reflects that when I started drawing circles on paper to figure out how the algorithm was going to work, I happened to put the circles that represented the active and aging generations closer to the top of the page than the circle that represented tenured space.
Copying down requires knowing beforehand how many bytes of non-garbage are in the aging generation: The copy-down process can thereby figure out how much room below the "free" end of tenured space will be required, and can start adding in the new items there, rather than putting them on the free end one after the other. That order of copying makes it easy to to deal with any cdr-coded lists that happen to be among the non-garbage: In order to make an orderly progress through aging space, the copying process must start at the low end of aging space and work upward, which means that cdr-coded list sections will be encountered car-end-first, so if it is starting to fill a block of tenured space from the low end, it can merely copy each item of a list as it comes to it, without having to be aware of the whole cdr-coded block at once.
The actual copying process is very straightforward -- the literal tagged aval is copied, with a couple of bits turned off in the process. What is left behind, in place of the now-copied tagged aval, is a special kind of forwarding pointer, called a "ggc forwarding pointer", identified by its tag bits, whose sole purpose is to make it easy for later parts of the generational garbage collection algorithm to see that a copy-down has taken place.
Several kinds of updates related to pointers and to addresses which contain them, are required after copying down.
After pointer update, all stacked addresses with pointers that point into active space must be loaded into the address stack for the next round of generational allocation, and the roles of the two generations must be swapped. There are a variety of consistency checks that take place as well -- just which will depend on how paranoid I am when I release the software -- but otherwise, that is it.
The way Wraith Scheme handles events will twist the mind and turn the stomach of even the most grizzled and iron-nerved of Macintosh developers. But wait! I can explain everything! There is a reason why it is that way. Or at least, there is a history...
Long ago, in a Mac OS far, far away (I think it was about OS 4 -- not 10.4, I said 4, and 4 is what I meant), all Macintosh applications were single-threaded and you had to roll your own event loop. I have long since forgotten the precise names of the function calls, but in C-like psuedocode, the canonical Macintosh application of the era looked something like this, and you had to write this code yourself:
while( TRUE ) { // This is the main event loop ...
switch( getNextEvent().getType() ) {
case FOO: doFoo(); break;
case BAR: doBar(); break;
case BAZ: doBaz(); break;
// ...
default: crashAndBurn();
}
}
There would have been events for user-pressed-a-key, user-moved-the-mouse, user-used-a-menu, and so on.
That approach is all well and good for the typical kind of Macintosh application, which -- then as now -- spends most of its time glowering at the user from inside the screen, tapping its fingers impatiently as it waits for him or her to wake up and do something. Yet -- then as now -- that approach doesn't really work for an application that actually has to do some real work from time to time. The problem is, that if one of those "doFoo" functions takes a long time to run, then there will be no way of processing the next event until it has finished. The application will become unresponsive, and the user will have what today we call the spinning-beachball-of-death (SBOD) experience.
(I have often thought that instead of a spinning beachball, the more appropriate icon would be a little apple face that was sticking out its tongue and thumbing its nose at the user. Alas, I doubt that idea would play well in Cupertino.)
One thing to do about that was to abstract the guts of the event loop into a single method, which I will suggestively call "eventLoopOnce", since it represents the event handling in a single pass through the event loop. Once again, in C-like psuedocode:
void eventLoopOnce() {
switch( getNextEvent().getType() ) {
case FOO: doFoo(); break;
case BAR: doBar(); break;
case BAZ: doBaz(); break;
// ...
default: crashAndBurn();
}
}
The idea was to insert calls to this function at many places in the main event loop -- which you still had to write -- with those places being carefully chosen, so that "eventLoopOnce" was called often enough to make the application responsive again. The resulting code might look like this:
while( TRUE ) { // This is still the main event loop ...
eventLoopOnce();
doLotsOfWork();
eventLoopOnce();
doStillMoreWork();
eventLoopOnce();
doWayTooMuchWork(); // Add "eventLoopOnce" calls
// inside this function!
// ...
}
Note in passing, that "eventLoopOnce" does not really contain all of the code that was in the body of the first event loop shown. The "doLotsOfWork" functions would have been part of some of the original "doFoo" functions. The idea was that "eventLoopOnce" should deal with the input side of event handling -- both for events caused by the user and for system events -- and cooperate with data structures and actions elsewhere in the big event loop, so that the the actual work got done properly, in due course.
For example, one kind of event might be a key press of a printable character. In that case, "eventLoopOnce" might cause the corresponding char to be put into a big buffer somewhere, which the "read" portion of the read/eval/print loop could refer to for input, when it was ready to do so.
Some events might not even require interaction with the read/eval/print loop. A change in font size, or in window position or appearance, might well be handled immediately.
Note also, that some of those "doLotsOfWork" functions might have cause to post events themselves. Perhaps a line of output needs to be printed, or a menu item checked or disabled. Code is often more readable and more easily maintained if such requirements are handled by posting events to be handled in the body of a single function at the proper time, rather than by adding many widely separated calls to code that actually accomplishes the actions.
Now if you will imagine that that outer "while" loop has somehow magically been transmogrified into the read/eval/print loop of a Scheme interpreter, you will begin to understand how Pixie Scheme handled events.
Now fast-forward to 2006, when I was beginning to consider a port of Pixie Scheme to the modern Macintosh. When I started reading up on Cocoa and its development tools, it immediately became very clear that Pixie Scheme's way of handing events wasn't going to fit into the new programming paradigm without a lot of work. Cocoa had invaded developer turf, by declaring that it would set up and run the event loop in private, behind the curtain, doing things the way it wanted to, whether you liked it or not. All you got to do was post events and provide handlers for them. That wasn't really going to work, because many of my handlers would need to be those time-consuming "doLotsOfWork" methods of yore. My hypothetical Cocoa/Pixie hybrid would become unresponsive, and present the Spinning Beachball Of Death to the user, while any time-consuming handlers were running.
Of course, Cocoa did provide a way out. Unix applications are threaded, and there was always the possibility of running Pixie Scheme's "Scheme Machine" in a thread of its own, still using all those calls to "eventLoopOnce". Yet something would have to talk to the user, through the Mac GUI. It was likely that "eventLoopOnce" would have to communicate with what Cocoa falsely considered to be the application's real event loop, running in whatever thread or threads the application-launch process set up for it.
There were two downsides to that approach. First, from my professional career, I knew enough about the difficulty of coordinating between asynchronous communicating processes to be scared silly. (In that last sentence, I am using the word "process" with a wider and more general meaning than "Unix process"; I am talking about communication between the Cocoa event loop and the Scheme one.) Second, I was a complete newcomer both to the Cocoa style of event loop and to the POSIX-based tools that Cocoa supported for inter-thread communication; hence I did not immediately know either what to coordinate or how to go about making it happen. This plan looked like a lot of work, and it looked like pretty risky engineering as well.
Since I am both cowardly and lazy, my next thought was of course to wonder if it was really worth bothering with a port to the full-blown Mac GUI. Maybe I should try something with a saner programming paradigm and a simpler user interface, instead. Or maybe that should be "at first", rather than "instead" -- perhaps it would be best to learn something about how to separate the Scheme machine from the user interface in a simpler environment. To do any kind of port of Pixie Scheme, I would in any case have to strip out all its use of the old Macintosh toolbox routines and put some other kind of thing in its place. Using something as simple as I could make it would give me a chance to do three things at the same time:
That sounded like a plan.
My original and primary purpose of bringing a Pixie Scheme port up in a terminal window, using stdin and stdout, was merely to get the Scheme machine running with as little fussing about I/O as possible. Therefore, I created only a rudimentary I/O interface for that implementation, and made little use of Wraith Scheme events. The actual code used is in files "CommandInterface.c++", "Events.c++", and "TTYIO.c++", whose use is by way of the "TTY_SRCS" variable in the "ws_tty_64" target of the WraithScheme source Makefile. There are also a handful of "ifdef USE_TTY_IO"s scattered throughout the source, and that variable is provided via a -D statement in that same Makefile target. (All that is clumsy, particularly the #ifdefs; if there are ever any substantial number of additional Wraith Scheme implementations built, I will want to provide some cleaner way of separating their code.)
The I/O of the TTY implementation is handled in a simple, synchronous manner. The program prints when it has to and waits in "fgets" when it expects input.
Most of the event-handling stuff is simple, too, because most of the events that Wraith Scheme posts from within the "Scheme machine" code have no effect on the TTY implementation: They mostly control displays and text strings in the Macintosh user interface. The "Scheme machine" posts events to itself by calling function "reportEvent" with an enum, and "reportEvent" is one of those functions that is implemented in different files for the different versions of Wraith Scheme. The version for the TTY implementation is in "TTYIO.c++", and it is no more than a big switch on the passed enum, most cases of which do nothing.
The most important of the events that do something is a "CONTROL_C_EVENT". I implemented a very simple signal handler for "sigint", which calls "reportEvent" with a CONTROL_C_EVENT. What "reportEvent" does with that is set a flag that shows that a control-C has been detected, so that "eventLoopOnce" will know to do something appropriate the next time it is called. (Most events that any implementation of Wraith Scheme posts to itself end up setting flags for "eventLoopOnce" to notice later on.)
Recall that there are calls to "eventLoopOnce" sprinkled throughout the Wraith Scheme source code, and that with any luck they are sufficient in number and sufficiently well placed that the program will be responsive. When "eventLoopOnce" notices that a CONTROL_C_EVENT has been posted, it enters a very simple stdin/stdout command interface, in which the user gets to type a one-character command telling the program what to do. The commands do things like quit, reset to top-level loop, and toggle a few mode bits. After the command has run -- unless it was "quit" or "reset" -- "eventLoopOnce" returns, and Wraith Scheme resumes normal processing.
If that were all there were to it, this system would be serious overkill. The events that are enabled are so simple that they could probably all be run synchronously: "reportEvent" could just do whatever action the event indicated, whenever it was called, and there would be no need for the "eventLoopOnce" mechanism at all. The sigint handler could bring up the command processor immediately instead of posting a flag.
Notwithstanding, I used "eventLoopOnce" for two reasons. First, it was already there in Pixie Scheme, and it worked well. Second, as I have said, I was thinking about a possible full-Macintosh-GUI implementation of Wraith Scheme. This mechanism is a valuable simple development exercise for such an implementation. The sigint/eventLoopOnce interaction is an extremely rudimentary example of an asynchronous communication system between a very rudimentary view (the sigint handler and the one-character command interface), controller (the reportEvent/eventLoopOnce duo) and model (the Scheme machine and its own internal event loop).
The NCurses implementation of Wraith Scheme did not add much to the preceding picture. Files "CommandInterface.c++" and "Events.c++" are also used to build it, but "CursesIO.c++" takes the place of "TTYIO.c++". The I/O for the "ncurses" implementation is of course more complicated than for the TTY implementation, but the events to be handled and the handling mechanism are just the same.
When I started the ncurses work, I was thinking that perhaps I would end up not doing a full Macintosh version of Wraith Scheme. Yet Apples' ncurses implementation was a bit broken at that time -- or at least, I could not get parts of it to work -- and it also was rapidly becoming clear that ncurses was perhaps as complicated an interface in its own way as the Mac GUI, without being as powerful or as aesthetically pleasing. So I did not follow the ncurses path very far: I did not use menus or buttons or any of the other similar features that it provided. Eventually, I bit the bullet, fired up Xcode and Interface Builder, and started work on a Cocoa implementation of Wraith Scheme.
The main difference between the Scheme machine event loop in the Cocoa implementation and the ones in the TTY and NCurses implementations is that most events posted actually cause something to happen. The function "reportEvent", in "EventsForCocoa.c++" turns on an appropriate flag for each reported event. The flags are in an array indexed by the enum that represents the event, rather than being separately declared variables. Note that there is no way to have multiple pending events of the same kind -- the corresponding flag is either on or off.
That function also does a bit of immediate, synchronous housekeeping, for particular events. It deals immediately with a globally visible boolean asserting that garbage collection is in progress. It also makes local copies, in static buffers, of the names of files and worlds that have just been loaded; that action is in essence a work-around for the fact that the present "reportEvent" function does not pass any data associated with the event.
That same file also contains "eventLoopOnce", which does the following things:
Function "dealWithEvent" simply encapsulates the various actions which the various events are intended to trigger. As I write these words, all the events that it is prepared to deal with involve transmitting a request for some kind of action to the controller (again, in the sense of the model/view/controller design pattern). That is, something needs to happen involving the Macintosh GUI. I will discuss the details of such interactions in a subsequent section, but the main function that actually transmits the data is "tellController", and it is located in the file "CocoaIO.c++". It is perhaps worth noting at this time, that all the calls to "tellController" are localized in the two "interface" files, "CocoaIO.c++" and "EventsForCocoa.c++"; basically, "CocoaIO.c++" has to do with text I/O and "EventsForCocoa.c++" deals with all other communications sent to the controller.
Function "tellController" is prepared to pass three arguments to the controller. They are an enum indicating what message or event is involved, a long, and a string. Those turn out to be sufficient for all present uses of "tellController".
Here is an example of how "tellController" is used. This is the actual code from "dealWithEvent", for the case that advises the controller that a garbage collection is in progress.
case GC_START_EVENT:
if( evaluatorMessageSenderTurn ) {
tellController( E_GARBAGE_COLLECTING, 0, "" );
eventRegister[ foo ] = FALSE;
}
else
anyEvents = TRUE;
break;
The Cocoa implementation of Wraith Scheme also has a control-C handler -- perhaps more precisely, a sigint handler, since the Mac GUI does not transmit control-C's to programs as an interrupt. At the moment, it merely requests a reset to top-level loop.
I must stress once again that from the point of view of running Scheme, the read-eval-print loop of the Scheme machine is Wraith Scheme's "real" event loop. It does what it was built to do, which is to execute Scheme programs. The Cocoa event loop -- indeed, the whole Cocoa/Objective-C side of the program -- is merely a convenient auxiliary task whose purpose is to deal with the user and the user interface. The real design pattern for Wraith Scheme isn't actually model/view/controller, it is more nearly something like little-man-behind-the-curtain/talking-head/controller. My apologies to Dorothy if this doesn't look like Cupertino any more, but the truth is, it never did.
The Cocoa side of Wraith Scheme is for the most part pretty straightforward. I did not mess with the Cocoa event loop itself very much; it comes up and runs automatically, in the way that has become conventional. The big deal is how the Scheme machine learns that something it needs to know about has happened in the user interface.
Since I used the canonical mechanisms that Xcode and Interface Builder provide for developers to use in hooking up events to handlers, all I had to do was provide a function in each of the handlers for events that the Scheme machine needed to know about, to pass that information into the communication and synchronization mechanism that coordinates the GUI and the Scheme machine. The function that does that is "tellEvaluator". It is located in file "WraithSchemeOuterController.mm" (the ".mm" suffix is Apple's convention for files that mix Objective C and C++), which is in the "WraithCocoa" subdirectory of the main project directory, "WraithScheme.64".
Function "tellEvaluator" is rather a dual to "tellController", mentioned in a previous section, that transmits event information in the opposite direction. I will discuss both of these functions, and other functions and mechanisms related to them, in a subsequent section. What I wish to explain now is how "tellEvaluator" is used by the event handlers in the Cocoa side of the program. Here is a simple example of some actual code; it is the action that is associated with Wraith Scheme's buttons and menu items whereby the user requests that Wraith Scheme reload the most recent file of Scheme code that has already been loaded:
//######## Loading the last file loaded:
- (IBAction) loadLastFile:(id)sender {
if( strlen( lastFileLoadedPathAsCString ) > 0 ) {
[self setForEvaluating];
[self tellEvaluator:C_INPUT_READY
withLong:0
withString:[[NSString stringWithFormat:
@"(load \"%s\")\n",
lastFileLoadedPathAsCString]
cStringUsingEncoding:NSASCIIStringEncoding]];
}
}
This use of "tellEvaluator" is non-trivial, but it is simple in that no action is required on the Cocoa side of the program at all -- the entire job of file-loading is accomplished by the Scheme machine alone. The program has already saved away the path to the last file loaded for just this kind of occasion, so after a little defensive programming to make sure that there was a last file loaded, "tellEvaluator" is called with an actual Scheme "load" instruction -- of the form
(load "path/to/last/file/loaded")
as its "string" argument. That Scheme instruction is built up by the Cocoa procedure "NSString.stringWithFormat" (which is a procedure associated with Objective C class "NSString"). The "long" argument is not used in this particular call of "tellEvaluator". The enum value that identifies the event in question is "C_INPUT_READY".
I must be careful to mention that the "C_" in that name has nothing to do with the C language -- it is merely shorthand for "Controller". All of the enum values that are used in telling the Scheme machine about controller events start with "C_"; the full enums for both directions of communication are in the include file "CocoaInterface.h".
When the Scheme machine eventually gets that command, it will switch on the enum value that is the first argument, and will find that for a first argument of "C_INPUT_READY", it is supposed to push the string argument into Wraith Scheme's reader, so that Wraith Scheme will carry out the "load" command just as if the user had typed it as input.
The two parts of the Wraith Scheme Cocoa implementation -- the Scheme machine and the Macintosh GUI -- need to transfer messages back and forth when one part wants some action to be performed by the other. The Scheme machine uses the function "tellController" to send such messages to the Macintosh GUI, and the Macintosh GUI uses the function "pollEvaluatorOnce" to receive them. The Macintosh GUI uses "tellEvaluator" to send messages to the Scheme machine, which uses the function "pollControllerOnce" to receive them.
Both "pollEvaluatorOnce" and "tellEvaluator" are located in file "WraithCocoa.64/WraithCocoa/WraithSchemeOuterController.mm". Both "pollControllerOnce" and "tellController" are in "WraithCocoa.64/source/CocoaIO.c++". Each "poll..." function is just a big switch on the kind of message received, wrapped within the code that deals with critical-section locking.
As you might suspect from the similarity of names, the mechanism for transferring messages between the Scheme machine and the Macintosh GUI is similar in both directions. Things common to both directions of message flow include the following:
Major differences in this mechanism, between the two directions, include the following:
Text input from the GUI into the Scheme machine occurs in "pollControllerOnce", with the action for "C_INPUT_READY", which calls "addToInput" with the passed string. The latter function is very simple -- it copies the text into a buffer from which the Scheme machine can draw input as necessary. Before doing so, it checks to see whether the existing buffer is large enough. If not, it creates a new, larger one, copies the content of the old to the new, and frees the old buffer.
Text output from the Scheme machine is passed through function "Cocoa_printf", in "CocoaIO.c++". This has some special handling for fatal error messages, but otherwise, it strips off one line at a time from its input by using "Cocoa_printfAtMostOneLine", which prints the line as appropriate. The latter function contains some special handling for Wraith Scheme's "nostalgia mode", in which Wraith Scheme simulates the behavior of an old-style 300-baud green-phosphor glass tty. In any case, the text to be printed is ultimately passed to the controller via "tellController", with a message type of "E_OUTPUT_READY".
The Wraith Scheme Cocoa implementation has three slightly different interrupt mechanisms in place and available to users. They are based on the Unix software interrupts that are described, among other places, in the "man" page for "signal". (Try "man signal" from the command line.) Most of the relevant code is in source directory file "EventsForCocoa.c++".
The first interrupt mechanism is a very simple handler for the Unix "SIGINT" interrupt. It has actually been in Wraith Scheme for a long time, including most of the 32-bit versions; I just did not document it. If anything sends the SIGINT interrupt to any Wraith Scheme process, a conventional Unix-style interrupt handler will run, that posts a REQUEST_RESET_EVENT into Wraith Scheme's event-handling mechanism. If that Wraith Scheme process is running normally, it will soon reset itself to the top-level loop. If the process is stuck in a loop somehow, such that Wraith Scheme events are not handled, then the reset will not happen. (Such a situation would be an implementation error, and my fault.)
To use this mechanism, imagine that you have used the Unix "ps" command, or some other means, to determine the Unix process identification number of a Wraith Scheme process. Suppose for purposes of discussion that that process identification is 12345. Then, bearing in mind that the literal value of SIGINT is 2, you might type
kill -2 12345
in a Terminal shell. If all is well, that Wraith Scheme process will shortly reset itself.
You may know that SIGINT is what is typically sent to Unix command-line processes when the user types "control-C". Note that control-C doesn't work for the Wraith Scheme Cocoa implementation: The default for Macintosh applications is not to handle control-C keyboard events, and I did not change that condition.
The second interrupt mechanism involves a signal-handler for the Unix "SIGALRM" interrupt, and some procedures to use the underlying Unix "alarm" mechanism, which in turn will use this interrupt. If anything sends the SIGALRM interrupt to any Wraith Scheme process, a conventional Unix-style interrupt handler will run, that posts a SIGALRM_EVENT into Wraith Scheme's event-handling mechanism. If that Wraith Scheme process is running normally, it will promptly push into the kitten input queue of the kitten that received the event, the S-expression '(e::alarm), in which "e::alarm" is a user-defined lambda expression of no arguments.
For a detailed discussion of the procedures that support this mechanism, see the Wraith Scheme Help file and the Wraith Scheme Dictionary.
The third interrupt mechanism is more general and more powerful: It provides a way whereby any Unix process -- such as any application -- may send an interrupt to any Wraith Scheme process, and in so doing may indicate which of a user-selected variety of interrupt handlers will run in response to the interrupt. As I write these words, Wraith Scheme has 1024 logically distinct interrupts, any combination of which may be requested at the same time, and each such interrupt may have its own, different handler, in the form of Wraith Scheme code specified by the user. The mechanism to implement all this has four important software pieces.
First, there is a conventional Unix-style signal-handler for SIGUSR1, whose source code and auxiliary functions are in source directory file "EventsForCocoa.c++". It runs whenever a Wraith Scheme process receives the SIGUSR1 software interrupt, and all it does is post a SIGUSR1_EVENT into Wraith Scheme's event-handling mechanism. When that event is processed -- and like other Wraith Scheme events, it may not be processed immediately -- Wraith Scheme must use the other two pieces of the interrupt system to figure out what to do.
The second part of the mechanism is a piece of memory-mapped shared memory, associated with a publicly known file, that contains a table of 1024 boolean flags that are intended to specify what interrupts are requested. The idea is that any program that needs to interrupt Wraith Scheme may memory-map that file into its own address space, set whatever flag corresponds to the interrupt it needs, and then send signal SIGUSR1 to some Wraith Scheme process. As an aid to finding out the Unix process identifications (PIDs) of Wraith Scheme processes, that piece of memory-mapped memory also contains a table of all the PIDs of all running Wraith Scheme processes, indexed by kitten number, and a table of booleans indicating whether each interrupt has a handler installed, similarly indexed.
Each Wraith Scheme process memory-maps that same piece of shared memory into its own address space as well. Thus, when a Wraith Scheme SIGUSR1_EVENT is handled, Wraith Scheme can look through the table to find which interrupt or interrupts are pending. That lookup process happens in the body of function "dealWithSIGUSR1", in "EventsForCocoa.c++". There is an implicit prioritization of interrupts, as well: Every time "dealWithSIGUSR1" runs, it executes a "for" loop that starts with interrupt zero and looks at each interrupt in turn, arranging to run the handler for any interrupt that has a handler installed, and whose flag is set to TRUE. If the user has not specified a handler for some interrupt, "dealWithSIGUSR1" does nothing and does not complain. Once the handler has been set up to run (just what that means is explained in a paragraph or two), "dealWithSIGUSR1" clears the flag for that interrupt, and proceeds to the next interrupt in its "for" loop. If the user has inadvertently requested an interrupt for which no handler is installed, "dealWithSIGUSR1" will clear the request flag for that interrupt.
The third part of the mechanism is a table of interrupt handlers stored in Wraith Scheme main memory, indexed by interrupt number. An empty list corresponds to "no handler". A valid table entry is a cons cell whose car is a kitten number -- the number of the kitten that is supposed to execute the handler -- and whose cdr is an S-expression to be added to the input queue for that kitten. I refer to that S-expression itself as the "handler" for the interrupt. (Input queues and their uses are described in the "Interprocess Communication" section of the Wraith Scheme help file.) The S-expression can be anything the user likes -- just a number or a string might be enough to demonstrate that an interrupt is working (it will eventually appear in the Wraith Scheme window of the kitten in question) -- but what will presumably be most useful will be a quoted procedure application, something like
'(do-something-wonderful foo bar baz)
that the kitten in question is supposed to execute.
The fourth part of the mechanism is a vector of blocking flags located in the shared memory managed by the clowder, that are used to ensure that at most one Wraith Scheme process at a time can examine the interrupt-request flags for an interrupt. The blocking flags are used to make the examination of interrupt flags done in "dealWithSIGUSR1" a critical section; without them, a particular interrupt handler might accidentally get executed twice, if two different Wraith Scheme processes happened to receive SIGUSR1 signals at the same time.
The same blocking flags are also used to disable an interrupt while its handler is being changed.
Let's be perfectly clear: When a Wraith Scheme MomCat or kitten receives a SIGUSR1 interrupt for which the user has defined a handler, it will end up adding an S-expression of some kind to the input queue of some Wraith Scheme process. The process whose input queue gets the handler may or may not be the process that received the SIGUSR1. The user can send the SIGUSR1 interrupt to any Wraith Scheme process he or she likes; but the kitten into whose queue the S-expression gets pushed will always be the kitten whose kitten number is the car of the interrupt handler. You can imagine that the SIGUSR1 interrupt conveys the instruction, "Tell the kitten specified at thus-and-such a location in the table to do what the table says there."
Input queues and their uses are described in the "Interprocess Communication" section of the Wraith Scheme help file.
Note that the same table of boolean interrupt-pending flags is shared by all Wraith Scheme processes, as is the same table of interrupt handlers. Therefore it does not matter which Wraith Scheme process receives a SIGUSR1; any one can deal equally well with any interrupt. Notwithstanding, the response time for handling an interrupt -- the time before the SIGUSR1_EVENT is processed -- will necessarily depend on how busy the Wraith Scheme process was when it received the SIGUSR1 signal.
The Wraith Scheme interrupt system has a great deal of power and flexibility, but also has some important limitations. Notably, there is no queue of pending interrupts. Therefore:
Scheme's lexical scoping mechanism involves finding the bindings of variables by looking them up in a series of nested environments, corresponding to the nesting of lexical blocks of code at the place where the binding is needed. For example, in the following figure, Block A is nested within Block B, which is in turn nested within Block C. Block D, on the other hand, is only nested within Block C.
Nested blocks.
If these blocks are blocks of Scheme code, and if a variable binding were required within Block A, then the Scheme machine would first look to see if the variable were bound in Block A; if not, it would see if it was bound in Block B, and then in Block C. Then it would fail -- by mistake, the code would have called for a variable that was not bound within the lexical scope of the place where the binding was needed.
On the other hand, if a variable binding were required in Block D, the Scheme machine would first look to see if the variable were bound in Block D, and then in Block C. It would be wrong to look in Block A or Block B, because neither of those blocks is part of the lexical scope of anything in Block D.
One common way to implement such a lookup mechanism is by having the environment for each block be a list (typically of name/binding pairs), and chaining the lists together as necessary to represent the complete lexical environment for each block. (The lists for each individual block are implicitly shown as cdr-coded, but that is only for simplicity of illustration, and need not be so.)
Complete lexical environments as lists sharing structure.
Thus lookups of bindings needed in Block A start with the list section labeled "Environment for Block A alone", and follow the list of which it is a part till its end, at the end of "Environment for Block C alone". Lookups for Block D start at "Environment for Block D alone", and so on.
Wraith Scheme does it differently. Instead of having the complete lexical environment for lookups that are made in a particular block implemented as a long linked list (of name/binding pairs), it is a list of individual block environments, as shown below. Note that the individual block environments are not chained together, rather, there is a much shorter list which has pointers to each separate block environment in turn.
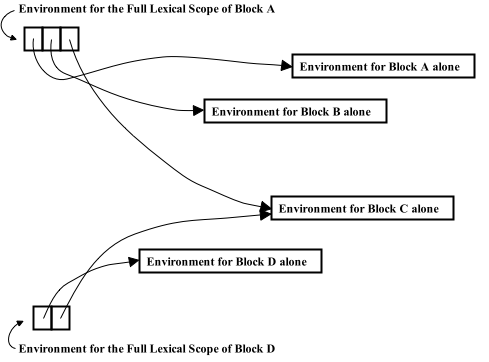
Complete lexical environments as lists of block environments.
With this structure of an "environment list", there is no longer a requirement that each individual block environment be a list, and indeed, not all of Wraith Scheme's block environments are lists. Some are, but others are hash tables, implemented as vectors of lists. Since Wraith Scheme is typed, the software that looks up variable bindings can go through an environment list, detect whether each individual block environment is a list or a vector (hash table), and do the appropriate kind of lookup for it.
A particularly important Wraith Scheme environment is the top-level environment, which is the full lexical environment of lookups of variable bindings which take place in the read/eval/print loop. That is, if you type
foo
into Wraith Scheme, the top-level environment is the environment in which the Scheme machine looks to see whether "foo" is bound to anything.
Wraith Scheme's top-level environment is an environment list that contains three elements:
The interactive environment is implemented as a hash table because some patterns of use of Wraith Scheme may result in large numbers of variables being defined and bound in the top-level environment. The lookup of a variable binding in a lengthy list would take a long time. A hash table is quicker.
So for example, suppose you type
if
into the top-level loop. The Scheme machine will proceed to find the binding of "if", as follows: First, it will hash "if" and look in the corresponding hash bucket of the vector which represents the interactive environment to see whether "if" is there. Unless you have previously modified "if" (and are thereby living very dangerously), it won't be, so next it will try the second element of the top-level environment list, which is the list that represents the Scheme report environment; it will cdr down the name/binding pairs in that list, looking for "if", and again, it won't find it. Finally, it will do the same thing with the list that represents the null environment, and -- behold -- will find and display the binding, not particularly usefully but with the very best of intentions, as follows:
#<Macro>
(If you want to learn more, try "(e::inspect if)" and be prepared for a page or so of output.)
All other Wraith Scheme block environments, such as those associated with lambda expressions, are simple lists of name/binding pairs. Thus the most general form of a complete Wraith Scheme lexical binding environment list is a list of zero or more simple lists of name/binding pairs, corresponding to nested lambda definitions, followed by the three elements of the top-level environment list, as described above.
The Wraith Scheme SECD machine has two special-purpose registers that have to do with environments. One holds a pointer to the current environment list, whatever it may be. The other holds a pointer to the top-level environment list.
In other documentation, I have developed the bad habit of not always clearly distinguishing between a "block environment" and an "environment list", in the sense of the preceding discussion. I often use the word "environment" to describe either one of them.
I thought it would be useful to describe some of the C++ structs that are complex and widely used in Wraith Scheme, at the level of the header files that define them. All the relevant header files are in directory "WraithScheme.64/include".
The first thing to notice is that I have a file called "LocalTypes.h" that is full of typedefs like
typedef unsigned long UnsignedLongWord;
The practice of naming elementary types in a way such that you can keep their definitions separate from implementation-based word sizes and the like, is very old. Apple presently does the same kind of thing with, e.g., SInt32. This is my personal file of useful low-level type names. You may have to look things up in it if you find a type name whose meaning is not immediately obvious.
The very short file "TaggedAval.h" contains the typedef for "taggedAval", and a bit of other material. What is relevant is this:
typedef UnsignedLongWord Tag;
typedef struct taggedAvalStruct {
Tag t;
union {
LongWord c;
ShortFloat f;
struct taggedAvalStruct *a;
} u;
} taggedAval;
The struct so defined is two 64-bit words long. There is a 64-bit tag -- probably too many bits -- in one word, and the other is a union (to sneak around the compiler's pickiness with casts) of a 64-bit integer, "c", a 64-bit IEEE float, "f" (the "Short" in "ShortFloat" means "short compared to 80 or 128 bits"), and a pointer "a" that is taken as a pointer to another taggedAval unless you cast it otherwise.
The file that describes the assorted field values for tags, and that has lots of inline functions for testing and manipulating them, is "WraithConsts.h". That is where you look for global definitions of tagged aval types, masks and offsets for various bits and fields, and so on. There are a great many things in this file, but I think they are all simple enough that I don't need to go into them in any detail. Just be sure that you know the file is there.
File "DataTypes.h" contains the definitions of several important structs; one of these is "fileDescriptor". These structs contain the information about every file that is associated with a Scheme port. Each Wraith Scheme process has an array, or pool, of fileDescriptors for it to use. The struct is as follows:
typedef struct {
Text *pathName;
Text *oldPathName;
FILE * fp; /* The Unix file pointer */
Boolean fdOpen; /* Is this entry in the table of file descriptors now open? */
Boolean fdInUse; // Kind of a garbage-collection flag just for file descriptors;
// idea is to set this to TRUE if, and only if
// (1) at least one pointer in the heap, after GC, points to
// this file descriptor, OR
// (2) a register points to it, OR
// (3) it is one of the default ports.
Text *type; /* Access rights for file; a parameter to C "fopen", etc */
LongWord placeInBigArray; // At what index in "AllFileDescriptors" is this?
LongWord kittenNumber; /* What kitten number is for this fileDescriptor? */
} fileDescriptor;
I think the comments in that code are pretty good, but there are a few more things to note. Fields "pathName" and "oldPathName" are pretty obvious in their meaning; "oldPathName" is used in the description that Wraith Scheme provides of a port that is closed; there will be some text telling that the port was formerly associated with file so-and-so.
Field "placeInBigArray" is the file descriptor's own record of what location it occupies in the pool of fileDescriptors that are available for its Wraith Scheme process to use. It is there to save doing a search in case there is code that has a pointer to a fileDescriptor and needs to know where in the pool it is.
The "placeInBigArray" and "kittenNumber" information for every fileDescriptor get put into whatever Wraith Scheme port is using that file descriptor. Ports are in Scheme main memory, where any Wraith Scheme process can see them. Thus the information about "kittenNumber" is relevant, when it is in a port, and "placeInBigArray" provides a way to know which fileDescriptor in the pool is associated with the port, without having the port store an explicit pointer that leads outside of Wraith Scheme memory.
File "DataTypes.h" also contains the definition for struct "dataDescriptor". These structs contain basic information and methods about every type of Wraith Scheme object that can occur in Scheme main memory. The struct has a long embedded comment, so I am going to present it somewhat reformatted.
typedef struct {
UnsignedLongWord pNameNumber; /* Cursor into a resource list (of print names). */
const char *pName; /* Print name of the data type, e. g. "Symbol". */
Tag tag; /* Tag which characterizes this data type. */
UnsignedLongWord length; /* Datum length, in Bytes. "0" means use the ... */
UnsignedLongWord (*lengthFinder)( taggedAval *a ); /* ... function (of pointer to datum) instead. */
void (*identifier)(); /* Predicate to test whether a tag is of this type. */
Boolean (*display)( taggedAval *aPort); /* How to display an instance of this dataDescriptor */
Boolean (*write)( taggedAval *aPort); /* How to write an instance of this dataDescriptor */
Boolean (*inspect)( taggedAval *aPort); /* How to inspect an instance of this dataDescriptor */
The software itself knows how to do the swapping of just a tagged aval. When I wrote these words, it was two four-byte fields, and the big-endian / little-endian transformation is easy and symmetrical. The problem occurs when data items are not simple tagged avals; perhaps the pointer field of the tagged aval is a pointer to something else in main memory, and that must be transformed in a way that requires knowing what it is. These functions are for transforming the *rest* of the data item, anything beyond just the tagged aval itself.
There is a noteworthy gotcha: When a big-endian machine has read a world file, it cannot know anything about a data item until it has transformed the tagged aval that is part of it; those bits are meaningless for it, until they have been converted to big-endian format. Thus these transformations must be done sequentially, in a pass through the memory image, knowing that the memory image starts with the tagged aval portion of some data item. The tag gets transformed, then anything it may point to, then the transformed data item may be used to determine its own length and thus the address of the next untransformed data item to deal with.
Since porting Wraith Scheme to a 64-bit application, I have not had a chance to test the "swapping" stuff, because the 64-bit port runs only on Macintosh computers with Intel or "Apple silicon" processors, which are little-endian. The relevant code, and these fields in this struct, are left in, in case they are ever needed.
/* Flips a big-endian instance to little-endian. */
UnsignedLongWord (*flipToLittleEndian)( taggedAval *a, void *worldEnd, void *world, void *alternateWorld );
/* Flips a little-endian instance to big-endian. */
UnsignedLongWord (*flipToBigEndian)( taggedAval *a, void *worldEnd, void *world, void *alternateWorld );
} dataDescriptor;
There are two struct slots that have to do with the print name of the data type. The first is "pNameNumber", which is an index into a big list of names, wherein lies the real print name. On initialization, that name is copied into the second slot, "pName", for quick availability. Thus the different names are kept in a single location for ease of maintenance, and perhaps for ease of supporting different languages.
There are also two structure slots that have to do with how much space in Scheme memory the data type occupies. The way it works is, that if slot "length" is zero, you are supposed to use the next following slot, "lengthFinder", to find the length of the object. But if "length" is not zero, its value is the length of the object in bytes.
The third struct definition contained in file "DataTypes.h" is the one for "memorySpace". Instances of "memorySpace" are what is managed by the memory manager. The struct became more complicated with the introduction of generational garbage collection.
typedef struct memorySpaceStruct {
volatile Byte *end; /* Points one past the end of usable memory for this space. */
volatile Byte *free; /* Pointer to next (high) location usable for this space. */
volatile Byte *lowFree; /* Pointer to next (low) location usable for this space. */
volatile Byte *space; /* Pointer to start of usable memory for this space. */
volatile UnsignedLongWord size; /* How many bytes in this space? */
volatile Boolean inUse; /* Set when a space contains at least some non-garbage; used
(e. g.) by the garbage collector, to detect recursive
garbage-collection. */
volatile struct memorySpaceStruct *allocateDomain; // Where does allocation take place?
volatile UnsignedLongWord allocateSize; // How many bytes in the space, considered as an allocatable domain
volatile Byte *allocateMax; /* Pointer to the low end of allocatable memory for the allocate routines. */
// Start of additions for generational garbage collector.
volatile struct memorySpaceStruct *generationA;
volatile struct memorySpaceStruct *generationB;
volatile struct memorySpaceStruct *activeGeneration;
volatile struct memorySpaceStruct *agingGeneration;
volatile UnsignedLongWord *activeGenerationStackEnd;
volatile UnsignedLongWord *agingGenerationStackEnd;
} memorySpace;
Note that an instance of "memorySpace" does not actually contain any memory space -- slot "space" is only a pointer to the actual space itself, which must be obtained by other means, such as malloc or memory-mapping, and passed to the memory manager at initialization time. The intent is that initialization should set up the instance of "memorySpace" so that "space" starts to the low-address end of the given block of memory, "end" points to the first address past the given block of memory, and "size" is the capacity of the given block of memory, in bytes.
Slot "free" is intended to be kept pointing to the low end of allocated memory: Recall that in normal use, Wraith Scheme allocates memory from the high address of Scheme main memory, downward. Slot "lowFree" is for similar use during the copy-across phase of garbage collection, when memory is temporarily being allocated from the low-address end of the alternate space, upward. Slot "inUse" is a Boolean I put in for debugging.
The additions for the generational garbage collector deal with two high-level matters
Those two matters lead to the following implementation details:
The initializers for memory spaces set all this stuff up. The code there is messier than I like.
The fourth struct definition contained in file "DataTypes.h" is the one for "mmappedBlockDescriptor". Instances of "mmappedBlockDescriptor" are created by the Wraith Scheme Scheme machine whenever the user requests Wraith Scheme to memory-map a block of shared memory, very likely with the intention of having some other, non-Wraith-Scheme process also memory map it and thereby share data with Wraith Scheme. This struct is used to lay out the contents of a Wraith Scheme byte block, which is part of a taggedAval of type "mmappedBlockTag", and is stored in Wraith Scheme main memory after it has been created.
The struct itself is relatively simple:
typedef struct {
// The next two variables are on a per-kitten basis.
// Initialized false, set true if and only if mmap returned non-null.
Boolean mmapWasSuccessful[ ABSOLUTE_MAX_KITTENS ];
// Initialized false, set true if and only if munmap is called hereon.
Boolean regionHasBeenUnmapped[ ABSOLUTE_MAX_KITTENS ];
Boolean fileHasBeenWritten; // Initialized to false, set to true if and only if
// the file has been loaded full of initial data.
// The next few arguments are a record of what mmap is called with.
void *absoluteAddress; // Pointer to start of block returned by mmap.
size_t size; // Size is in bytes.
int prot; // Region accessibility.
int flags; // Miscellaneous flags, or'd together.
int fd; // File descriptor.
int offset; // Offset within file.
} mmappedBlockDescriptor;
Note that an instance of "mmappedBlockDescriptor" does not contain the memory-mapped block. Slot "absoluteAddress" is merely a pointer to the actual block itself.
When several Wraith Scheme processes -- a MomCat and some kittens -- are running in parallel, they are all separate Unix processes. Therefore, even though the instance of "mmappedBlockTag" taggedAval is stored in Scheme main memory, where any of those Wraith Scheme processes can in principle get at it, the memory-mapped block of memory is not accessible to any given Wraith Scheme process until that process itself has used "mmap" to map the block.
There is one Wraith Scheme primitive, "e::make-memory-mapped-block", to memory-map the block the first time (in which case a file associated with it is also created and written full zeros). That primitive memory-maps the block only in the Wraith Scheme process which executes it, and returns a corresponding instance of "mmappedBlockTag" taggedAval, which in turn contains a pointer to a byte block, stored in Scheme main memory, that contains the data specified in the struct. A second Wraith Scheme primitive, "e::memory-map-block-in-current-kitten", takes a pre-existing instance of "mmappedBlockTag" taggedAval as an argument, and uses the information stored in it to memory-map the block anew in whatever Wraith Scheme process is executing that primitive.
The reason why the first of those two primitives does not immediately memory-map the block in all extant Wraith Scheme processes is that there is no way for one Wraith Scheme process to get another Wraith Scheme process to do something immediately. The user could be misled into thinking that all Wraith Scheme processes had memory-mapped the block when in fact they had not.
The first three slots in the struct keep records of the state of mmapping in the various Wraith Scheme processes that are running: Slot "mmapWasSuccessful" records which kittens have in fact memory-mapped the block. Slot "regionHasBeenUnmapped" is at present unused, but is intended for a possible future facility to unmap blocks. Slot "fileHasBeenWritten" records whether the attempt to open and write the file associated with the memory-mapped block was successful.
The remaining slots in the struct are an administrative record of the arguments that were passed to the Unix "mmap" function. Slot "absoluteAddress" is a pointer to the location of the memory-mapped block in Wraith Scheme's address space; that address is within a large block of memory that is shared by all Wraith Scheme processes, and it will have the same numerical value in all Wraith Scheme processes. (The business a few paragraphs back, about having to memory-map the block in all the different Wraith Scheme processes, really has to do only with making all those processes associate the same file with the block.) (See the section on "Memory-Mapping and MMAP" if you are as confused as I usually am about what all this means.)
The memory regions used for these blocks are allocated from a large area of Wraith Scheme shared memory by a trivial allocator that simply goes straight through the available area until it runs out. There is no provision to "free" the memory in such a memory-mapped blocks. The total amount of address space available for these memory-mapped blocks is more than 100 GByte as I write these words, which I hope is sufficient for the moment, even without freeing. Each address returned by the simple allocator will be page-aligned, as required by "mmap".
Slot "size" is the size in bytes of the block. Slots "prot" and "flags" refer to parameters passed to "mmap" -- see the "man" page for "mmap" for details. (The actual values used by Wraith Scheme are at present hard-coded into the relevant Wraith Scheme primitive.) Slot "fd" is the file descriptor associated with the file, and "offset" is the offset within that file at which mmapping is supposed to start. (The value of "offset" is presently hard-coded to be zero.)
What about the file name? The full path to the file is a string of variable length: To save memory, I did not encode a large fixed-length char array into the struct; rather, I placed the full path to the file in the same byte block that contains the instance of the struct, just past the struct itself. There is no need for a specific pointer to it, since the Wraith Scheme Scheme machine understands the structure of the byte block and can find the string by offsetting sizeof( mmappedBlockDescriptor ) past the struct itself.
With every Wraith Scheme procedure and special form there is associated a lot of information, kind of metadata for the procedure itself. This information includes the procedure's name, the numbers and types of arguments it takes, the kind of values it can return, and so on. Wraith Scheme uses a number of structs to attempt to capture this metadata in a form in which it is easily available to the Wraith Scheme program, and perhaps to the compiler, for use when necessary.
Now might be a good time to recall the difference between a procedure and a special form. Suppose that Wraith Scheme -- or indeed, any Lisp implementation, has to evaluate an S-expression like
(foo bar baz frob mumble quux)
How does that evaluation take place?
The implementation first evaluates the first item in the S-expression, which is in this case the symbol "foo". If the result is a procedure -- as it would be, for example, if instead of "foo" we had "list" or "+" or "display" -- then the implemention evaluates all the rest of the items in the S-expression, and applies the result of evaluating the first item to a list composed of all the other evaluated items, in their original order.
If the first item evaluates to some other kind of thing that the implementation knows how to use to manipulate the other items in the S-expression, then it does whatever is appropriate for that particular first item, which may or may not involve evaluation of the other items. In Scheme, the candidate built-in first items that are not procedures are the syntactic keywords, like "if", "let*", "define", "set!", and so on, but you can make more of them to suit yourself by using things like macro facilities. Indeed, in Wraith Scheme, most of the syntactic keywords are implemented as macros.
In the broader Lisp community, the term "special form" has been used for the kind of thing that today's Scheme community calls "syntactic keyword". I am in the habit of still using the earlier term.
If the first item in the S-expression evaluates to something that is neither a procedure nor a special form, then the implementation will have no idea how to "apply" it to the rest of the S-expression. It will have to report an error.
Anyhow, as the word is understood by the Scheme community, procedures have requirements of type and of arity that their argument list must obey, and they also are specified to return particular kinds of values. Information of this sort will always be among the metadata for any Scheme procedure, so it is no surprise that the structs for functionDescriptors all have lots of slots for these items of data. (As is common, I am blurring the distinction between "function" and "procedure". I hope you will forgive me.)
On the other hand, for special forms, there are no broadly applicable rules. There are special forms of every shape and kind. Some evaluate all of their arguments, like procedures do, some evaluate just a few, and some evaluate none at all. Some have arity requirements and some do not. In the absence of much metadata that is common to all special forms, the struct called "specialFormDescriptor" is pretty short. So let's take that one first. It is in "SchemeSpecial.h", and it is all that is there:
typedef struct {
void (*evalCode)(); /* do this with the arguments ... */
LongWord pNameNumber; /* index of the print name in a table. */
} specialFormDescriptor;
The second slot tells how to get the name of the special form. The first is the code that implements what it does. (That code is called at a time when a pointer to the entire S-expression which comprises the use of the special form is in the SECD machine's "R" register, so it does not need any arguments.)
There is one catch: Not all Wraith Scheme syntactic keywords are the kind of special form that I have just described. Most of them are implemented as macros, and macros are handled differently. At the level of reading the Wraith Scheme source code, the major difference is that for every special form of the kind just described, there exists in the compiled Wraith Scheme program some compiled C++ code to put in the "evalCode" slot of the specialFormDescriptor: We might say that special forms are evaluated in C++. For macros, there is no such code. The code that evaluates a macro is defined in the Scheme programming language itself, and is never compiled into C++. We might say that macros are evaluated in Scheme.
There are at present six different kinds of functionDescriptors in Wraith Scheme, all defined in "SchemeFunctions.h" The reason why there are more than one is that Scheme procedures have several different kinds of type and arity schema -- different means for determining whether they are given the correct type and number of arguments. It seemed simpler to use different functionDescriptors for the different schema than to try to make one functionDescriptor with sufficient flexibility to encompass all of them.
Let's get that complexity out of the way first. The type and arity schema for the six types of function descriptors are as follows:
Yes, there used to be functionDescriptors of types Two, Three, and Four. With one thing and another, I eventually found that I no longer needed them.
The various numbers in these schema are provided by slots in the several structs. The means for checking types are by providing struct slots for either an array of type-checking predicate functions (in instances of functionDescriptorTypeOne only), or for single type-checking predicate functions (in all other functionDescriptors). There are also struct slots which contain the literal text names of the types of arguments required by the function, so that error messages can tell you what kind of argument a function is supposed to have when you have inadvertently given it the wrong kind.
Complexity notwithstanding, there are five slots that are common to all types of functionDescriptor:
I thought when I put this slot in, that having this predicate called out might be useful for Wraith Scheme's built-in Scheme compiler, but now I am not so sure. Wraith Scheme does not at present use this datum for anything.
The way this stuff is used is that there are instances of the various kinds of functionDescriptor declared and initialized in the source code, generally not far from the code that implements the procedure in question. There are also large static lists of the various kinds of functionDescriptors -- for procedures, they are in "WraithScheme.64/source/SchemeFunctions.c++", and for special forms, in "SchemeSpecials.c++". At launch-Wraith-Scheme time, those lists are processed, to create objects that are stored in Wraith Scheme main memory, bound to the print names of the various functions.
That is, to each functionDescriptor or specialFormDescriptor there eventually corresponds a name/value pair in Wraith Scheme main memory, whose name is the name of the procedure or special form, and whose value is a vector containing the same information that was in the descriptor. (Or at least, the vector contains most of the information; I do not put in the slots that are not used.) For procedures, the first item in each such vector is an enum value, defined in "WraithConsts.h", to tell what kind of procedure is involved:
typedef enum {
FIXED_ARITY, // functionDescriptorTypeOne
ANY_ARITY_ONE_TYPE_STACK, // functionDescriptorTypeFive
POSITIVE_ARITY_TWO_TYPES_STACK, // functionDescriptorTypeSix
ANY_ARITY_TWO_TYPES_STACK, // functionDescriptorTypeSeven
ANY_ARITY_TWO_TYPES_STACK_2, // functionDescriptorTypeEight
NONNEGATIVE_ARITY_TWO_TYPES_STACK, // functionDescriptorTypeNine
} BuiltInProcedureType;
Between that enum and the information in the other items of the vector, the Scheme machine can find out at run-time all it needs to know to verify that the type and arity of the arguments to a given procedure are correct, and can also find the actual code required to implement a procedure or special form. Thus, for example, C++ code in Wraith Scheme switches on the enum value given above, to find out how to pull the type-checking predicates out of the vector, and what arguments should be checked with which predicates.
There is one more interesting detail. The vectors just described are not stored in Scheme main memory as vectors. There are two special tags that are in essence renamings of vector, that are used instead. They are "builtInFunctionTag" and "specialFormTag".
The mechanisms that Wraith Scheme uses for type and arity checking were pretty much described in the preceding section, Function and Special Form Descriptors. Notwithstanding, a little remains to be said about how those mechanisms are used.
With very few exceptions, Wraith Scheme checks the type and arity of all built-in procedures at run-time, even in compiled code. The only procedures that I can think of at the moment for which type-checking is not done are "c::release-block" and "c::set-blocked-binding!", in both of which cases the act of type checking might conceivably cause a deadlock.
Both arity checking and type checking are done at a point in the evaluation of an S-expression that represents a procedure call, when all the arguments of that S-expression have been evaluated (recursively, if necessary). If the procedure is not of "type one" (functionDescriptorTypeOne), then the arguments are pushed onto Wraith Scheme's stack, with the number of arguments left in the accumulator. For a type one procedure, the number of arguments is fixed and available to Wraith Scheme from the descriptor information, so the number of arguments is not provided at run-time; instead, the last argument is left in the accumulator.
These things happen in the C++ procedure "apply", which is in file SECDEval.c++. At that point, the C++ code looks up the information about arity and type-checking predicates that is stored in the instance of "builtInFunction" associated with the function being applied, and performs the checks. In case of any failure of either arity or type checking, Wraith Scheme will print an error message and reset itself to the top-level loop.
The Wraith Scheme evaluator has been one of the big reasons I was reluctant to go open-source with Wraith Scheme. As originally written, it was not good code; I was ashamed of it. Fortunately, while reviewing how it worked so that I could write this section of the Wraith Scheme Internals document, I began to have some thoughts about ways to make it better, which made it much easier for me to admit to all of you just how bad it has been. As of Wraith Scheme 2.20, the evaluator has been completely rewritten, and I am now happier with the code. Notwithstanding, be advised that if I were going to put the stereotypical warning "Abandon hope, all ye who enter here!" anywhere in the Wraith Scheme C++ source code, it would be at the start of the code for the evaluator.
Before I go further, I should alert you to two possible confusions about names. First, as you will shortly see, the C++ function that is central to the process of evaluation is called "eval", which is also the name of the R5 Scheme procedure that evaluates S-expressions; however, they are not the same. Second, the names of the various states in the Wraith Scheme state stack all start with "ESR_", which might lead you to believe that they were somehow associated with another item discussed in this section, the Evaluation State Register; however, they are not. (They were originally, but it turned out that I needed them to be in a separate stack.)
The code for the Wraith Scheme evaluator is the C++ function, "eval", in file "SECDEval.c++". That file also contains many auxiliaries for eval, and some other code as well. The evaluator also makes use of macros from include file "Registers.h", notably "PushFrame" and "PopFrame", but also others.
The C++ function "eval" does not recurse -- it is iterative -- but it achieves recursive descent by pushing activation records, or frames, onto the Scheme machine stack and popping them later, and also by pushing and popping simple records -- defined numerical constants -- that tell what it is doing onto another stack, which I call the "state stack". The heart of function "eval" is a "while" loop that never returns -- it is only exited by errors, which in turn either reset Wraith Scheme or force it to quit. The loop starts with some administrative stuff and some checks for overflow, and then comes the code that is the heart of evaluation. Let's see if I can make sense of how it works.
When the evaluator is presented with something to evaluate at top-level, it is in state "ESR_processItem", and it ends up calling auxiliary function "processItem" to deal with the thing to evaluate. That thing is necessarily either a non-empty list -- an S-expression -- or not. The "or not" cases are either atoms or errors. Note in particular that quoted things are syntactically equivalent to S-expressions like "(quote whatever)", which are non-empty lists, and that an unquoted empty list is an error -- it cannot be evaluated.
Function "processItem" deals relatively simply and straightforwardly with atoms and with actual code to be executed. With lists, however the processing must first evaluate the car of the list -- recursively descending into it if necessary -- to determine what kind of thing it evaluates to. In essence, there are three possibilities, each of which require different handling of the rest of the list.
Function "processItem" pushes a frame onto Wraith Scheme's main stack, puts the car of the list and the whole list itself in handy places, then pushes two new values, first "ESR_switchOnEvaluatedCar" and then "ESR_evaluateCar" onto the state stack. Then it returns. On the next pass through the main loop of "eval", the state stack gets popped, and the item representing the car of the list is itself processed, and the stacks may get pushed deeper and deeper if recursive descent into the car is necessary.
Eventually, however, all those evaluations pop the relevant stacks back to where the state is "ESR_switchOnEvaluatedCar". Function "switchOnEvaluatedCar" then looks at the kind of thing the car of the S-expression turned out to be, and does what is right:
From time to time the evaluation of an S-expression by Wraith Scheme will result in things being pushed into the continuation that were not part of the original S-expression, but which must be evaluated in order for the evaluation of the original S-expression to achieve its goal. Thus the code for function "eval" must take particular care to clear the continuation, even after everything that "eval" itself has pushed into it has been evaluated. For this reason, neither "eval" nor any of its auxiliary functions will ever pop the continuation stack without first checking -- dynamically, at run-time -- that the current continuation is empty.
It is important to recall that the SECD machine's continuation register, "C", is implemented as a stack. In particular, note carefully that saying "the continuation is empty" is different from saying "the continuation stack is empty". If we imagine undoing the decision to implement the SECD machine C register as a stack, then at any given moment the content of the resurrected C register would be a list of all items in the continuation stack from the current continuation stack pointer (called "CP" in the code) down to the current continuation frame pointer ("CF"). It is when those two pointers are equal, that we may say "the continuation is empty". New items are pushed onto the continuation stack, and the continuation frame pointer changed, when the evaluator undertakes recursive descent.
The evaluator uses function "emptyCSP" for that purpose. What "emptyCSP" does, is check whether the current pointer into the continuation's stack (called "CS" in the code) is the same as the continuation frame pointer ("CF"). The latter points to the location in the continuation stack at which are stored the Scheme objects whose evaluation was pending before the most recent "thing" was presented to the evaluator for evaluation. If those two pointers are the same, then all the code associated with the current "thing" has passed through the evaluator. At that point, using the terminology of the pure SECD machine from which Wraith Scheme was derived, the continuation is empty.
The evaluator peels items off the continuation one at a time, and the check for whether the continuation is empty is made after the current item was removed. When the continuation is empty, the evaluator must do something else -- typically pop a stack frame (which also pops the continuation stack).
The evaluator has an Evaluation Status Register, sometimes abbreviated the ESR, which contains other information about what the evaluator is doing. As I write these words, it is rather a new addition, and contains only one meaningful bit: The lowest-order bit is used to record whether Wraith Scheme is running in "applicative mode"; that is, within the dynamic scope of a call to "e::perform-applicative", as described in the Wraith Scheme Help file section on Applicative Programming.
Both the Scheme machine stack and the continuation stack grow from high memory toward low, which creates the usual confusion about what happens when an item is pushed onto such a stack. Let it suffice to say that both the Scheme machine stack pointer register, "S", and the continuation stack pointer register, "CS", are kept pointing at the item which is logically on the top of the respective stack, and that the macros to push things onto those two stacks work like this:
#define SPushR() ( *(--S) = R ) // Push R onto Scheme machine stack. #define CSPush( x ) ( *(--CS) = (x) ) // Push x onto continuation stack.
A Scheme machine stack frame is a contiguous group of stacked items comprising information which the evaluator saved when it was necessary to traverse nested S-expressions recursively. The current Scheme machine stack frame is located by means of an SECD machine register called "F", which always points to a particular slot of the current Scheme machine stack frame.
Since the Scheme machine stack is also used as an evaluation stack, stack frames are not necessarily adjacent to one another. There may be values between them, such as those used for calculations or for procedure calls.
At present, there are six items stored in each stack frame. From the logical top of the Scheme machine stack frame down, they are:
The notion of a stack frame for the continuation stack is not so clear, simply because there is nothing in the continuation stack except Scheme instructions. A stack frame there is implicitly defined as the span of the stack between the current value of the continuation stack pointer, "CP", and the current value of the continuation stack frame pointer, "CF".
When a frame is pushed onto the Scheme machine stack, after the current value of CF has been placed on the Scheme machine stack, the CF register is reinitialized to hold the same value as the CS register. When a frame is about to be popped from the Scheme machine stack, the CS register is reinitialized to hold the same value as does the CF register, and then the CF register is reloaded with the saved value popped from the Scheme machine stack.
The tail recursion that is required of Scheme is provided by the C++ function "tailCallOptimize", in file "SECDEval.c++". This function examines the continuation after a lambda expression has run, and pops the Scheme machine stack if the continuation is empty, and if the value of the state in the next stack frame is "ESR_processItem".
As an example of how to modify Wraith Scheme, let me show you how to add a new built-in operation. When we are done, the new operation will be just as legitimate as "+" or "call-with-current-continuation".
Suppose our desired operation is an "increment" procedure. We would like to be able to evaluate "(increment 42)", and get back "43".
Let's start by writing some code. It turns out that most of Wraith Scheme's "assembly language" routines that deal with arithmetic operations are in file "SchemeFunctions3.c++" (and there is no real rhyme or reason about which routines are in which file), so let's put the new code there. When this code runs, we can count on the Scheme machine having done type and arity checking by using the functionDescriptorTypeOne for the increment operation (we have not written it yet, but we are going to). The Scheme machine will also have put the single argument of the procedure into the accumulator. So the code is pretty simple. In the style I am used to writing in, with the kind of comment I usually make, it looks like this.
/**** incrementCode -- increment the argument by one. ****/
PROC( incrementCode )
PUSH
MOVE( one, R )
ADD
CONTINUE
END_PROC
This code is very straightforward. We push the accumulator onto the stack, then move one (a handy global) to the accumulator. "ADD" adds the content of the accumulator to the top item of the stack, pops the stack, and leaves the answer in the accumulator, right where the next procedure will expect to find it.
Now we need a functionDescriptor for our new procedure. The procedure has a fixed number of arguments -- one -- so we will be using an instance of functionDescriptorTypeOne. My personal custom is to put the functionDescriptors in right after the code, so let's do that now. We cannot quite fill out the whole functionDescriptor yet, but we can do most of it. That section of the file might look like this, except that I have added "???" to indicate where we need to do some more work before we can complete the functionDescriptor.
/**** incrementCode -- increment the argument by one. ****/
PROC( incrementCode )
PUSH
MOVE( one, R )
ADD
CONTINUE
END_PROC
functionDescriptorTypeOne incrementFD = { incrementCode, ???, TRUE, numberP, numberBitsMask, 1, numberChecker, numberCheckerNames };
What the non-??? slots means is that this particular functionDescriptorTypeOne uses C++ procedure "incrementCode", which does ("TRUE") return a meaningful value, and that predicate "numberP" would answer "#t" for that kind of value. The entry "numberBitsMask" has something to do with the type of the returned value (but recall that that slot in the function descriptors doesn't mean much any more). The procedure expects 1 argument. The entry "numberChecker" is an array of one type checker (which happens to be "numberP", that is to be used to check that the single argument passed to our new function is of the correct type. The entry "numberCheckerNames" is an array of one string used in printing an error message, in case the user of the new function should by mistake invoke it with an argument that is not a number. (The last two arrays would need to have more members if our new procedure had more than one argument.)
The missing piece of information is the index into a table of strings that WraithScheme will use to look up the name of this procedure. In file "ManyStrings.c++", search for "const Text *NameStrings[]" -- that is the array of strings where names of procedures and special forms are kept. As I write these words, it contains 378 entries, 0 through 377, with the numbers of the entries indicated by comments. Go to the end of that array, which as I write these words looks like
/* 374 */ "e::forgettable-remember-probability",
/* 375 */ "e::set-forgettable-expiration-time!",
/* 376 */ "e::set-forgettable-remember-probability!",
/* 377 */ "e::first-procedure", // To execute after a world load.
};
It is here we are going to add a new entry, for the name of our new procedure. Scheme tends not to use abbreviations -- the custom of using very long names for things is well-embedded in the Lisp community -- so it is probably appropriate to name the procedure "increment", but this procedure is an enhancement -- R5 Scheme does not define "increment" -- so I will follow my usual custom and name it "e::increment" instead.
/* 374 */ "e::forgettable-remember-probability",
/* 375 */ "e::set-forgettable-expiration-time!",
/* 376 */ "e::set-forgettable-remember-probability!",
/* 377 */ "e::first-procedure", // To execute after a world load.
/* 378 */ "e::increment",
};
Don't forget the comma after the last entry -- you don't strictly need it now, but if it isn't there when you add the next new name, things will get a little confused. Also, don't forget that the array may have changed since I wrote this tutorial -- you have to deal with the actual array as it is when you work the example.
It is most important that you not alter the position of any other entries in the "nameStrings" array -- or in any other array in "ManyStrings.c++", for that matter. Wraith Scheme obtains most of its text strings by indexing into arrays in that file. If an entry is marked unused, you may use it, or you may add more entries on to the end of the array. Note also that at the end of some of the arrays are UnsignedLongWords that record the index of the last string in the array; be sure to keep those up to date. (The use of those UnsignedLongWords is a little confusing, but if the last string in any given array is commented "/* 42 */", then the corresponding UnsignedLongWord value should also be set to "42". This numbering is a historical artifact of the way things were done in the old, old, old Macintosh Toolbox.)
We can now complete our block of code in "SchemeFunctions3.c++", so that it looks like this:
/**** incrementCode -- increment the argument by one. ****/
PROC( incrementCode )
PUSH
MOVE( one, R )
ADD
CONTINUE
END_PROC
functionDescriptorTypeOne incrementFD = { incrementCode, 378, TRUE, numberP, numberBitsMask, 1, numberChecker, numberCheckerNames };
Now we have to put entries for "incrementFD" and "incrementCode" in various places so those items will be visible in files that need them, and so that they are included in tables that are built up for Wraith Scheme to use at run time.
In the include directory, there is a big externals file, called "FunctionAndSpecialNames.e", which contains all the externals for the various SECD "assembly language" routines that implement procedures and special forms. We need to put an entry for "incrementCode" there. All that is in that file is a big extern statement:
extern void
leafPCode(),
assocCode(),
assqCode(),
assvCode(),
...
setForgettableTimeCode(),
setForgettableRememberProbabilityCode();
You can put "incrementCode()" into it anywhere you like. Be careful about those commas and that final semicolon.
The world handler maintains a big table of pointers to code that implements primitives. We must put a pointer to "incrementCode" into that table, at the end. The table is in file "WorldHandler.c++", near the top, and is unimaginatively called "codePointerTable". As I write these words, the end of it looks like this:
/* 455 */ (UnsignedLongWord)setForgettableTimeCode,
/* 456 */ (UnsignedLongWord)setForgettableRememberProbabilityCode,
/* 457 */ (UnsignedLongWord)leafPCode,
};
What we do is add a new entry at the end, like this:
/* 455 */ (UnsignedLongWord)setForgettableTimeCode,
/* 456 */ (UnsignedLongWord)setForgettableRememberProbabilityCode,
/* 457 */ (UnsignedLongWord)leafPCode,
/* 458 */ (UnsignedLongWord)incrementCode,
};
Once again, bear in mind that file "WorldHandler.c++" may have changed since I wrote these words.
We also have to put an entry for the functionDescriptor "incrementFD" in two places. The first one is the externals file for all function descriptors, which is "SchemeFunctionExterns.e", in the include directory. It has a long extern declaration, "extern functionDescriptorTypeOne ...", to which "incrementFD" must be added. There is no reason to keep the declarations in any particular order, just be careful that the commas and semicolons are all in the right places.
extern functionDescriptorTypeOne
acosFD,
asinFD,
...
floorFD,
GCDFD,
incrementFD,
inexactPFD,
inexactToExactFD,
...
sqrtFD,
tanFD,
truncateFD,
zeroPFD;
The other place we put the functionDescriptor is in "SchemeFunctions.c++", where there are two lists of functionDescriptorTypeOne, in a peculiar format. (The reason why there are two lists instead of just one is that I once found what appeared to be a bug in initializing big arrays that occurred when an array had 256 values in it -- or maybe 255 or 257. I do not know whether the bug is still there, but as a workaround, I split the list of functionDescriptorTypeOne into two parts.) As I write these words -- and things may have changed since -- the end of "functionDescriptorTypeOneListB" is:
{ 1, &forgettableRememberProbabilityFD },
{ 1, &setForgettableTimeFD },
{ 1, &setForgettableRememberProbabilityFD },
{ 1, &leafPFD },
{ 0, (void *)NULL }
};
We have to alter it, perhaps like this:
{ 1, &forgettableRememberProbabilityFD },
{ 1, &setForgettableTimeFD },
{ 1, &setForgettableRememberProbabilityFD },
{ 1, &leafPFD },
{ 1, &incrementFD },
{ 0, (void *)NULL }
};
With those changes, Wraith Scheme now compiles, but we also need to build a new world that contains the new procedure. In the Wraith Scheme source directory, the commands to do so are
make ws_tty_64 make new_world_64
After that, we can recompile the Macintosh implementation of Wraith Scheme (it may help to do a full clean of that build first), start it running, and then type:
(e::increment 42)
and get
43
If the new procedure were going to be a permanent change to Wraith Scheme, we would have other things to do; we would want to augment the various tests of Wraith Scheme to make sure that the procedure worked with a variety of numbers, and that it correctly reported such errors as being called with the wrong number of arguments, or with an argument that is not a number.
We also would probably wish to augment the static tables that Wraith Scheme uses for command-name completion and for providing syntax information. As I write these words, they are in a file called "WraithSchemeControllerAndModel.mm", as long inline code sections in procedures "createCompletionArray" and "createSyntaxArray". The relevant entries would simply be
@"e::increment"
in the former array, and
@"e::increment <number>"
in the latter.
Incidentally, procedure "e::increment" is not part of the Wraith Scheme that I deliver. I have only created it and tested it temporarily, to make sure that this example was correct. Note also that we have arranged that "e::increment" will accept arguments that are complex numbers with non-zero imaginary parts, which might not be what many people expect an "increment" function to do: There is no escaping the fact that there are often design decisions to be made when a new procedure is implemented. For example, we could alternatively have used a type-checking predicate that only accepted real numbers.
When I speak of initializing Wraith Scheme, I have in mind the Cocoa implementation. The TTY and NCurses implementations have much simpler initialization processes. I will mention them mostly in passing.
Recall that the Macintosh Cocoa implementation features two parts. One comprises the view and the controller (or at least half of the controller) of the standard Macintosh model/view/controller kind of application. That part is pretty much a conventional Macintosh application, using Objective C, Cocoa, and lot of other tools from Apple's development environment. It is not hugely complicated. Unfortunately, in places it is rather clumsy -- it was, after all, my first Cocoa application.
In any case, I cannot talk about that part of the program without assuming that you know at least a little about these Mac-ish topics. You don't have to be an expert -- I certainly am not -- but if you are a complete stranger to contemporary paradigms of Macintosh development, the going in this section might get a little difficult. Your difficulty may be compounded by the fact that the code necessarily reflects my own inexperience with Cocoa.
Wraith Scheme is normally launched by mousing on it, like any other Macintosh application, but there are some provisions in the file where "main" lives -- that is file "WraithScheme.64/WraithCocoa/main.mm" -- for dealing with command-tail arguments. They are there for two reasons. First, many tests in the test suite for Wraith Scheme launch the Wraith Scheme application from the command line. Second, the way multiple instances of Wraith Scheme are launched for parallel use is that the MomCat uses the Unix "system" call to launch all the kittens from the command line, and some of these flags must be passed to the kittens so that they will know how to set themselves up.
If you happen to look at "main.mm", you will notice that the otherwise-conventional use of the Unix function "getopt" seems to recognize a lot more options than Wraith Scheme actually uses. The reason those are there is that I once found empirically that when Macintosh applications are launched by mousing on them, something gives them a command tail, and I wanted to make sure that my argument-parsing routine did not interfere with other options. Note clearly, that if Apple should ever change what it passes in the command tail at launch time, Wraith Scheme will break.
In any case, what "main" does, is to copy argc and argv to globals, then parse the command tail to set some more globals, then do some simple initialization related to memory-mapping, and only then get around to calling the Cocoa function "NSApplicationMain", which is what usually does all the work of launching a Macintosh application.
The memory-mapping initialization code is where it is only for historical reasons. The functions called are in "source/MMapStuff.c++", which in turn makes use of "source/MemFill.s" -- an assembler file that declares two great lumps of zero-filled data, and those functions are pretty simple. They used to be more complicated, and at the time had to called first thing in "main", but that is no longer the case. All the functions do is set up some pointers into the address region that is going to be mmapped; the actual mmapping itself does not take place till much later.
The Cocoa side of Wraith Scheme initializes itself in the usual way -- there are a handful of "init" methods here and there. There are a few "applicationDidFinishLaunching" methods as well, though, notably in "WraithSchemeOuterController.mm". (That file and class are too big and too cumbersome; I should probably break them into pieces.) That method is lengthy, but I think mostly straightforward, so I will describe only the odd or unusual points, of which there are several.
if( isMomCatP && hasWorldToOpenAtLaunch ) {
contains code to check that all is well if the user has launched Wraith Scheme by mousing on a world file. All this code does is make sure the file exists, and set up some things about it for the Scheme machine to use. Incidentally, the bool "hasWorldToOpenAtLaunch" is set to true in
- (bool)application:(NSApplication *)theApplication openFile:(NSString *)filename {
which is a delegate method that will be called whenever the user mouses on a document of a kind the application is supposed to handle. Wraith Scheme only handles world files that way, and only one of them, and only at launch time, so all this method has to do is record data about the file for subsequent use.
The next possibly unusual thing is
[NSThread detachNewThreadSelector:@selector(runEvaluator:) toTarget:self withObject:nil];
which starts up a thread with the Scheme machine running in it. In that thread, method "runEvaluator" does some memory management miscellanea,
- (void) runEvaluator:(id)theObject {
NSAutoreleasePool *thePool = [[NSAutoreleasePool alloc] init];
runSchemeWithPathAndMemory( globalArgv[0], mainMemorySizeInUse ); // Never returns ...
[thePool release]; // It never returns, but just in case ...
}
and then calls "runSchemeWithPathAndMemory", which is over the fence, in the Scheme machine, in file "source/MainAux.c++".
The initialization of the Scheme machine of each of the one or more Wraith Scheme Unix processes that are launched as an instance of the Wraith Scheme Cocoa implementation is coordinated through code in the source file, "MainAux.c++". That same file -- and much of the same code -- is used to coordinate the entire initialization of the single Wraith Scheme Unix processes that constitute the Wraith Scheme TTY implementation and the Wraith Scheme NCurses implementation.
The entry point into "MainAux.c++" for the Wraith Scheme Cocoa implementation is, as we have seen, "runSchemeWithPathAndMemory", and the "main" routine that starts that implementation going is in the WraithCocoa directory, in "main.mm". There is another "main" routine, in source directory file "Main.c++", which is used as the starting point for the TTY and NCurses implementations. (The Wraith Scheme Cocoa implementation simply does not compile and link that file.) All that the other "main" routine does is call a routine that does memory-mapping -- again, it is called that early for reasons that are merely historical -- and then call a different entry point in "MainAux.c++"; namely "runSchemeWithArgcAndArgv".
It turns out that each of these two entry points is simply an interface between the particular "main" routine and the real, single, common-point initialization routine for the Scheme machine. That routine is "runSchemeWithArguments", and it is also in "MainAux.c++". The way that design worked out was that first, I wanted to keep the top-level initialization code in one place for ease of maintenance -- hence I did as little processing as I could before entering file "MainAux.c++". Second, the different implementations required slightly different command-tail processing -- hence the use of two different entry points.
The command tail processing that is handled separately by the two different entry points in "MainAux.c++" deals with two things: First, the TTY and NCurses implementations both have the option of using a special initialization file, that the Cocoa implementation does not use. Second, both implementations need to know the path to the place where the application was launched from, but the path that is provided to the application by Mac OS when you mouse on an application is not the same as the path to where the user found the application in the first place. The executable code for the application is buried a couple of directory levels inside the ".app" entity (which is a renamed directory); the code in "MainAux.c++" has to strip off the last couple of pieces of the path.
In any case, "runSchemeWithArguments" sets a couple of longjmp targets for error recovery, and calls a portmanteau of other initialization routines. Then it loads the world, if possible, and waits till the graphical user interface is initialized -- that would be the Cocoa stuff in the Cocoa implementation, but is the relevant test global is simply set to "TRUE" in the other implementations.
With the GUI initialized, "runSchemeWithArguments" prints the Wraith Scheme "banner", and then, if there are parallel instances to launch, the MomCat launches them -- more about that later, but recall that the TTY and NCurses implementations are single-process only -- no kittens. Next come some more messages, the posting of a handful of startup events, the setup of a longjmp target for recoverable errors, and -- at last -- a call to the code to run the top-level loop.
Function "runTopLoop" is also in MainAux.c++. By the time it is called, the Scheme machine is pretty functional, but there are still some decisions to be made. If a world has just been loaded, there is code here to figure out if it contained a function that was supposed to be evaluated upon loading the world, and to do so in that case. Alternatively, if there has been no previous attempt to load an initialization file, and one is present, there is code to do that. Finally, the longjmp target for the debugger is reset, and then is the call to the never-returning evaluator.
It is worth pointing out that two of the first few lines in "runTopLoop" are crucial. They are
MOVE( TLC, R ); CSPushProperList();
TLC is a register in the SECD machine. It doesn't stand for "tender loving care", it stands for "top-loop code", and it contains a pointer to a list of the instructions it takes to run the Wraith Scheme top-level loop. "CSPushProperList" pushes those instructions into the continuation. The instruction that ends up getting executed last will cause the top-loop code again to be pushed into the continuation -- that is how the top-level loop is made to loop. The C++ code that sets up this list of instructions is in file "SchemeGlobals.c++", near the end of function "loadSchemeGlobals".
The basic plan for how multiple Wraith Scheme processes get going is that the Scheme machine C++ initialization routine, "runSchemeWithArguments" contains a loop wherein the MomCat launches the other kittens sequentially. To keep things simple, I make no attempt to launch in parallel -- the MomCat waits till each kitten has reported that its graphical user interface is initialized, before launching the next one. (I will discuss how the synchronization works shortly.)
The actual function that does the kitten launch is "launchInstance", which is in "MainAux.c++". It gathers together the appropriate command-tail arguments (which include the kitten number of the kitten-to-be), and puts together a string to use as the argument to the Unix "system" function. That string uses the absolute path to the MomCat, taken from argv[0], to be sure it gets the same copy of Wraith Scheme. There is a retry loop in case the launch fails for some reason, and more synchronization, but all that really counts is just careful use of the "system" function.
Initialization of even a single instance of the Wraith Scheme Cocoa implementation requires coordination between the thread that runs the GUI and the thread that runs the Scheme machine; for example, the Scheme machine should not print any output to the GUI until the GUI is sufficiently well set up to handle it. Initialization of many such instances to run in parallel requires that the instances keep track of each others' progress, at least sufficiently that they can all agree that they are all ready to operate. The clowder provides a way for the various threads of the various processes to record their progress through initialization in a piece of shared memory where all threads of all processes can look at it.
The specific data structures used are two arrays, each with as many items as there are Wraith Scheme processes and indexed by kitten number, which are loaded with enumerated types to indicate initialization progress. The first array is "KittenEvaluatorActivity" and the second is "KittenGUIActivity". The first records initialization progress for the Scheme machine; the second for the GUI. Declarations of those arrays and of the functions to set and get them are in the include file "Clowder.h".
One detail in initializing the GUI side of the Cocoa implementation is much messier than I would like, and requires some explanation. Initialization requires careful synchronization of data exchanges between the GUI and the Scheme machine: The problem is that several of the initialization steps require the GUI to send a message to the Scheme machine, and for the Scheme machine to send a message back to the GUI. The inter-thread message passing system that I implemented requires that such messages be sent in strict alternation -- GUI-to-Scheme-machine, then Scheme-machine-to-GUI, then GUI-to-Scheme-machine ... -- with the possibility of deadlock if strict alternation is not observed. Furthermore, one obvious solution does not work. Any solution along the lines of
...
send message 1
while( answer to message 1 is not received )
sleep();
send message 2
while( answer to message 2 is not received )
sleep();
...
doesn't work because the GUI becomes unresponsive to other user events while it is spinning through the while loops. Apple justly recommends some sort of event-posting mechanism. (Note in passing that I did not want to post Cocoa-style events from the Scheme machine because that would tie the code used in the Scheme machine too closely to the Macintosh architecture; I wanted that code to be as general as I could make it.)
What I ended up doing was the following: At the end of method "applicationDidFinishLaunching", in WraithCocoa directory file "WraithSchemeOuterController.mm", I launch two series of what I might describe as never-ending-penny method calls. What happens is that I create a non-repeating timer event, that will happen in the near future, that calls a method that first does something useful and then posts another non-repeating timer event of the same kind.
Once again, the reason for this peculiar construction is to avoid deadlock. If I had used a timed event that repeated automatically, or had dispatched a whole lot of timed events at once, there would be a possibility that two messages to the Scheme machine would be active at once, which might cause a deadlock. (There might also be a possibility of initialization actions happening in the wrong order, which is also not good.)
The first series is initiated by method "startController", which is also in file "WraithSchemeOuterController.mm"; what the method called there does is look to see whether the Scheme machine has anything for the GUI to do, and do it, and then post another timed event, to happen in the near future, that calls the same method. By posting timed events this way, the GUI thread gets to do other things while waiting for the next timed event to go off.
The second never-ending-penny series does actually end. The method that creates new timed events is "doControllerInitializationTask", and the method that does the real work is "controllerInitializationTask". These two methods are tasked with completing GUI initialization tasks in synchronized sequence. They maintain a global counter for what to do next. The first method, "doControllerInitializationTask", initializes the counter. The second method, "controllerInitializationTask", uses that counter as the basis for a switch, each case of the switch handling a particular initialization task, and updates the counter as the various tasks are accomplished. Some tasks are merely time delays; they take more than one call of "controllerInitializationTask" before they complete. Method "controllerInitializationTask" returns "NO" when there is more work to be done, and "YES" when all initialization tasks are finished. Method "doControllerInitializationTask" uses that returned boolean to decide whether to fire off another timer or not.
To avoid deadlock, it is necessary that each pass through "controllerInitializationTask" send at most one message to the Scheme machine. The fact that "doControllerInitializationTask" dispatches its own successor timed event thereby guarantees that there are never two messages to the Scheme machine in the queue at the same time.
That is messier than I would like, but it does get the job done, and the rest of the GUI stays responsive during the process. It would be easy to modify "controllerInitializationTask" if more initialization tasks were required.
The general approach to building a new version of Wraith Scheme is:
The top-level Wraith Scheme commands to do these things are contained in file "WorldBuilding.64.s", which is in the "SchemeSource" directory, which is used by the source Makefile in target "new_world_64". Most of the commands in that file are file loads. The loads are interspersed with commands to display progress information as the process proceeds.
The first block of loads in "WorldBuilding.64.s" are simple loads of source code which has already had most of the macros it contains expanded. That is, the files loaded -- which all have the string "Expanded" as part of the file name -- are not the actual source code files; rather, they are derivations which have been passed through the bootstrapping process discussed earlier, and saved in files.
There are ten such files. The code in them that is required in the early part of the world-building process is free of those Scheme constructs which are implemented by expanding hygienic macros. That is well, for the hygienic macro system is not in place in Wraith Scheme at the time these files are loaded. Rather, loading those files creates it. They also create the Wraith Scheme compiler and several other systems as well.
Some code in those files has not had its hygienic macros expanded. That code is not required in the early stages of world-building; the macros therein will be expanded in a later stage of world-building.
Files in this block of loads must be loaded in a careful order, for many depend for their execution on the presence of functions in one or more of their predecessors. When the entire block of files has been loaded, all of the procedures and special forms that are not implemented as primitives in the Wraith Scheme C++ source code, that are required to make a complete default world for Wraith Scheme, are in place in Scheme main memory, but there is more to do: The procedures are interpreted, some have not had hygienic macros expanded, and they are not yet properly organized into the three-tier environment system required by the R5 report.
File "EnvironmentManipulation.s", also in the SchemeSource directory, is next loaded. It places the various items in the appropriate environments. With that done, the procedures written in Scheme must be compiled.
Compilation is performed by the procedures in file "CompileStuff.s". Those procedures are organized into thirty-four steps, with a progress message displayed at the end of each step. The locations of the progress messages are obvious at a glance when reading "CompileStuff.s".
The first eleven steps systematically use the macro-expansion system to expand macros in any of the loaded functions for which that has not yet been done.
Steps twelve through twenty-two systematically compile all the loaded procedures -- which now no longer contain any unexpanded macros. This process involves compiling both the macro-expander and the compiler itself; it speeds up noticeably as different software comes on-line in compiled form.
Step twenty-three makes permanent the binding between each procedure and the symbol which is its name. Steps twenty-four through thirty-four take advantage of the new permanent state of these functions, by going through the compiled functions and substituting the actual binding of any permanent symbol for the symbol name itself; compiled code thereby does not need to look up the bindings of these symbols in the environment list every time it runs.
After the load of "CompileStuff.s" has completed, control returns to "WorldBuilding.64.s", which does not have much left to do. It performs a bunch of garbage collections, in order to give the stochastic mechanism of cdr-coding plenty of chances to compact lists. Then it evaluates '() several times, to clear out the top-level loop variables which record the last inputs to and outputs from the top-level read/eval/print loop. Finally, it saves the new world, and exits.
The code for the Wraith Scheme compiler is all in subdirectory "Compiler" of "SchemeSource". There are really only two files that matter, "ConstantsAndPrimitives.s", and "ReleasedCompilerCode.s". The former contains constants and a few relatively simple low-level procedures; the latter contains more complicated procedures.
Elsewhere I describe the Wraith Scheme compiler as compiling things to threaded code. That is true, but it isn't much of a claim -- interpreted Lisp-class languages are generally excellent instances of threaded code; any substantial item in the continuation is likely to be some kind of tree structure, full of pointers to different subtrees that may at some time get their own turn in the continuation.
Wraith Scheme can only compile lambda expressions, and when it does that, it does the following things in the following order:
Actually, that isn't quite right, but it is close. What happens is that the compiler goes through the body of the lambda expression -- perhaps including nested lambdas -- and, where it finds a variable name that is a formal parameter to one of those nested lambdas, it substitutes something else for the variable name.
The "something else" is a special type of tagged aval -- an "environment reference" that tells where the variable's actual value will be in the environment list at run time -- it contains two half-word-sized integers, one to tell how far down the list of environments is the environment where the variable value will be, and the other to tell which item in that particular environment will be the actual value. This substitution makes finding the variable value at run time much faster than going through all the environments looking for it by name.
The high level view of the code that does all this is in procedure "c::compile-interpreted-lambda". That procedure is near the end of file "ReleasedCompilerCode".
Wraith Scheme actually has two macro systems. The first is a traditional implementation, that dates from before the current Scheme hygienic macro system was developed. The second is an implementation of hygienic macros as defined in the R5 report, that is in part based on the older implementation.
The traditional macro system works as follows: A Wraith Scheme traditional macro is in essence a lambda expression by another name: It is an instance of a tagged aval whose tag is labeled as type "macroTag" and whose aval is a pointer to an S-expression that Wraith Scheme would treat as a lambda expression, if only that tag had been of type "lambdaPairTag". That lambda expression expects a single argument.
When the evaluator encounters an S-expression, it first evaluates its car, before deciding whether or not to evaluate any of the other elements of the S-expression. If the car should evaluate to a traditional macro, then the evaluator makes a local copy of the macro tagged aval, changes its type to "lambdaPairTag", and calls that lambda expression with a single argument, which is the entire S-expression.
The lambda expression can do whatever it likes with the S-expression. What traditional macros are about is providing a regular, uniform ability to process an S-expression without first evaluating all of its elements. Note carefully the difference:
(foo bar baz)
It will evaluate "foo", note that the result is a lambda expression or a built-in procedure, evaluate all the rest of the items in the S-expression, and will then in effect apply the lambda expression or procedure as follows:
(apply evaluated-foo '(evaluated-bar evaluated-baz))
(foo bar baz)
the application will in effect be
(apply evaluated-foo '((foo bar baz)))
The procedures and special forms whereby Wraith Scheme deals with traditional macros are all built-in; that is, they are implemented in C++ code, using the assembly language of the Wraith Scheme SECD machine. That code is for the most part in the "source" directory, in file "SchemeSpecials.c++".
Wraith Scheme's entire hygienic macro system is written in Scheme. The implementation is contained mostly in file "R5Macros.s", in the "SchemeSource" directory, with a few forms in "HygienicMacros.s", in the same directory. Note that these files are among those involved in the bootstrapping process.
The Wraith Scheme hygienic macro system implements R5 hygienic macros by producing traditional macros. That is, if you use a hygienic-macro-system form such as
(define-syntax my-favorite-macro (syntax-rules < all the right stuff >))
and then investigate what kind of Wraith Scheme object is bound to symbol "my-favorite-macro", you will find that the bound object is a traditional macro. Thus if you later call
(my-favorite-macro foo bar baz)
then the lambda expression associated with "my-favorite-macro" will in effect get passed '(my-favorite-macro foo bar baz), just as discussed above, and will do something with it. It is the job of the Wraith Scheme hygienic macro implementation to construct that lambda expression so that it implements your chosen syntax rules in the hygienic manner called out in the R5 report.
You might thereby think of such a hygienic macro implementation as a kind of preprocessor. It goes to a lot of work to make sure that the right variables get bound at the right times and all, but what it ultimately produces is an old-style macro that does the actual work of transforming your hygienic macro call in accordance with the syntax rules.
I am not entirely pleased with the Wraith Scheme hygienic macro implementation. To be a little more honest, the code for it is a mess. I keep thinking that there is a better way to do it. I keep thinking that I should rewrite it, but I am utterly and truly sick of this code, so I have no problem coming up with excuses to procrastinate. The start of "R5Macros.s" is another one of those places where I should probably put the stereotypical warning, "Abandon hope, all ye who enter here." Yet fools rush in where angels fear to tread, so let me see if I can get you going at making sense out of that code.
If you start reading "R5Macros.s" from the top, you will be beguiled into a false sense of confidence. The first three hundred lines or so of that file are all very simple simple stuff -- predicates, constructors, setters, getters, and the like -- all pretty much based on the discussion of macros in sections 4.3 and 7.1.5 of the R5 report. I knew I was going to need them, so I wrote them first, while I was putting off the hard part of the implementation.
When you get to the end of the easy part, then go to the end of the file and start working backward. I have the C programmer's habit of putting auxiliaries before the functions that need them -- that avoids "forward" declarations -- so a top-down read of my code often involves a bottom-up read of the file wherein it resides.
So for example, near the bottom of "R5Macros.s" is the code for "syntax-rules", which is itself implemented as a macro. It acts on the "rules" provided by the user, by capturing the environment that is current as the hygienic macro is being created, and passing both it and the rules to "c::syntax-rules-code", a bit further up in the file. That function calls a number of auxiliaries to pull various data structures out of the rules, very carefully checking for correct syntax as it does so.
A particularly important auxiliary of "c::syntax-rules-code" is "c::make-partial-transformer". In essence, deals with the fact that some of the variables used in the hygienic macro template defined by the user may be bound in the environment that existed as the hygienic macro was defined. It creates a lambda expression that will further expand the hygienic macro definition when the hygienic macro is "called", possibly in a very different environment from the one in which it was defined.
The user may of course have provided more than one template for a given hygienic macro. For example, the Wraith Scheme implements "if" as a hygienic macro with two forms, "(if test consequent)" and "(if test consequent alternative)". So what "c::make-partial-transformer" must do is construct a lambda expression, to be evaluated at hygienic-macro-call-time, that will take the actual S-expression in which the user tried to use the hygienic macro and either use the correct partial transformer to expand it, or -- if no template matches the S-expression -- report an error.
Thus in the case of "if", the expansion of
(if test consequent)
is
(c::if test consequent #f)
in which "c::if" is a Wraith Scheme built-in special form that handles an "if" S-expression that has a test, a consequent, and an alternative. The expansion of
(if test consequent alternative)
is
(c::if test consequent alternative)
An attempt to expand
(if test consequent alternative cant-make-up-my-mind)
results in the error message and handling:
Form: (if test consequent alternative cant-make-up-my-mind) Problem: That use of macro "if", matches no pattern for the macro. (That is, that's not how "if" is supposed to be called.) (Resetting) Top-level loop ...
The code that handles that error and prints the given message is very nearly at the end of "c::syntax-rules-code".
The hygienic macro implementation uses an elaborate mechanism to find and record the locations of variable references in the syntax rules that the user has provided. The function "c::pattern-variable-structures" and its auxiliary, "c::pattern-variable-structures-aux" do this by "walking" the rules and keeping track of how it got to where it is -- by a sequence of cars, cdrs, and vector-references. Procedure "c::follow-directions-and-return-result" uses that representation. This mechanism is used in substituting the values of variables at places where the variable identifiers occur in the syntax rules of a macro, and there is much complexity involving the presence of ellipses ("...") in those rules.
The code uses a structure called a "syntax-binding". There is in fact a Wraith Scheme tagged aval whose type is "syntaxBindingTag", defined at the C++ level just for use in the hygienic macro system. There are also some primitives for manipulating them. A syntax binding is a retagged list of four items
The abbreviation "sb" for "syntax-binding" is common in "R5Macros.s".
The code uses a structure called a "pattern-variable-structure", which pertains to the circumstances in which a variable occurs in the pattern portion of a syntax rule. This structure has six elements, and is implemented as a list. The elements are
I think -- but I am not quite sure -- that no value higher than two can occur. The macro implementation will in any case complain if it finds one.
There is a lot of complicated, messy code in "R5Macros.s". I hope the preceding remarks are enough to get you started, if you are bold enough to try to read and understand it.
This section is included only for readers who are interested in very early versions of Wraith Scheme: It does not apply to versions later than 2.25.
Apple once supported a system of four-bite "creator codes" whereby Macintosh applications and their specialized documents could identify themselves to each other and to various components of Apple system software. Early versions of Wraith Scheme used creator codes. For example, they were part of the mechanism whereby Mac OS knew to open Wraith Scheme when a user clicked on a Wraith Scheme saved world.
Wraith Scheme creator codes that start with the letters "cld" identified the Wraith Scheme application. Wraith Scheme creator codes that start with the letters "kdl" identified world files. (Those three-letter strings are abbreviations: "cld" is short for "clowder", a rather archaic term for a group of cats, and "kdl" is short for "kendle", an equally archaic term for a litter of kittens.) The identifiers used in versions of Wraith Scheme 2.00 through 2.25 are "cld4" and "kdl4". (The corresponding identifiers using '1' and '2' were for versions of Pixie Scheme, and the ones with '3' are for the 32-bit version of Wraith Scheme.) Those identifiers were used in three places in the source for the Cocoa Implementation.
const OSType WraithSchemeCreatorCode = 'cld4'; const OSType WraithSchemeDocumentTypeCode = 'kdl4';
Many implementations of programming languages provide an implementation of some kind of "package" system, with the dual goals of not cluttering up the namespace and of providing a sane way to deal with situations when two libraries or other modules of code use the same name for different purposes. Wraith Scheme has such a system, but to skirt possible cognitive dissonance, I have consciously avoided such common names as "use", "require", "import" or "export" for its procedures.
Wraith Scheme's package system comprises some new functions with the following goals:
The procedures operate very simply, given the description herein of how Wraith Scheme manipulates environments. In terms of the language used in the Environments and Environment Lists section of this document, what the package procedures do is simply create a new block environment when they start to run, that is consed onto the head of either the top-level environment list (in the procedure that loads packages into the top-level environment), or the environment list that obtained where the package procedure was called (in the procedure that loads packages into the calling environment). All expressions evaluated during the load of the package's file are evaluated using the environment represented by that extended environment list, so that "define"s in the package file result in bindings being created in the new block environment, and so that resolution of bindings is done by checking the new block environment first.
When a lambda expression is evaluated with the environment list set up that way, then the new block environment is one element of the lambda's environment list. Thus if one procedure defined in the package file uses another procedure defined in the file -- or any other symbol binding created in the file -- it will find that binding in the new block environment before it looks in any part of the environment into which the package was loaded. Thus the lookup will find symbol bindings for the package even if they were not exported, and will not be confused if there are any other bindings of the same symbols in the environment into which the package was loaded.
Symbols are exported by using various Wraith Scheme procedures (some publicly declared, some not) to find symbols and their bindings in an environment of choice, rather than in the standard way. Wraith Scheme has plenty of primitive procedures for doing things like this.
The package procedure that exports to the calling environment may be used when one package needs to use another: Suppose that package A needs procedures from package B. The file representing package A might thereby contain within it a top-level invocation of the package procedure that exports symbols to its calling environment, to load the file representing B and export some of its symbols into the environment where the file for package A is being loaded.
Since I first wrote the section on package management, there has been much discussion in the Scheme community about providing a standard "library" mechanism for Scheme implementations to use. Wraith Scheme's "package" system in many ways resembles those "library" systems, and may be used in many of the same ways, but the details of its implementation and the syntax involved in using it are different.
My parents were both architects, and were concerned not only that their products -- building designs -- be well engineered in the sense of structure and mechanical function, but also that they look good and be easy to use. Perhaps because of that heritage, I rather enjoy designing the user interfaces of computer programs, and I do try to make them both good looking and easy to use. Since I have created some three or four fairly distinct user interfaces for my family of Scheme interpreters, I thought it might be appropriate to include a section outlining how and why I developed them the way I did.
Just about the first devices that allowed a user to interact in real time with a computer program were teletypes -- electromechanically driven typewriters that printed text, one line at a time, on a long, continuous roll of paper that scrolled out of the machine and spilled across the floor. That paper typically had interleaved on it both what the user had typed to the computer, by way of the teletype's keyboard, and what the computer had typed back.
Teletypes were still in common use in the early days of the Unix operating system -- I remember them well. Thus it is no surprise that Unix and many other operating systems in use at that time had application programming interfaces (APIs) that allowed a program to interact with a teletype easily. They included the standard text input and output ports, "stdin", "stdout", and "stderr", and the Unix "terminal shell".
Those APIs were of course carried forward when computers stopped using teletypes and started using more advanced devices, such as cathode-ray tubes and liquid-crystal displays, for output. Virtually all the computer operating systems and software-development environments in the world make it easy for a program to get character input from a keyboard and print character output to a scrolling text window that is visible on some kind of console.
The teletype API is not only common, but also easy to use, so it is often a natural choice for the early development stages of any program that involves interacting with text. In particular, if you are using the common model/view/controller design pattern for a big text-oriented program, it is often easy and useful to start out with a simple teletype metaphor for the view to get things going, and add a more complex view later on.
I have done that twice: In the mid 1980s, when I brought up the original Pixie Scheme on my Mac II, I first used a terminal shell mechanism, provided by Apple's Macintosh Programmer's Workshop, to get things going, and then later put in a more complex view that used the Macintosh Graphical User Interface (GUI) as it then existed. (I will discuss the latter interface a bit later.) Then, in late 2006, when I started porting Pixie Scheme to what would become Wraith Scheme, the first thing I did was rip out the interface to the Mac GUI of the 1980s -- which had by then become extinct -- and install a stdin/stdout/stderr interface to a garden-variety Unix shell -- a window of the Macintosh "Terminal" application.
Wraith Scheme running in a Macintosh Terminal shell.
The latter terminal-shell user interface is still there. One of the Makefile targets for Wraith Scheme builds a simple version (non-parallel -- just the Momcat) that runs in a Terminal window. I made it part of the Wraith Scheme source code distribution because that version of Wraith Scheme is probably only a few simple code changes away from running on any Unix system in the world, even one that still happened to be using a teletype.
One variant on the simple teletype API came along with the start of character-based display terminals. With these, it was possible to treat the entire display -- typically 25 rows of 80 characters each -- as a modifiable text area, and one of the common patterns of doing so was to have a line or two of status information of some kind always available as the rest of the display changed and scrolled around. Many text editors and word-processing programs work that way today. When I was porting Wraith Scheme to the modern Macintosh, I used the popular "ncurses" package, that allows character-by-character access to an entire screen of text, to create such an implementation of Wraith Scheme. I put the status lines at the top, and I did not strictly use status lines -- I used one line of reversed-color text for messages from Wraith Scheme to the user, and two more lines for a prompt-and-response dialog area, in which Wraith Scheme could ask the user for a line of text and the user could enter it. The rest of the display area still worked like a teletype, with the virtual roll of paper scrolling out of sight under the status lines (but there was a way to scroll back and see what was there).
Wraith Scheme running in a Macintosh Terminal shell, using "ncurses".
That interface is also still there -- there is a target in the Wraith Scheme Makefile to build it. Most Unix systems have ncurses handy, so it is also probably not far from running on any Unix system in the world.
Technical Note: Fair warning: I could never get the procedure running whereby ncurses resized the window into which it typed characters. That procedure needs to be called whenever the user resizes the visible window of Apple's "Terminal" application in which the Wraith Scheme "ncurses" implementation is running. I was never sure whether the bug was in my code or Apple's, and I never tried very hard to fix it.
As you can probably tell from the images, the teletype and ncurses implementations provide relatively straightforward ways to run Scheme code, but how do you control the Wraith Scheme program itself, as opposed to the Scheme machine that is part of it? That is, how do you tell the program to quit, or set various mode bits? There are some enhancements -- extra procedures I have provided -- that do many of those things, but you do occasionally need a way to talk to the program without going through the Scheme machine. I set it up so that typing a control-C to either of these implementations brings up a few lines of text output and gives the user a chance to type a one-character control command. Here is a screen shot of that mechanism in action, just after the user has typed control-C.
Be aware that for reasons I never bothered to investigate, users of these interfaces may have to type press the "Return" or "Enter" key after typing control-C, to get Wraith Scheme to acknowledge the control-C.
The control interface for the Wraith Scheme teletype and ncurses implementations.
This control interface is rudimentary and incomplete, and calling it the "Wraith Scheme Instrument Panel" is probably misleading, but my main purpose in doing both of these implementations was to get the Scheme machine itself going again, and to do so I needed a way to control the program. This approach worked satisfactorily.
I decided to use a variant of the teletype API as a major component of the GUI for the full-Macintosh version of Wraith Scheme, even though a number of other approaches were available (and I will discuss those later). What Wraith Scheme does is to use two scrolling text windows -- two rolls of teletype paper -- with one roll partly hidden behind the other. One scrolling window contains only what the user has typed; it is a command history for the current session of Wraith Scheme. The other window contains both what the user has typed and what Wraith Scheme has typed, in proper sequential order; it is a complete transcript of the current session.
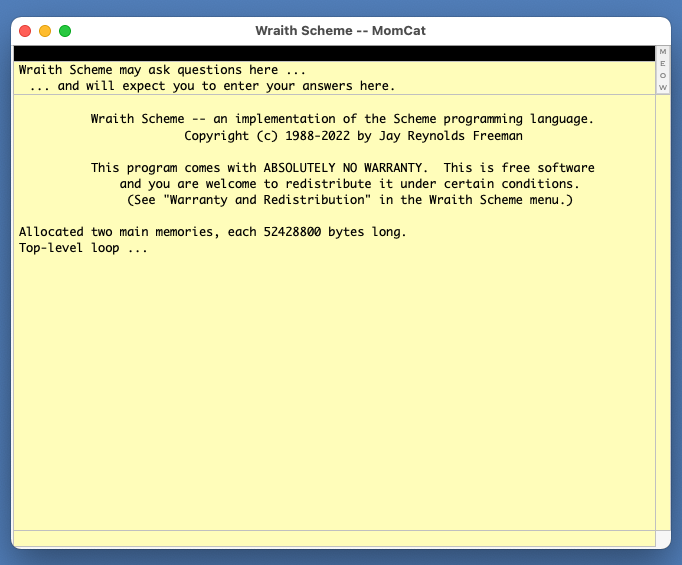
The Wraith Scheme main window, without the accessory panels.
In the image above, only one line of the command-history text window is visible: It is the wide yellow box that is only one line tall, at the bottom of the window, with a thin black line drawn around it. That one line is also where the user types input to Wraith Scheme, one line at a time. That line is what I have called the "Wraith Scheme Input Panel" in other documentation. The rest of the command history is hidden: It scrolls up behind the other parts of the window, but there are ways to scroll the window to see and recover previous commands.
In the same image, the text view for the complete transcript fills most of the window; it is the much larger yellow box, which I have called the "Wraith Scheme Main Display Panel" in other documentation. It is positioned so as to give the illusion that there is only one scrolling view: When the user types a line of text into the Input Panel, and then presses the return key, that text immediately appears at the bottom of the Main Display Panel, right where it would have been if the press of "return" had merely scrolled a single big field of text. This mechanism presents a visual interface to text that will be very familiar to anyone who has ever used any program with a teletype-style interface, or even to anyone who has ever typed lots of text into a simple text editor or word processor, yet using two scrolling windows instead of just one makes it easy to keep a command history that is separate from the complete transcript. The overall effect looks like this:

Two scrolling windows masquerading as one.
In the image above, the user has typed several S-expressions to perform addition, and the Scheme engine has both echoed what the user typed and provided the resulting sums, in sequential order, in the Main Display Panel. The Input Panel contains the text "(+ 5 5)", which the Scheme machine has not yet encountered, because the user has not yet typed "return" there. Yet the Input Panel is only the bottom line of a much larger scrolling text view that is mostly hidden. If you could make the Main Display Panel disappear, then entire content of the Input Panel, including both the visible part and the part that is normally hidden, would show just the command history; it would look like this:

The visible and invisible parts of the Input Panel.
Yet there is certainly more to a modern GUI than text windows. Wraith Scheme indeed has lots of menu items, mostly with keyboard shortcuts, and several buttons, and a couple of handy auxiliary panels that can be made to appear attached to the main window. (Apple used to call these panels "drawers", and one feature of the macOS user interface was a way to set them up and use them automatically. Apple has long since deprecated and removed that feature, but I have been able to provide the same behavior by using Apple user interface features that are still available. These panels obviously slide into and out of the main Wraith Scheme window, so for want of an alternative word, I still call them "drawers".)
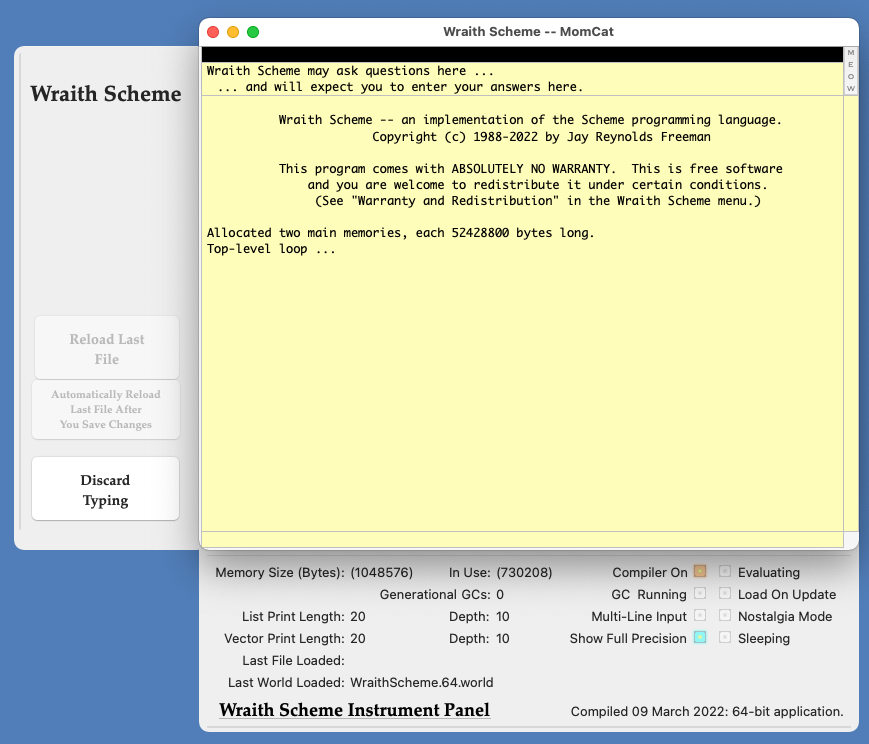
The Wraith Scheme main window, with two of the accessory drawers visible.
Since screen real-estate is a bit scarce on the smaller Macintosh computers, the drawers are optional. There are menu commands to slide them in and out, and they can be positioned at part-way settings by hand. Two of them are shown fully extended in the image above, and there are also a third and fourth that slide out from the right side and top of the main window.
Let me get menu items out of the way: Wraith Scheme has lots of them, and since I myself am a sufficiently fast typist that using a mouse or trackpad usually slows me down, most of the menu items have keyboard shortcuts. The menu items are pretty much all conventional, though, and they are all conventionally arranged, following Apple's human interface guidelines. There is not much to say about them. Possibly the only menu-item feature that is noteworthy, is that the keyboard shortcut for resetting Wraith Scheme to the top-level read-eval-print loop uses four separate keys and takes both hands to execute. (That shortcut is Control-Option-Command-Delete). I set it up that way because it can be a very vexing error to reset Wraith Scheme accidentally when it is part way into a long calculation; I wanted to minimize the chance that anyone would do so by mistake.
I myself generally much prefer using keyboard shortcuts to pushing buttons, but some people seem to like buttons, so I provided a small assortment of what I hope are the most important ones. They are located on the drawer that attaches to the left side of the Wraith Scheme window. In other documentation, I call that drawer the "Basic Buttons Drawer". A user who doesn't want buttons can slide the drawer in to reclaim screen space. An experienced user, who likes buttons and knows which is which without looking at the button titles, can slide the drawer nearly closed, so that only the very edges of the buttons are visible: The buttons will still work in that configuration.
The Basic Buttons Drawer contains one other interesting feature. An occasional problem with typing into a Lisp or Scheme interpreter is losing track of parentheses or unknowingly getting stuck inside a quoted string. What happens is, you have typed a multi-line expression, and you think it is complete, so you press "return" and expect something to happen. Unknown to you, however, you are missing one or more closing right parentheses, or perhaps you have not typed the double-quote that ends a text string. So when you press "return", nothing happens -- the parser portion of the read-eval-print loop is patiently waiting for you to provide the missing characters -- and it will happily wait forever.
To avoid that problem, I have arranged that in such circumstances, a small text field appears at the bottom of the Basic Buttons Drawer, right next to where you are typing. It tells what is missing.

Wraith Scheme advising of a missing right parenthesis.
In the image above, the user has typed "(+ 2 2" -- note that there is no closing parenthesis -- and then pressed "return". The panel at the bottom of the Basic Buttons Drawer is pointing out that the parser is expecting a ')'.
The Basic Buttons Drawer is arranged so that if the drawer is slid in part way, the little text field does not slide with the rest of the drawer. It will remain visible even when the drawer is partially closed.
The other drawer, attached at the bottom of the main window, is what I have called the "Wraith Scheme Instrument Panel" in other documentation. It differs from the Basic Buttons Drawer in that the Wraith Scheme Instrument Panel contains no controls -- it only provides information. (That is not to say that this panel is completely inactive; for example, running the mouse over any field that displays a file name will bring up a "Tooltip" box that shows the full Unix path to that file.) I felt that it was important for the user to have clear information, visible at a glance, about what the Wraith Scheme program was doing at any given moment, and the Instrument Panel was a way to meet that need.
The notion of an "instrument panel" grew out of two things. The first, of course, was the kind of instrument panel used in an automobile or an aircraft. The second was the kind of front-panel display found in mainframe computers in the old days, or in such first-generation hobbyist personal computers as the MITS Altair 8800 or the IMSAI 8080. These machines all had lots of tempting panel switches and fascinating blinking "status lights". I thought that the functions of panel switches were better handled by menu items, keyboard shortcuts, and the like, but status lights are a compact, attention-getting and easily-implemented form of information display, so I provided several of them.
The Instrument Panel is also arranged so that when it is partially closed, the most important information remains visible. That information includes the two most important status lights, that show whether Wraith Scheme is evaluating or garbage collecting, and the text displays about the amount of memory in use.
The conspicuous blank space on the Instrument Panel, just below the text field that reads "Memory Size ...", is not actually empty space. Wraith Scheme also provides some sense lights that are under the control of user programs. They are normally invisible, but that blank space is where they appear when they are in use.
Wraith Scheme showing off the user-controlled sense lights.
One issue about the Instrument Panel was whether to make it appear at a constant position with respect to the main window -- as a drawer does -- or to have it be a separate window entirely, which the user could position at will. I decided to go for a constant position, by the logic that you don't want the speedometer in your car changing its position from time to time: I thought that important information should be available at a glance, without having to think consciously about where it is.
There is a different metaphor for interacting with text than a teletype, that is almost as old. It is sometimes called a "browser interface", I believe because this kind of interface was used in a specialize Smalltalk programming window -- called a "browser" -- that was featured even in the earliest versions of Smalltalk, that were developed at Xerox PARC decades ago. The present meaning of the term is a little muddled, because nowadays whenever anyone talks about a "browser" people immediately think about software for surfing the Internet: I am not talking about web browsers. Don't worry if you don't know Smalltalk, though: "Browser interfaces" of the kind that I wish to discuss are employed in virtually every text editor and word processor in use today.
The idea is that there is a big field of text, and the user may type anything he or she wants wherever he or she wishes. That is precisely what a text editor or word processor does. Yet there is a difference between a word processor and a programming language interpreter: When you have written the great American novel in your word processor, you are all done with the text -- all you have to do is ship it to a publisher and wait for your royalty checks.
Non-Technical Note: You may wait a long time for those checks ...
With the addition of means to tell the programming-language interpreter to deal with a selection of text, a browser user interface resembles what I have sometimes heard called a "magic slate", a term for a computer interface that dates from the 1960s or 1970s. I don't recall where I first heard of it, or from whom. The idea is perhaps a descendant of the "magic mirrors" of classic fairy tales, in which you ask "Mirror, mirror, on the wall ...", and a spirit in the mirror answers your question. Anyway, the idea of a "magic slate" is that you write your question on the surface of the slate, and tell the slate to go to work on it; then, presently, the answer appears. (Though I must say in passing, that the well-known Google search field acts much more like a magic slate than any of my Scheme interpreters do, at least so far...)
The original Pixie Scheme had a magic slate interface, in which the user operated the standard Apple user-interface mechanisms to mark some text by dragging with the mouse -- it would show up as highlighted on the screen -- and with a menu command to evaluate what had been marked. That was an easy and natural way to set up a user interface, given the software tools of the time. What is more, the "magic slate" notion sounded enough like what a programming-language interpreter does -- particularly one for a language widely used in artificial intelligence, like Scheme -- to be an appealing design metaphor.
There are both pros and cons to a magic slate interface, compared to a teletype interface. Let me describe some of them.
The teletype interface provides an unambiguous sequential record of what has happened, without having to use any optional mechanism, such as Scheme's "transcript-on" and "transcript-off" procedures. The teletype interface is also perhaps a little faster to use: With a reasonable selection of keyboard shortcuts to supplement normal typing, the user rarely needs the mouse or the trackpad. On the other hand, it can sometimes be awkward to retype or otherwise work with previously-typed material, particularly when it has scrolled off the top of the screen.
Speed and the easy availability of a full transcript led me to choose a teletype style interface for Wraith Scheme, instead of continuing to use Pixie Scheme's magic slate style. There was another possible contributing factor to that decision: I was doing the conversion from Pixie Scheme to Wraith Scheme on a 2006 Macbook 13 laptop; the trackpad on that early model was rather awkward to use, and I never did bother to get a mouse for it.
A magic slate interface is slower to use, because of the occasional need to move the text-insertion point around. Furthermore, depending on how the user does things, there is usually no way to obtain at a glance a complete sequential record of everything that has happened so far; that is, the user may have moved the insertion point around or deleted previous text that was no longer wanted.
On the other hand, with a magic slate interface there is no problem interacting with any text you like, and it is also easy to make minor changes in existing text, for reevaluation by the interpreter, when necessary. Also, with a magic slate interface it is easy and natural to clear text that you are done with out of the text window, just by deleting it. A user tends to do that almost without thinking about it, once the text items of actual interest have become so widely separated in the window that it takes a lot of scrolling back and forth to find them. That tendency was an advantage in the days of Pixie Scheme, for the text windows in the early Macintosh computers were of limited capacity, and tended to slow down a great deal when they started getting full. The problem is still present in the modern Macintosh, but to a much lesser degree.
There are many ways to talk to the programming-language interpreter in a browser-style interface. The first and simplest was used in many early versions of the Basic programming language: The entire content of the text window is taken to be the text to be evaluated -- the window is assumed to hold your entire program, and nothing else. You get it right, then tell the interpreter to try to run it. That is a bit simple for what most people want to do with Lisp-class languages, though.
There are a variety of possible ways to use the language parser as an aid to figuring out what text is to be evaluated. The general idea is to put the graphics cursor or the text-editing cursor in or near the expression to be evaluated, or perhaps at a parenthesis on the end of it, and use the parser somehow to work out what expression the user has in mind. That works easily sometimes: If the user has typed a complete and correct Scheme S-expression, with parentheses at both ends, and the cursor is touching the opening parenthesis, there probably isn't much ambiguity, though it can be confusing and perhaps disastrous if the user has forgotten the closing right parenthesis and the Scheme engine ends up trying to process everything between the cursor and the end of the text window.
Unfortunately, there are some ambiguities that might confuse a user. Suppose, for example, that there are two adjacent S-expressions, with no spacing between them, and that the cursor is right between them, like this (and note that I am using a "vertical bar" style cursor):
Which S-expression does the user want evaluated? Or is it both of them? Or suppose the cursor is between the quote of a quoted S-expression and the S-expression itself, like this:
Again, what does the user want? Or suppose the S-expression is on a line that has been commented out:
Should the Scheme engine do nothing, or should it pretend that the semicolon isn't there?
It is in fact not trivial to parse Scheme -- and I suspect most other programming languages -- when the start or end of the expression to be parsed, or both, lie at an unknown distance away from the cursor, but that is not the point. The difficulties are probably solvable, but I consider it very bad practice to leave the user uncertain of what is going to happen. Therefore, the ambiguities that I have just mentioned are in my opinion more than sufficient cause to rule out a simple "place the cursor and go" approach to telling the interpreter what to do. It seems to me that the magic mirror must at least mark the text that it is about to evaluate, and give the user a chance to confirm that the correct text is selected, before proceeding. That is of course a judgment call, and I don't mean to tell anyone that it has to be done that way.
Given a mark-and-confirm approach, one still might use the parser to help identify text, but I have chosen not to do so. It seems to me to be simpler to take more direct cues from the user as to what text is to be evaluated -- either let the user mark text in the usual ways, such as by clicking or dragging, or keep track of what the user has been typing and offer to mark that. Once again, that is a judgment call.
Technical Note: Here are some examples of why using the parser when the start and end points of the expression are unknown, is not trivial:
With that kind of reasoning in mind, I gave the original Pixie Scheme a very simple mechanism to tell the Scheme engine what to do: The user marked text by the usual means -- whereupon it showed up highlighted -- and said, in effect, "Evaluate that." The Scheme engine tried to do so. If it succeeded, well and good, and it printed the result of the evaluation immediately after the text that had been evaluated. If parsing or evaluation failed, the Scheme engine printed an error message. I do not have any screen shots of Pixie Scheme to show you, but that kind of operation is very simple, was fairly common in other Lisp systems of the time, and seemed quite satisfactory.
When it came time to create Pixie Schemes II and III, I again addressed the issue of what kind of text interface to provide for the user, and I went back to the browser style that I had used in the original Pixie Scheme. I had several reasons for doing so, most of which stem from the target platform for Pixie Scheme III being the Apple iPad™.
The new idea for Pixie Scheme II and III was to keep track of when the user was typing continuous runs of text, and offer to mark any such run that existed, for possible evaluation. In more detail, whenever the user places the typing cursor in a new place and starts typing, a run of text begins. As long as the user just adds text at the end of a run, or perhaps backspaces over characters just typed, the application remembers where the start and end of the current run are. Any other action, such as moving the cursor around or changing "focus" out of the text window, causes the run to be forgotten.
Here are some screen shots from the iPad application, Pixie Scheme III, to show how it works. Pixie Scheme II works the same way.
The first image shows the Pixie Scheme III application just after it has opened; the user has not typed anything yet. (Actually, the images are from Apple's excellent iPad simulator -- taking screen shots from the simulator is easier than from the device itself.)
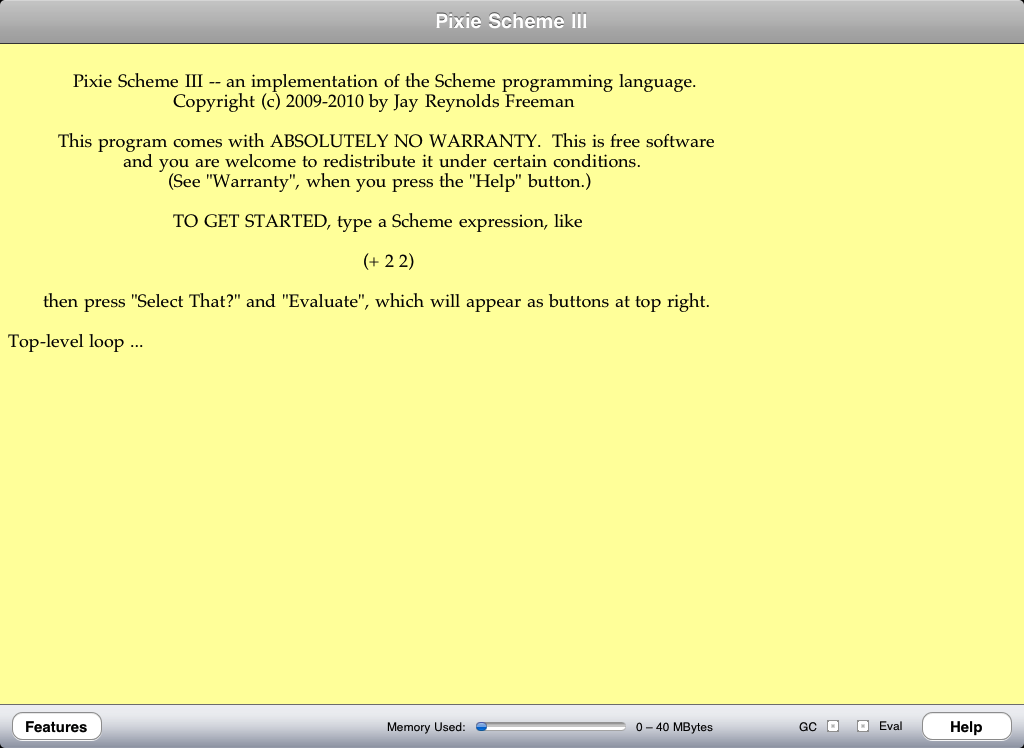
The Pixie Scheme III Main Window, at reduced size.
In the second image, the user has typed an S-expression, "(+ 2 2)", and a button labeled "Select That?" has appeared at top right. The "Select That?" button appears whenever the user is typing a run of text, whether or not it is a complete S-expression.
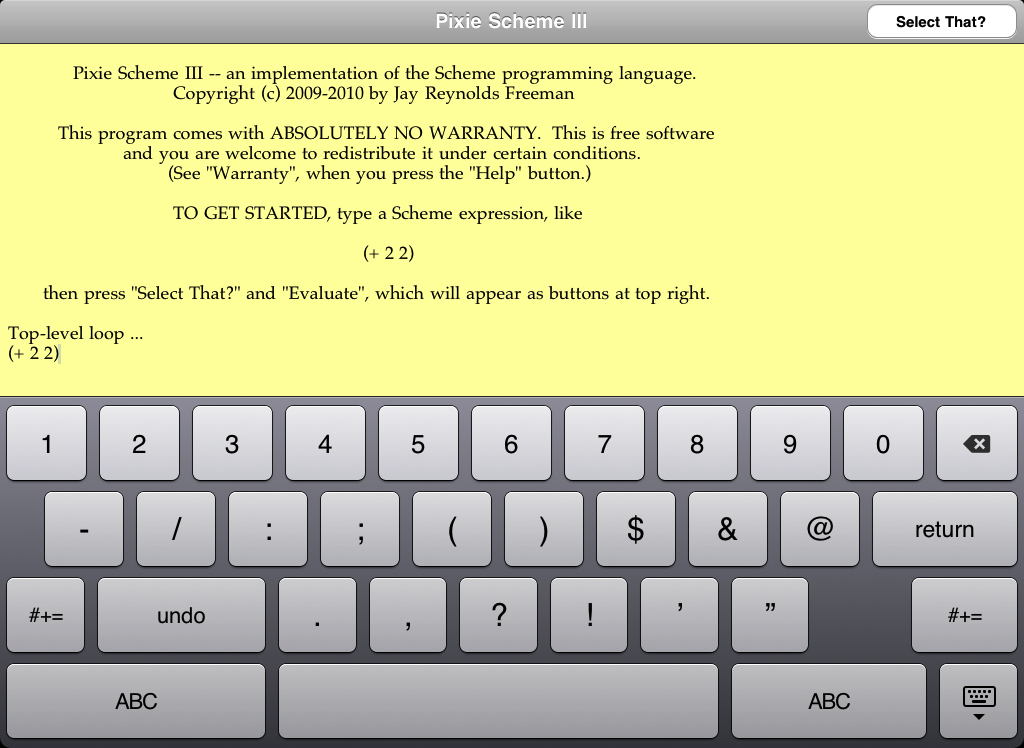
The Pixie Scheme III Main Window, with typed text, at reduced size.
In the third image, the user has tapped the "Select That?" button. The text that the user has typed has become highlighted, and the title of the button has changed from "Select That?" to "Evaluate". The "Evaluate" button appears whenever the user has marked text by any of the standard means as well, such as by tapping, by dragging with a fingertip, or by pasting in text from some other application.
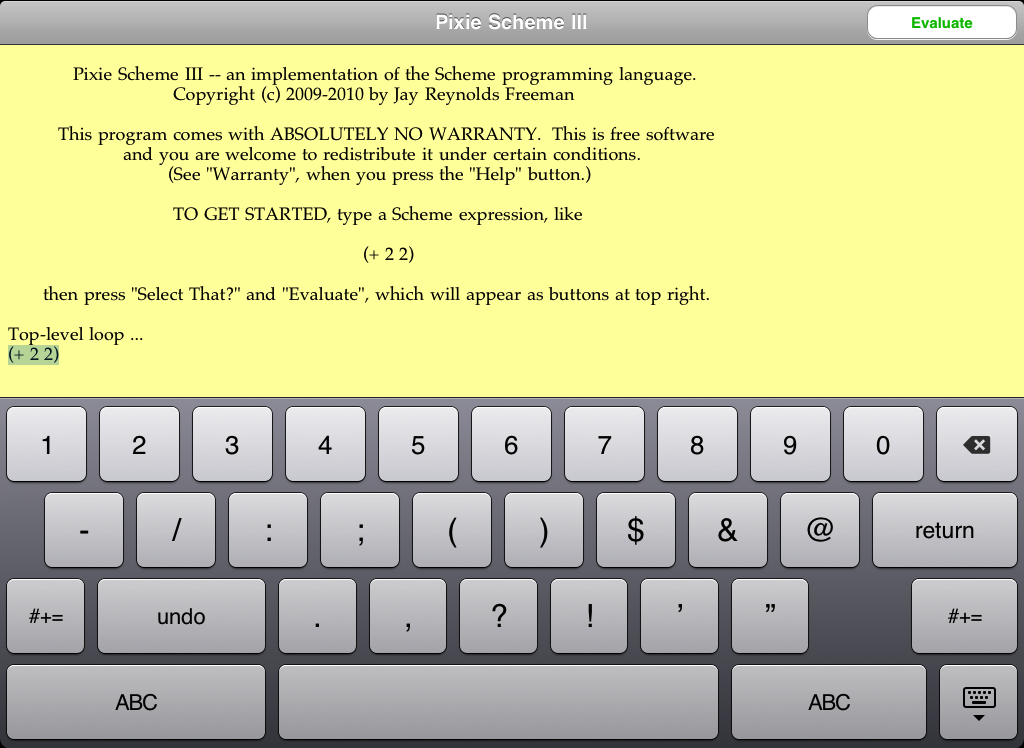
The Pixie Scheme III Main Window, with selected text, at reduced size.
Readers familiar with the iPhone or iPad will note that the highlighting effect shown above is not quite the normal one -- when a user marks text on an Apple portable device by tapping or dragging, the highlighted area appears with a popup menu next to it that offers options for what to do -- the choices are things like "Select", "Copy", "Cut", and "Paste". An example follows:
I know how to make that popup menu appear, but I decided not to use it in this case. The things that cause the popup menu to appear in normal use of the iPad are very specific, and pressing a mysterious specialized button is not one them. I thought it might risk confusing people if I added an unexpected instance of a standard behavior to the user interface. So instead, I merely duplicated the standard color and placement of the highlighting.
In the fourth image, the user has pressed the "Evaluate" button. Pixie Scheme III has evaluated the S-expression, and printed the result -- the number "4" -- in the line immediately below the S-expression itself. The top right button is not present. Pixie Scheme III is waiting for the user to start typing a new run of text.
The Pixie Scheme III Main Window, showing an evaluation, at reduced size.
The flow of interaction with Pixie Scheme III this way is very natural: You type an expression to evaluate, press the "Select That?" button to make sure what you are about to evaluate is what you think it is, then press the same button -- now labeled "Evaluate" -- again, to pass the expression to Pixie Scheme III.
The lack of a menu bar and the limited screen space on the iPad require the interface designer to make careful choices about what special features to provide in an iPad application, and about how to present them. The image below shows most of Pixie Scheme III's bells and whistles, all displayed at once.
I am not saying that anyone should display all the bells and whistles at once. This image is only to give you a feel for what they are.
The Pixie Scheme III Main Window, showing various special features.
At top left is a "Reset Scheme" button, that only appears when the Scheme machine is running. It has orange text, to discourage the user from pressing it by accident, and what is more, no other button or control ever appears in that position in the Pixie Scheme III application. Thus the user will have no reason to form the habit of pressing that part of the screen for some other reason, when using Pixie Scheme III.
At lower left is the "Features" button, showing the pop-up menu -- Apple calls them "popovers" -- that appears when it is pressed. That menu allows access to a few critically important features of the application, several of which were disabled when the image was captured, because the Scheme machine was running at the time.
Below that popover are eight user-controlled sense lights. They are invisible until and unless the user makes them visible. To their right is a slider that displays how much Scheme main memory is in use. Right of that are two labeled status lights that show whether Pixie Scheme III is garbage collecting (it wasn't) or evaluating (it was).
At far lower right is another button that controls another popover that also works like a pop-up menu; that button's popover is not displayed in this image. The buttons that appear on that popover merely switch to auxiliary views, displayed modally, that show a help file, a dictionary of all the procedures and special forms that Pixie Scheme III knows about, the "README" file for the application, and the GNU General Public License. These documents are all part of the application itself; there is no need for Internet connectivity to read them.
This section discusses "Pixie Scheme III", an app for early versions of the Apple iPad™, that was available for purchase from Apple's App Store for a few years in the early 2010s. It is no longer available, but I am retaining this section for historical interest, and also because I might someday update the app and get it into the App Store again.
When Apple started releasing such touch-screen oriented devices as the iPhone™ and the iPod Touch™, I began to think about creating some kind of Scheme interpreter to run on them. My thoughts did not get very far, however; the use of any programming-language interpreter tends to involve writing lots of text, and the diminutive keyboards of these platforms were a serious impediment to substantial typing.
The advent of the iPad™, with a much larger keyboard that was much easier to use, brought the subject back to my mind. Furthermore, at the 2010 Apple World-Wide Developers Conference, I chatted with a lot of high-tech and geeky iPad users who by and large agreed both that the device was generally useful to people like them (and me), and that its keyboard, though a long way from perfect, was at least moderately usable for moderate amounts of text entry.
There were several particular reasons to be intrigued. First, I do believe in community service, and there is a small community of Lisp and Scheme enthusiasts who would probably be delighted to run such a program on any iPad they might possess. Second, also in the line of community service, Scheme is widely used as a teaching language, and some of those students might prefer to take an iPad to class instead of a bulkier and heavier laptop. Third, and having nothing to do with community service, such a project would be what is often euphemistically known as an "interesting technical challenge", and I am a nothing if not glutton for punishment, particularly when it comes to scientific or technical challenges.
Non-Technical Note: So somebody in a Silicon Valley bar comes up to you and asks, "Hey, <wink wink nudge nudge>, are you into S&M?" And the answer is, "No, we do R&D ..."
Since I did not then own an iPad, and since I had not attempted to write any programs using Apple's new frameworks and development tools for their touch-screen devices, I decided to approach the problem in four major steps:
I have discussed the user-interface design issues that apply to all of my Scheme interpreters above, in the section on User Interface Design. A few other issues were important for any implementation of Pixie Scheme that would run on the iPad.
To conform to the iPad's rather restricted idea of multitasking, I generalized the idea of a Lisp "world save". This operation traditionally saves the entire content of Lisp main memory in a file which may be read back in later. I made the file contain not only the content of main memory, but also the entire text displayed in the main window, and several other items reflecting the state of the user's environment. A user who restores from such an enhanced saved world gets back not only the content of main memory but also the appearance and content of the development environment at the time of the save.
Such a notion is important for the iPad, because it really does not multitask: When an application enters background, it is expected to save state and cease processing, with the idea that perhaps it will be killed later on, without any further notice. What I intend to do in Pixie Scheme III in such circumstances is cease processing (that is, reset the program to the top-level loop), save a world, and then hope for the best. Fully developing and testing that idea will require Apple's iOS 4 for the iPad; it is not available as I write these words. The mechanism to save state by a generalized world save is implemented in the present release of Pixie Scheme II, which runs on the Macintosh; you can see how it operates there, if you wish.
Unfortunately, when I acquired a real iPad, I found I could not use that mechanism for Pixie Scheme III. The time required to perform a Pixie Scheme III world save, in the worst case of Scheme main memory nearly full of non-garbage, is 30 seconds, but the time that iOS allows for a backgrounded application to save state is only 5 seconds. Thus it was possible that iOS would shut down Pixie Scheme III when it had been put in background, before it had finished saving state. When that happened, the user would lose data. I decided that it would be bad design to have the app able to save data most of the time -- lulling the user into a false sense of security -- but fail to do so occasionally. So Pixie Scheme III, as presently implemented, does not "background" in the sense that Apple uses the word for iOS. I wish I had a fix for that problem, but I do not.
Technical Note: When any of my Scheme implementations saves a world, it does a full garbage collection first, and it is the full garbage collection of a complex, nearly-full Scheme main memory that causes most of the 30 second time delay. It would perhaps be possible to arrange that world saves did not require a preparatory full garbage collection, but the system still does have to do full garbage collections from time to time. If Pixie Scheme III were put in background while a full garbage collection was happening, iOS would very likely terminate it before garbage collection had finished, and the user would lose state because no world save had occurred.
I know of no way to make a full garbage collection interruptible in the sense required for iOS's kind of multitasking and background operation. Garbage collection is a great task for the traditional kind of multitasking and background operation, that iOS does not allow.
The iPad also does not give the user much access to its underlying Unix file system. Therefore, with some trepidation, I stripped the all of the "R5" file-system access procedures out of the new Pixie Schemes, as well as all of the enhancements that deal with file systems. The intended means for users of the new Pixie Schemes to load code is to paste it in and evaluate it, and the intended means for extracting results to a file is to cut them out and paste them into a document in some other application. I am not entirely happy with that decision, but considering how the iPad works, it was the best I could think of.
For the sake of simplicity, I also made the new Pixie Schemes non-parallel-processing -- there are no kittens -- and removed the foreign-function interface, the socket functions, the interrupt mechanism, and the interface to the Unix "system" call.
Pixie Scheme II and Pixie Scheme III have been written to follow the specification in this section. I suppose that if Pixie Scheme II proves popular, just because of its interface, I could put back some of the Wraith Scheme features that I have removed from it. It would then simply be a new version of Wraith Scheme with a different user interface.
The "Scheme machines" of the new versions of Pixie Scheme are similar enough to those of Wraith Scheme that there is no need to distinguish between them in the discussion in this document. As I have already mentioned, the main distinction was to eliminate from the new Pixie Schemes, a handful of the Scheme-engine features that Wraith Scheme has. For that matter, Wraith Scheme's Scheme engine is a close derivative of the Scheme engine of the original Pixie Scheme, and uses much of the original Pixie Scheme's source code, with no changes.
Pixie Scheme II is available open-source under the GNU General Public License.
Pixie Scheme II is presently rather an experimental application; it has not received the same level of testing as has Wraith Scheme, and is not as well documented.
Pixie Scheme II is not a complete "R5" Scheme: Since one of its major functions was to serve as a design prototype for a possible iPad implementation of a Scheme interpreter, and since the iPad provides only limited access to its underlying Unix file system, I deprived Pixie Scheme II of the standard "R5" file-system interface. I might put it back in the future, if people like Pixie Scheme II for itself alone.
The source code for Pixie Scheme II is intertwined with the source code for Wraith Scheme and Pixie Scheme III by way of an inexcusable morass of #ifdefs and the like. Thus there is only one source code release, nominally labeled as a source code release for Wraith Scheme, which actually contains the source code for both applications.
To build Pixie Scheme II, you must set up the entire source trees for Wraith Scheme, Pixie Scheme II, and Pixie Scheme III, then perform several commands in the Wraith Scheme source tree before attempting to build Pixie Scheme II.
Specifically, the source tree structure required is that the three directories, "WraithScheme.64", "Pixie Scheme II" and "Pixie Scheme III" be created as subdirectories of one directory. The tar file and disk image for the source release each contain all three of those directories. In my present personal development environment, the paths to those directories, as installed, are respectively "/Users/JayFreeman/Developer/Scheme/WraithScheme.64", "/Users/JayFreeman/Developer/Scheme/Pixie Scheme II", and "/Users/JayFreeman/Developer/Scheme/Pixie Scheme III".
The commands in the Wraith Scheme directory tree required before building Pixie Scheme II are all executed from the Makefile in <whatever>/WraithScheme.64/source. First, "cd" to that directory, then type:
make ws_tty_64 make new_world_64 make pixie_scheme_ii_world
Those commands respectively build a version of Wraith Scheme that runs in a terminal shell, use that software to create a generic world load for Wraith Scheme, then modify that world load into the world load required by Pixie Scheme II. The build of Pixie Scheme II knows where to look for it.
With that done, you may build Pixie Scheme II with Apple's Xcode. The Xcode project file is <whatever>/"Pixie Scheme II"/"Pixie Scheme II.xcodeproj". The build should work with Xcode 3.2.4 -- if you can find and run a version that old -- and advised that I have had to turn "Link Time Optimization" off to build in some recent versions of Xcode.
Pixie Scheme III was for sale in the App Store for a while, and is available open-source under the GNU General Public License. I might some day update it and see about getting it back in the App Store.
Pixie Scheme III is not a complete "R5" Scheme: Since the iPad provides only limited access to its underlying Unix file system, I deprived Pixie Scheme III of the standard "R5" file-system interface. I also did not install many of Wraith Scheme's enhancements; notably, there is no foreign-function interface, no interrupt-handling mechanism, no parallel processing (that is, no kittens), no Unix socket interface, and no interface to the Unix "system" function.
The source code for Pixie Scheme III is intertwined with the source code for Wraith Scheme and Pixie Scheme II by way of an inexcusable morass of #ifdefs and the like. Thus there is only one source code release, nominally labeled as a source code release for Wraith Scheme, which actually contains the source code for all three applications.
To build Pixie Scheme III, you must set up the entire source trees for Wraith Scheme, Pixie Scheme II, and Pixie Scheme III, then perform several commands in the Wraith Scheme source tree before attempting to build Pixie Scheme III.
Specifically, the source tree structure required is that the three directories, "WraithScheme.64", "Pixie Scheme II" and "Pixie Scheme III" be created as subdirectories of one directory. The tar file and disk image for the source release each contain all three of those directories. In my present personal development environment, the paths to those directories, as installed, are respectively "/Users/JayFreeman/Developer/Scheme/WraithScheme.64", "/Users/JayFreeman/Developer/Scheme/Pixie Scheme II", and "/Users/JayFreeman/Developer/Scheme/Pixie Scheme III".
The commands in the Wraith Scheme directory tree required before building Pixie Scheme III are all executed from the Makefile in <whatever>/WraithScheme.64/source. First, "cd" to that directory, then type:
make ws_tty_64 make new_world_64 make pixie_scheme_iii_world
Those commands respectively build a version of Wraith Scheme that runs in a terminal shell, use that software to create a generic world load for Wraith Scheme, then modify that world load into the world load required by Pixie Scheme III. The build of Pixie Scheme III knows where to look for it.
With that done, you may build Pixie Scheme III with Apple's Xcode. The Xcode project file is <whatever>/"Pixie Scheme III"/"Pixie Scheme III.xcodeproj". The build should work with Xcode 3.2.4 -- you might guess that I haven't tried to build it for a long time -- and be advised that I have had to turn "Link Time Optimization" off to build in some recent versions of Xcode.
If you can build Pixie Scheme III, it should be straightforward for you to run it in the iPad simulator that Apple provides free for developers. If you are a paid-up member of Apple's iOS development program, then you should also be able to set things up to download your build to any iPad that you happen to own and run it there, as well. Apple's procedures for doing these things have been changing rapidly of late, however; so I am not going to attempt to give precise directions for how to do so here.
Here is a list of enhancements to Wraith Scheme that I am at least thinking about doing myself. Wraith Scheme is open-source, so I of course can't and won't tell you what kind of enhancements or adaptations you should put in on your own, but you might like to know what I am interested in doing in case you would like to cooperate, or perhaps to avoid reinventing a wheel that I may already be working on.
This list is necessarily incomplete. Note that it was longer in the previous version of this document; I have in fact done several of the things I said I might do.
Here is a list of enhancements to Wraith Scheme that might conceivably be considered neat, but that for one reason or another I myself do not presently plan to work on. They might make interesting projects if anybody wants to work on an enhancement or extension of Wraith Scheme.
This list is necessarily incomplete.
It is difficult to write proper acknowledgments for my Scheme interpreters, simply because I didn't keep good notes. When I started the project, I never imagined that I would write this document. I talked with many people and read an enormous number of sources, but by now I have forgotten what came from where. It would be an enormous error for anyone to think that I claim to have invented everything described here that is not specifically credited to someone else; that is not the case at all.
It is certainly fair to say that every book or other reference that I mention in the Bibliography of this document was at least a substantial technical inspiration for Wraith Scheme, and all of the authors of those works deserve credit and acknowledgment. In addition, I should specifically mention technical advice, assistance, or discussion from the following:
-- Jay Reynolds Freeman, September 2022