Warranty, License, and Distribution
Applicability of this Document
Introduction
Getting Started
System Requirements
Installation
Security
Starting Wraith Scheme
Wraith Scheme Startup Actions
Changing the Startup Defaults
Changing How it Looks
Interacting with Wraith Scheme
The Wraith Scheme Window
The Input Panel
Command Name Completion
Command Syntax Information
Detailed Command Information
The Main Display Panel
The Message Panel
The Dialog Panel
The Basic Buttons Drawer
The Wraith Scheme Instrument Panel
The Sensory Devices Drawer
The Attic
Menu Items
The Wraith Scheme Menu
The "Preferences..." Menu Item
The Interpreter Menu
Shortcuts for Typing
The Edit Menu
The Font Menu
The Window Menu
The Tutorials Menu
The Help Menu
Another View of Interacting with Wraith Scheme
Error Handling
Controlling Wraith Scheme
The Garbage Collectors
Suggestions for Using Wraith Scheme
Differences from R5 Scheme
Run-Time Text Input
R5 Section 1
R5 Section 2
R5 Section 3
R5 Section 4
R5 Section 5
R5 Section 6
Internal Representations of Numbers
Exactness -- Complex Numbers
Exactness -- "string->number" and "number->string"
#\tab and #\return
Slashification
R5 Section 7
Optional Features Omitted
Extra Features Added
Enhancements
Applicative Programming
Class System
Class System Procedure
Important Notes
A Simple Class Example -- Right Triangles
Creating and Using Methods
Inheritance
Inheritance -- A Familiar Example
Class Variables
Methods and Procedures as Variables
Critical Sections in Classes
Class Summary
Compiler
Debugger
Lambda Expression "Names"
Float Matrices
Float Matrix Procedures
Foreign-Function Interface
Overview of the Foreign-Function Interface
Some Background for mmap
Details and Procedures for Sharing Memory
Utility Procedures for Memory-Mapped Blocks
Procedures for Accessing Memory-Mapped Blocks
Details and Procedures for the Interrupt System
SIGINT Interrupts
SIGALRM Interrupts
SIGUSR1 Interrupts
Precautions for Using Interrupts
Demonstrating the Foreign-Function Interface in Wraith Scheme
Demonstrating the Foreign-Function Interface with Other Programs
Foreign-Function Interface Recommendations and Reminders
Forgettable Objects
Forgettable Object Content
Forgetting Behavior
Programming Interface to Forgettable Objects
Some Uses of Forgettable Objects
Kitten Graphics
Introduction
A Simple Example
Procedures for Kitten Graphics
Sample Code
Kittens -- Parallel Processing in Wraith Scheme
Introduction to Wraith Scheme Parallel Processing
Background, Philosophy and Intent
Keeping Track of Things
Interprocess Communication
File System Access
Locks and Critical Sections
Aids to Debugging
Auxiliary Files
Optimizations
Logic Programming
Non-Printing Objects
Packages
Procedures and Forms
Bit Operations
Continued Fractions
Evaluation
Files and Directories
Infinities and Nans
Inspecting Scheme Objects
Long Ratnums and Continued Fractions
Macros -- An Alternate Implementation
Miscellaneous Predicates
Miscellaneous Procedures
Multiple-Values Objects and Operations
Numeric Formatting
Permanence
Print Length and Depth
Random Numbers
Speech Synthesis
Sorting and Merging
State Flags
Storage Management
System Information
Top-Level Control
Unix Sockets
Sensory Input Devices
Sensory Output Devices
Level Indicators
Sense Lights
Top-Level Loop Variables
World Saves and Loads, and Stand-Alone Programs
Weasel Scheme
Weasel Scheme and Raspberry Pi General Purpose Input/Output
Bugs, Flaws, Limitations, and Dealing with Them
Known Bugs and Flaws
Limitations
Common Problems and Solutions
Elementary Debugging
Development Testing
Timeline
What's New
What Used to be New
What Might be New in the Future
Miscellaneous Information
Numbers Revisited
Technical Details About Wraith Scheme
Scheme References
Lisp References
Other References
Whimsy
On Dialectic and History
Excuses
Infrequently Asked Questions
Thanks To

This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
Copies of the source code for this software may be downloaded from http://JayReynoldsFreeman.com/My/Software.html. If you cannot find that site or have difficulty using it, contact me by EMail at Jay_Reynolds_Freeman@mac.com.
A copy of the GNU General Public License is available while running the program, via menu item "Warranty and Redistribution" of the Wraith Scheme menu. You may also find the license on line at http://www.gnu.org/licenses.
The Wraith Scheme executable program itself is shareware: You are welcome to use Wraith Scheme for free, forever, and to pass out free copies of it to anybody else. If you would like to make a shareware donation for it, that's fine, and there is information in the program about how to go about it, but in no sense do I request, insist, or expect that you do so. Furthermore, Wraith Scheme is intended to be complete and fully functional as downloaded. There is nothing to buy, there are no activation codes required, and there are no annoying reminders about shareware donations.
This help file is specifically intended to accompany Wraith Scheme 2.28. It also applies to the supplementary application, Weasel Scheme, which is provided with distributions of Wraith Scheme and runs on the Raspberry Pi 400 microcomputer.
Wraith Scheme 2.28 is a "Universal 2 Binary" application: It has been tested, and runs, on Macintosh computers with both Intel processors and Apple's proprietary processors ("Apple silicon"), with operating systems at least as recent as macOS 11.6 ("Big Sur"). I do not have a complete set of all Macintosh computers to test on, but Wraith Scheme 2.28 may possibly also run on ones using macOS 10.14 ("Mojave") or later, with either Intel processors or Apple's proprietary processors.
Wraith Scheme 2.28 will not run on macOS High Sierra, or any earlier version of macOS.
Wraith Scheme 2.28 is available for download from the "Software" page of my personal web site, http://JayReynoldsFreeman.com.
Welcome to the help file for Wraith Scheme, an implementation of the Scheme programming language for the Apple Macintosh™. Wraith Scheme was written by me, Jay Reynolds Freeman. By all means EMail me about it if you wish.
As I write these words, Wraith Scheme is available for download from the "Software" page of my personal web site, http://JayReynoldsFreeman.com.
I believe Wraith Scheme is a complete implementation of the "R5" dialect of Scheme (major Revision 5 of Scheme). There is one caveat to the word "complete": The R5 report describes a number of optional Scheme features, using language like "some implementations support ...", or something similar. Wraith Scheme does not support all of these optional features. A list of optional features that are missing is here.
This document is not a complete Scheme language description or programming manual. For a complete and authoritative manual, I recommend that you obtain and peruse a copy of the 1998 Revised5 Report on the Algorithmic Language Scheme, edited by Richard Kelsey, William Clinger and Jonathan Rees. That report is available on several Internet sites, such as http://www.schemers.org.
All of Wraith Scheme's procedures and special forms are described in detail, with examples and discussion, in the Wraith Scheme Dictionary, which is another document that accompanies Wraith Scheme and may be opened from the Wraith Scheme Help Menu. A third document, Wraith Scheme Internals, similarly available, provides some assistance with understanding the Wraith Scheme implementation: It is aimed at those hardy souls who may wish to understand or modify Wraith Scheme's source code.
You might also consider reading some of the Scheme References and Lisp References listed later herein.
Wraith Scheme is shareware. I use that term in its least restricting and increasingly old-fashioned sense: You are welcome to use Wraith Scheme for free, forever, and to pass out free copies of it to anybody else. If you should at some time wish to make a shareware donation for Wraith Scheme, use my PayPal™ account, for which you will need my EMail address:
How much to donate is your choice.
Wraith Scheme was named after my late, lamented, scruffy gray cat, "Wraith". If you don't think that makes sense, remember that it runs on a computer named after a raincoat. Wraith Scheme is a direct descendent of Pixie Scheme (Pixie was another cat), which I wrote in the late 1980s for early versions of the Apple Macintosh™.
Wraith Scheme presents no advertising, sends no communications or any other information to me or to anyone else, and does not concern itself with who you are, how you use the program, or anything else you do.
By all means, look through this section of the manual, and perhaps also a few that immediately follow it. Another handy section is Common Problems and Solutions.
Wraith Scheme version 2.28 is a 64-bit stand-alone application for the Apple Macintosh™. It requires a Macintosh using operating system macOS 11.6 ("Big Sur") or later. It runs on Macintosh computers using either Intel processors or Apple's proprietary processors ("Apple silicon").
If you do not have an appropriate Macintosh, it might help to know that as I write these words, several earlier versions of Wraith Scheme are available for download from the "Software" page of my personal web site, http://JayReynoldsFreeman.com. Those versions support macOS versions as old as 10.4 ("Tiger"), and both Intel and PowerPC processors.
Technical Note: I originally developed Wraith Scheme on a 2006-model Apple Macbook™ (Macbook version 1,1 -- a flat-black 32-bit model with an 13-inch diagonal screen, a 2 GHz Intel Core Duo™ processor, and 1 GByte of memory), running macOS versions no earlier than 10.4.8. The present release was created on a 2019-model Mac Pro with a twelve-core Intel Xeon™ processor and 192 GByte of memory, running macOS 11.6 and Xcode™ 13.
The program is minuscule by today's standards -- less than 100 MBytes on disk, and the vast majority of that is documentation -- but just after startup it requests memory from the operating system as storage space for Scheme objects. The default main memory size of 10 MBytes, in the "Preferences" panel, results in Wraith Scheme requesting about 22 MBytes of memory from the operating system -- for two main memories plus some other stuff. You may change the setting to be smaller or larger if you wish. I have run Wraith Scheme using as much as 64 GByte of memory -- yes, I did say "gigabytes".
An installation of Wraith Scheme comprises just the "Wraith Scheme" application itself -- there are no extra files. The Wraith Scheme application contains some extra items embedded within it, such as HTML help files (including this one), a "README" file, and some examples of Scheme source code, so that all you really need is the application. (By the way, in case you obtained this help file as a separate download, the "Wraith Scheme Help" menu item, in Wraith Scheme's "Help" menu, will call up this same file from within the program -- you don't need a separate copy.)
"Installation" is simply the act of putting the application wherever you like. Possibly it should end up in your "Applications" folder, but that choice is up to you.
Note: The download that contains the Wraith Scheme application also has a folder containing another program -- Weasel Scheme -- which runs on a completely different computer -- the Raspberry Pi 400. If you have a Raspberry Pi 400, follow the link just given to the documentation, and help yourself. If not, ignore the extra folder.
Technical Note: One installation of Wraith Scheme should be sufficient for all users who have accounts on your Macintosh, provided that you put the Wraith Scheme application in a place where they all can get at it, such as in the "Applications" folder. Furthermore, if you have enabled "fast user switching" on your Macintosh, so that many users' activities may continue at the same time, you will find that different users will be able to run Wraith Scheme simultaneously, without interfering with one another.
Wraith Scheme and Weasel Scheme are what might be called "classic shareware": They depend solely on generosity for support, with no strings attached. In particular, there is nothing to register, there are no activation codes required, there are no enhanced versions available for a price, and there is no embedded advertising for anything. The shareware products, "Wraith Scheme" and "Weasel Scheme", are all there is. Furthermore, neither program will emit annoying reminders to send me a shareware donation.
You are welcome to make as many backup copies of Wraith Scheme and Weasel Scheme as you wish, and to give free copies of them to anyone.
Most people consider it ill-advised to run an unknown application -- like Wraith Scheme -- without special precautions, because it might contain code to do something malicious. If I had deliberately written a malicious program, I certainly wouldn't tell you, at least, not until it was way too late. What's more, if you are a suspicious type -- and in today's Internet and computing environment, you should be! -- there is nothing I can do or say to convince you that I have not put some ill-intended code into Wraith Scheme. Actually, I suppose it might help if I told you where I live, but I myself am a suspicious type, so I am not going to do that.
Besides, my house is a mess.
It might be useful to remember that Apple's macOS operating system is based on Unix: If you have moderate Unix experience, you might know that Unix is pretty good about keeping one user from messing with other users' data. Thus you might create a special, "dummy", user account, just for testing Wraith Scheme, with access to nothing other than Wraith Scheme and any files of Scheme code you may be using. If you know how to do that, good. If not, perhaps you should seek advice from a Unix-knowledgeable and trustworthy friend. (You shouldn't rely on me to provide the details; for all you know I am a computer criminal who might deliberately tell you something that didn't work, and thereby set you up for disaster.)
Furthermore, one thing I worry about -- something every software developer worries about -- is that some third party will modify my code to be malicious, or create a malicious program with the same name and appearance as mine, and produce nefarious results thereby. I have no way to avoid this problem.
You might also wish to know that Wraith Scheme neither collects nor transmits any information about you and your activities.
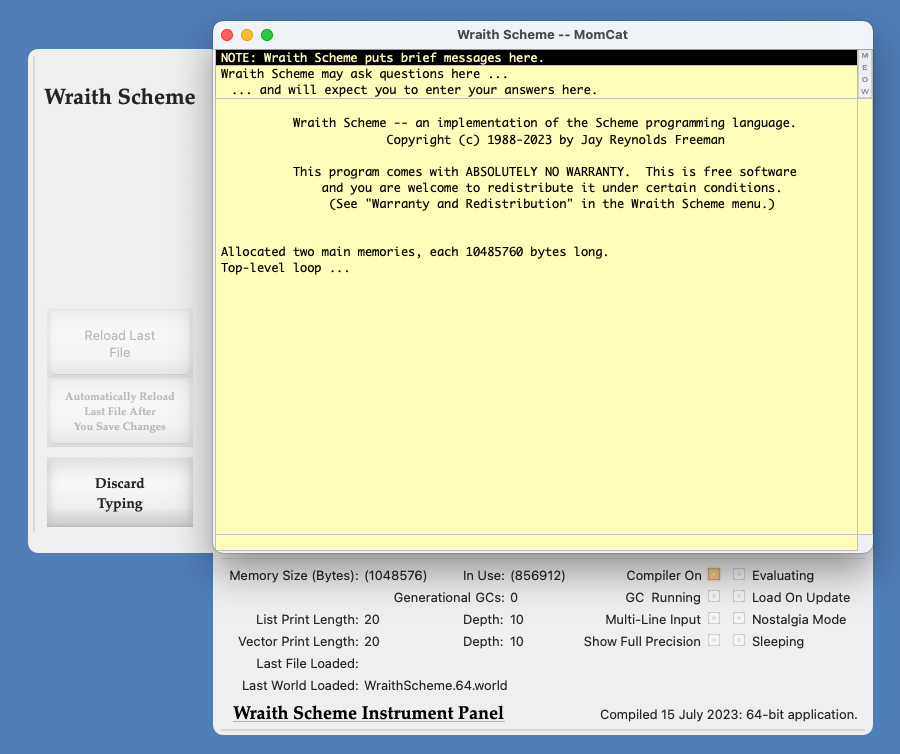
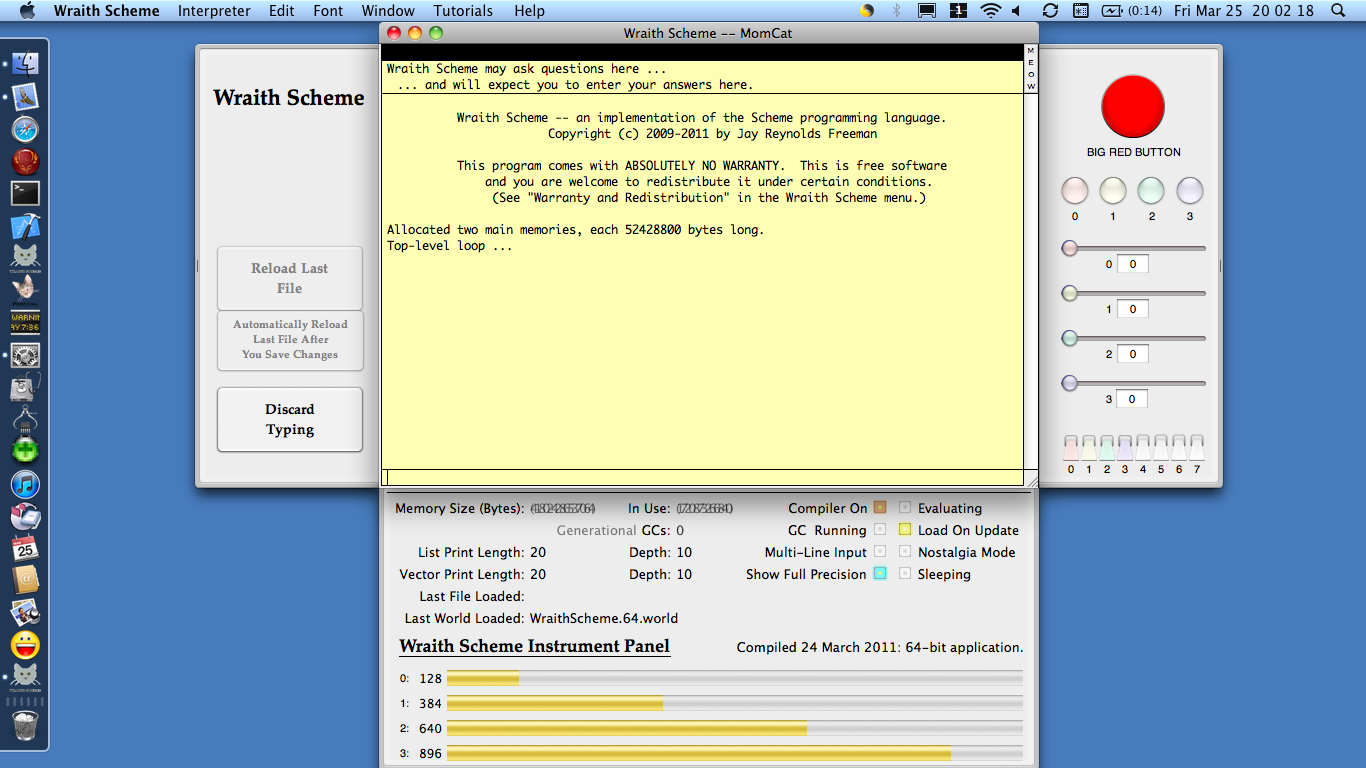
Just click on the Wraith Scheme icon, and away you go. The program will open up a window that looks like this:
The Wraith Scheme Main Window.
In case you can't read the image on your browser, the messages shown at startup will be something like:
Wraith Scheme -- an implementation of the Scheme programming language.
Copyright (c) 2009-2022 by Jay Reynolds Freeman
This program comes with ABSOLUTELY NO WARRANTY. This is free software,
and you are welcome to redistribute it under certain conditions.
(See "Warranty and Redistribution" in the Wraith Scheme menu.)
Allocated two main memories, each 10485760 bytes long.
Top-level loop ...
The "Top-level loop..." message means that Wraith Scheme has completed initialization and started doing what a Scheme interpreter does -- running an endless loop of reading Scheme code that you type in, processing (more precisely, "evaluating") what it read, and printing out the results.
Wraith Scheme Startup Actions:
On startup, Wraith Scheme
Note that it may take a long time to initialize large Wraith Scheme main memories. The exact time required depends on what kind of Macintosh you have, how much physical memory (RAM) is installed, and what other applications are running. As a rule of thumb, if the main memory size that you have requested is more than a quarter the size of the physical memory installed in your Macintosh, initialization delay may be vexing.
If you wish to run Wraith Scheme with a large main memory, I recommend that you start with a small main memory and increase its size in modest increments -- setting the memory size via Wraith Scheme's ""Preferences"" and relaunching Wraith Scheme -- in order to become familiar with the initialization times involved.
If Wraith Scheme were started up without loading such a world file, you would get a rather disfunctional version of Scheme: Not all of the language is "built in" to the Wraith Scheme program itself. What is there is a rather minimal subset of Scheme features, which are enough so that the rest of Scheme can be written using them. I make the start-up world file by running the minimal version of the program, loading some files of Scheme code that create the rest of Scheme from the built-in features, and saving the world that is thereby built.
Commands to load and save worlds are described later herein.
Changing the Startup Defaults:
All of Wraith Scheme's preferences take effect at startup, so as you learn later herein what those preferences are, remember that you can change Wraith Scheme's startup behavior by changing them.
In particular, you might write your own file to be loaded on initialization, and set the preferences to load it. Such a file might contain text like:
(define my-favorite-constant 42) (load "MyFavoriteSchemeCode.s") (load "../SomeOtherDirectory/SomeOtherSchemeCode.s") (begin (newline) (display "Hi, good looking!") (newline))
(By the way, Scheme source files do not have to end in ".s". That is merely a personal convention of my own.)
Alternatively, the file could load a Wraith Scheme world that you had previously saved.
Perhaps you would not like to have any file loaded at all at startup -- maybe you are sick of seeing the demonstration program run. In that case, delete the text in the "Load This Source File After Startup" field in the preferences window, so that it looks like this:

If you don't like the way the Wraith Scheme main window looks, there are plenty of ways to change its appearance. There is all the usual Macintosh stuff for customizing the user interface, and in particular:
The Font Menu.
The Window Menu.
Pull here.
While you are reading this section, remember that there is also a section called Common Problems and Solutions.
Wraith Scheme provides one main window, a few buttons, and a generous handful of menu items. The main part of the Wraith Scheme Window is where you do almost everything with the Wraith Scheme program -- things like entering Scheme source code, running it, and looking at the results. The buttons, menu items, and a few accessory panels -- Apple used to call them "drawers" -- that slide out from the main window, allow you to do things to the Wraith Scheme program -- things like setting options and taking control of Scheme programs that are misbehaving. They also allow you to keep track of what Wraith Scheme is doing.
There is one other way of interacting with Wraith Scheme that may be particularly useful: Wraith Scheme makes considerable use of "tooltips" -- the brief text descriptions that pop up when the cursor is positioned over particular areas of the screen. You can learn something about almost any visible feature of Wraith Scheme by moving the cursor over it and waiting for a tooltip to appear.
Note that Wraith Scheme requires ASCII characters for everything it does. (ASCII characters are pretty much the letters of the English alphabet and the standard punctuation marks -- what you could get from the keyboard of an old-fashioned typewriter.) That requirement includes the names of files and folders that Wraith Scheme might have to deal with, and in the case of files, it means that Wraith Scheme will complain if the folder containing the file has a name containing non-ASCII characters, or if the folder containing that folder does, and so on.
Technical Note: The requirement to use ASCII characters stems from the R5 report, which uses the ASCII character set to define what constitutes a "letter". It might be possible to interpret the R5 report as allowing non-ASCII characters in strings, and it would certainly have been possible to create a Scheme implementation that allowed all the fancy characters that the Macintosh can create. I chose to restrict the character set to ASCII to facilitate creating Scheme programs which can easily be adapted to run on other implementations of Scheme, that might not allow fancy Macintosh characters.
Let's discuss the window, buttons, and menu items in more detail:
The Wraith Scheme Main Window.
Mostly, you type Wraith Scheme commands into the Wraith Scheme window, and look there to see what happened.

The left end of the Input Panel.
You type into the panel at the bottom of the window that is one line tall and almost as wide as the whole window. That panel is surrounded by black lines. Input to Wraith Scheme is line-at-a-time. Wraith Scheme will process an entire line when you press the "return" key. If you are typing a Scheme expression that takes several lines and notice a mistake after you have already pressed the "return" key for that line, you can press the "Discard Typing" button, or use the corresponding menu item in the Interpreter Menu, to start over.
You do not need to have the cursor at the right end of the line when you press the "return" key. Wraith Scheme will get to process the entire line when you press "return", no matter where the cursor is positioned in the line.
The one-line panel where you type provides standard Apple text-editing capability, including cut-and-paste and drag-and-drop. It is in fact a scrolling window, though there is no scroll bar to tell you so, and only one line of its text will be visible at any given time. It also features a command history mechanism: You may use the up-arrow and down-arrow keys to scroll back and forth among lines of text that you have previously typed.
If you type a single line -- with no "return" -- that is longer than the Input Panel is wide, the line will "wrap", and you will only see the last part of it in the Input Panel. Don't worry. It's all there, and you can use the keys to move back and forth in a line to get to the first part of it, if necessary. Wraith Scheme will finally "see" the entire line, and start to process it, when you get around to pressing the "return" key.
When you have scrolled to a line that you previously typed, and have the cursor on that line, you may press "return" to send that line of text to Wraith Scheme again. You can re-enter a Scheme expression that spanned more than one line, one line at a time: Use the scroll commands to retrieve the first line of the expression, press "return", use the arrow keys to retrieve the second line of the expression, press "return", and so on.
The Macintosh's "cut-and-paste" and "drag-and-drop" mechanisms are very useful for entering Scheme expressions.
Although you can only edit one line of text in the Wraith Scheme window, Scheme commands may span more than one line. For example if you type (with a final "return")
( + 2 2 )
the effect is the same as if you had typed (again with a final return)
(+ 2 2)
That is, Wraith Scheme prints out
4
Wraith Scheme offers command name completion -- text completion for names of all the procedures and special forms that are described in the Wraith Scheme Dictionary. You may use this feature when you have either selected some text in the Input Panel, or are typing there, by pressing the "option" key and then the "escape" (esc) key.
In the following image, a user has typed in the text "call-with-", but has not yet pressed any other keys:
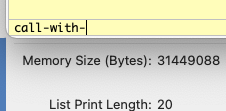
In the next image, the user has pressed the "option" key and then the "escape" key, and a drop-down menu has appeared, showing four possibilities for completion. Wraith Scheme has not suggested a choice; the user may select one from the menu by using the mouse or the up and down arrow keys.
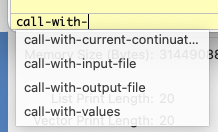
In the third image, the user has added the letter 'c', which provides enough text so that there is only one possible choice for completion. Wraith Scheme highlights that choice and sets up the Input Panel for the user to accept it. The user may decline, of course, by pressing the "option-escape" key combination once more, or by pressing the "delete" key; that will erase the additional text -- highlighted in the figure -- that Wraith Scheme has tentatively inserted, and leave things as they were.

Wraith Scheme also offers syntax information about the arguments of all the procedures and special forms that are described in the Wraith Scheme Dictionary. You may use this feature when you have either selected some text in the Input Panel, or are typing there, by pressing the "option-shift-escape" ("option-shift-esc") key combination.
In the following image, a user has typed in the text "(vector-set!", but has not yet pressed any other keys.

In the next image, the user has pressed the "option-shift-escape" key, and a drop-down menu has appeared, showing the one possible completion and the arguments it requires. Since there is only one possibility, it has been inserted into the Input Panel, selected and highlighted in blue.

In the third image, the user has accepted the completion, as a reminder while filling out the rest of the expression. Alternatively, the user could have declined it (by pressing "escape", for example), to leave the text as originally typed.
Finally, Wraith Scheme offers detailed command information about all the procedures and special forms that are described in the Wraith Scheme Dictionary. Highlight the complete command name in the Input Panel, like this:

Then press "command-option-F", and Wraith Scheme will open up the Wraith Scheme Dictionary in Safari at the position that describes that command.

Part of the Wraith Scheme Dictionary information for "cons".

The Main Display Panel, at reduced size.
The Main Display Panel is the big panel that covers most of the Wraith Scheme window. It shows copies of the text that you have submitted to Wraith Scheme, interspersed with whatever Wraith Scheme has printed out in response. You cannot edit that text, but you can select it for cut-and-paste or drag-and-drop to some other location, such as the Wraith Scheme Input Panel. The Main Display Panel scrolls too, using the scroll bar at the right edge of the main window.
Both the input window and the main display window can store essentially unlimited amounts of scrolled-back text, but if you want to reduce the amount of scroll-back, there is a "Trim Scrollback" menu item in the Interpreter Menu, that does so. Every time you use it, it trims off the oldest half of scrolled text in each window, down to 6000 characters. That is, this command will never reduce the amount of scrolled-back text in either window to fewer than 6000 characters.
The Message Panel is the top line of the Wraith Scheme window. Wraith Scheme will occasionally print messages there, that tell something about what the Wraith Scheme program is doing. One message that you will probably see a lot is "Garbage collection completed." Any message printed will go away after about ten seconds.
On fast Macintosh computers, messages in the message panel may well go by too fast to read, but on slow ones they will at least tell what is going on when you are waiting for Wraith Scheme to do something.

The Message and Dialog Panels.
As shown in the image above, the dialog panel consists of the second and third lines from the top of the Wraith Scheme window, which are isolated from the rest of the window by a horizontal line beneath them. Wraith Scheme will start a dialog with you by printing a prompt message in the first line of the panel, and will then move the cursor to the start of the second line of the panel and wait for you to enter your reply -- one line only. Type the line, using the same line-editing commands as for the main window, and type a final "return" when you are done.
As a visual cue that a dialog is in progress, the prompt message will flash.
You don't actually need to type a response: You may use cut-and-paste or drag-and-drop to make your response, as long as it's just one line long.
To remind you of what has been going on, Wraith Scheme will leave the text of the last dialog visible in the dialog panel, until the next dialog begins.
In a typical dialog, Wraith Scheme might ask you the name of a file to load.
Technical Note: I decided to use a text-based panel for these interactions, rather than use more conventional Macintosh-style browsers and dialog boxes, because the standard Macintosh mechanisms are for you to use. That is, they appear when you, the user, have done something in an application that causes them to appear. I thought that Wraith Scheme should stick to its own turf, so to speak, rather than do mysterious things with features you are used to manipulating personally.
Thus the idea is that, for example, when you decide to open a file, perhaps by a menu command, you get the standard kind of Macintosh browser window, but when a Scheme program needs to ask you to open a file, it uses the dialog box.
Apple stopped supporting "drawers" in the mid 2010s, and provided no alternative suitable for my purposes, so I developed a substitute, based on other user-interface features that Apple still does provide. I am adding this note to make clear that the "drawer" implementation that I have created is my own work (though making use of various Apple classes): I have not seen any Apple source code for NSDrawer, or disassembled or otherwise used any NSDrawer code. I still call these displayed items "drawers", both for consistency with my own previously written documentation, and because the visual appearance of something sliding out of the side of something larger strongly suggests that word. Note that when used with this meaning, "drawer" has few English-language synonyms.
The Basic Buttons Drawer.
The Basic Buttons Drawer slides out from the left side of the Wraith Scheme window. You make the drawer open and close with the "Show Basic Buttons" menu item in the Window Menu, or when the drawer is partly visible, you can drag the left edge of the drawer with the mouse to slide it in and out. It has the following features:

The Reload Last File and Automatically Reload Last File After You Save Changes buttons.
In the image immediately above, both buttons are enabled, and the "Automatically Reload Last File After You Save Changes" button has been pushed in. These buttons work like this:
Open a file in your favorite editor and start work on it. You can use any editor or word-processing application you like. When you are ready, save the file, and then use one of Wraith Scheme's commands to load it. You might use the "Load File" menu item of the Interpreter Menu for this purpose.
Unless you are very fortunate, the source code won't be right the first time, so you will have to make changes in the file. When you have saved the modified file, press the "Reload Last File" button to reload it. If you expect to make many changes in one editing session, you can press the "Automatically Reload Last File After You Save Changes" button as well -- it stays pushed in after you have pressed it -- so that Wraith Scheme will reload the file for you automatically whenever you save a new version. The Wraith Scheme Instrument Panel has a status light called "Load On Update", that indicates whether the "Automatically Reload Last File After You Save Changes" button is pressed in.
If you need to know what file these buttons will load, move the cursor over the "Reload Last File" button, and the full path to the file will pop up in a "tooltip". The name of the last file loaded is also displayed in the Wraith Scheme Instrument Panel.
These buttons only work after a file has been successfully loaded: Wraith Scheme won't worry about files that it couldn't locate or couldn't open. Furthermore, the buttons will not work -- they won't even be enabled so that you can press them -- until you have already loaded a file into the current session of Wraith Scheme: That is, these two buttons do not remember files from past sessions of Wraith Scheme.
Automatic reloading will occur in every Wraith Scheme process for which the "Automatically Reload Last File After You Save Changes" button has been pushed in. Normal practice would be to push in this button in only one Wraith Scheme window, but some files might be usefully loaded into multiple windows. See Kittens -- Parallel Processing in Wraith Scheme
Automatic reloads of updated files will not occur when Wraith Scheme is executing other code. When Wraith Scheme is not busy, it tests for updated files approximately every two seconds.
Technical Note: By any sane standard, "Automatically Reload Last File After You Save Changes" is way too long for a menu item or a button title. I used it because I could not think of a briefer description that adequately described what the button and menu item do. Automatic reload is a very valuable feature for developing programs; I wanted to make it easy for newcomers to Wraith Scheme to find out about it.

The Discard Typing button.
"Discard Typing" only works when you have not yet completed the expression. Once Wraith Scheme has received the final right parenthesis, or whatever it is that marks the end of the expression, Wraith Scheme will start processing it, and it is too late to think about starting over. The "Discard Typing" button will not be enabled at that time.
Technical Note: What "Discard Typing" actually does is tell Wraith Scheme to stop any processing it may be doing, and return to the top-level loop to await further input. (What that loop does is an endless cycle of read from the keyboard, evaluate what was read, and print the result.) Yet the "Discard Typing" button is not really a complete "reset" command, because it is disabled whenever Wraith Scheme has begun evaluating the input it has received. I thought it would be risky, having a big reset button out where you might click on it by mistake in the middle of a lengthy calculation, and lose the work that had been done. Wraith Scheme does have a complete reset command, in the Interpreter Menu, and that command has a keyboard equivalent, but the keyboard equivalent is a key combination that you are unlikely to type by mistake.
Thus if you type the following line into the input panel -- note the unbalanced parentheses -- followed by "return":
(+ 2 2
The little field at the bottom of the Basic Buttons drawer will remind you:
Expect )
Here are some images that show this field in operation:


Wraith Scheme will remind you when what you have typed has unbalanced parentheses or a missing quotation mark.
In the example image with the missing quotation mark, note that the newline character just after "users?" has been "escaped" with a '\' character. Wraith Scheme only allows strings to span multiple lines if the newlines are escaped in this manner, so if the '\' were not present, there would have been an error message about a missing double-quote.
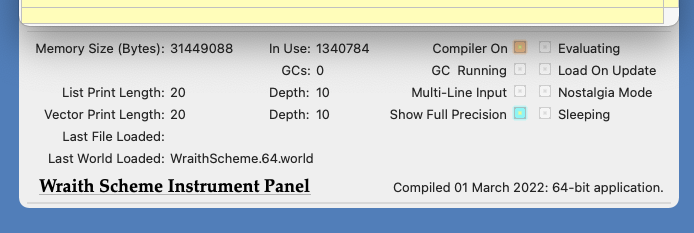
The Wraith Scheme Instrument Panel.
The Wraith Scheme Instrument Panel is a drawer that slides out from the bottom of the Wraith Scheme window. You make the drawer open and close with the "Show Instrument Panel" menu item in the Window Menu, or when the drawer is partly visible, you can drag the bottom of the drawer with the mouse to slide it in and out.
The instrument panel contains no buttons or other controls; all it does is display some information about what Wraith Scheme is up to and what it has been doing. Many of the items displayed are self-explanatory; the meanings of the others are described elsewhere herein. Don't forget to move the cursor over items to read the tooltips associated with them.
Three bits of text, near the top left and top center of the instrument panel, describe the amount of memory in use and the number of garbage collections that have taken place. Those text fields cycle between showing information for the main memory space and information for the small bit of memory that is the "active" generation, in use when the generational garbage collector is running. When the numbers that appear are in parentheses, and the label for GCs has the word "Generational" as part of it, the information displayed is about the space used for the active generation. The fields change from one kind to the other every five seconds. When the information displayed is for the generational garbage collector, the top left part of the instrument panel looks like this:

A portion of the Wraith Scheme Instrument Panel, showing the display for the generational garbage collector.
The instrument panel also shows the names of the last world file loaded, and of the last file of Scheme source code loaded. To see the complete path for either of these items, move the cursor over the file name, and the full path will pop up as a tooltip.
Several of the items displayed in the instrument panel are "status lights", that go on and off when the item whose status they monitor changes. If you don't think these are useful, I at least hope you think they are cute. Every computer ought to have status lights, preferably ones that blink a lot ...
The instrument panel also has an array of "sense lights", which are in effect panel lights similar in appearance to the status lights, whose appearance you get to control. They are normally invisible, but here is a figure that shows where they are and generally what they look like when you make them appear.
The Wraith Scheme sense light array, with most of the lights visible.
When Wraith Scheme is busy, the instrument panel display will lag well behind what Wraith Scheme is doing, but it will catch up when it gets the chance.
There is actually rather more to the Wraith Scheme Instrument Panel than meets the casual eye. If you mouse the bottom of the instrument panel and pull down, anywhere along the bottom border of the instrument panel ...

Mouse and pull down at the location of the arrow.
... you will find that there were some level indicators hiding above what you might have mistaken for the top of the instrument panel.

The Wraith Scheme Instrument Panel, showing the level indicators at the top.
The values displayed by the level indicators may be controlled from Wraith Scheme programs. How to do that is explained in the Level Indicators section. The image here is just to show you that they are there.
When the Wraith Scheme Instrument Panel is pulled out to its greatest extent, the height of the Main Window and Instrument Panel combined may be too large for the screens of some of the smaller Macintosh computers, in particular the old 11-inch model of the MacBook Air. In that case, you can reduce the height of the Main Window by dragging the little square below the Main Window scroll bar upward.
Pull here.
The next image is a screen shot from a MacBook Air 11, showing an older version of Wraith Scheme running with a slightly reduced main window size and the full Wraith Scheme Instrument Panel displayed. (The instrument panel was arranged differently on the earlier version.) To see the instrument panel on that small a screen, without interference from the Apple Dock, the Dock either had to be hidden or moved to one side of the screen.
Wraith Scheme running on a MacBook Air 11, considerably reduced.
When the Basic Buttons Drawer is partially open, and all other drawers are closed, the Wraith Scheme Main Window might look like the image that follows. Note that there is still enough of the buttons visible to click on them. You can save screen space this way, once you have become sufficiently familiar with Wraith Scheme to remember which button is which without reading the button titles.
The Wraith Scheme Main Window, with Basic Buttons Drawer partially closed.
When the Basic Buttons Drawer and Instrument Panel are both closed, the Wraith Scheme Main Window looks like this:
The Wraith Scheme Main Window, with all drawers and panels completely closed.
The Wraith Scheme Sensory Devices Drawer opens on the right side of the Wraith Scheme window. You can open it with an item in the Wraith Scheme Window Menu, or when the drawer is partly visible, you can drag the right edge of the drawer with the mouse to slide it in and out.
That drawer contains some input devices that you can mouse on in order to communicate with Wraith Scheme: It has five pushbuttons, four sliders, and eight sense switches. Here is an image showing what they look like.

The Sensory Devices Drawer.
These devices don't actually do anything until you write Wraith Scheme
programs to deal with them. How to do that is described in the
Sensory Input Devices section.
The image here is just to show you that they are there.
The Wraith Scheme Attic opens on the top of the Wraith Scheme window. You can open it with an item in the Wraith Scheme Window Menu, or when it is partly visible, you can drag the top of the drawer with the mouse to slide it in and out.
That drawer provides access to a variety of Wraith Scheme features and documentation that is not as well defined and not as well supported as the rest of the Wraith Scheme application, and which is likely to change substantially from release to release. Therefor I will not document the contents of the Attic here. Most Attic items have tooltips to describe them further -- move your graphics cursor over something to see the tooltip.
Activating items in the Attic will not interfere with the operation of Wraith Scheme itself. (Typically, pressing a button in the Attic opens a drop-down menu of other items to select.)
Here is a recent image of the Attic.
The Attic.
The Wraith Scheme Attic is like most attics: Many people will consider much
of what is in it to be junk, but some of you may find some of it useful or
interesting, and perhaps even both.

Wraith Scheme's complete menu bar.
The Wraith Scheme Menu.
The items in the Wraith Scheme menu are mostly Apple standards. Only four require special discussion for Wraith Scheme:
The preferences window contains three different displays -- one for general preferences, one for parallel processing, and one for garbage collection. You toggle back and forth between the three displays by pressing on the "General", "Kittens", and "GC" tabs at the top of the window.
With two exceptions, these preferences apply to as many Wraith Scheme processes as you have running; that is, if you are using Wraith Scheme parallel processing, then with two exceptions, setting any preference will cause that preference to be adopted by all Wraith Scheme processes -- the MomCat and all of her kittens -- the next time you start Wraith Scheme. The exceptions are the preferences for text color and background color in text areas: Those preferences apply only to the MomCat. Each kitten has its own default text and background color. Once a kitten is running, you may change those colors from the kitten's Font Menu, but Wraith Scheme will not remember your choices the next time it runs.
Since nearly all of the MomCat's preferences apply to all of the kittens, kittens do not have preferences menus: Each kitten's Wraith Scheme Menu has no entry for preferences.
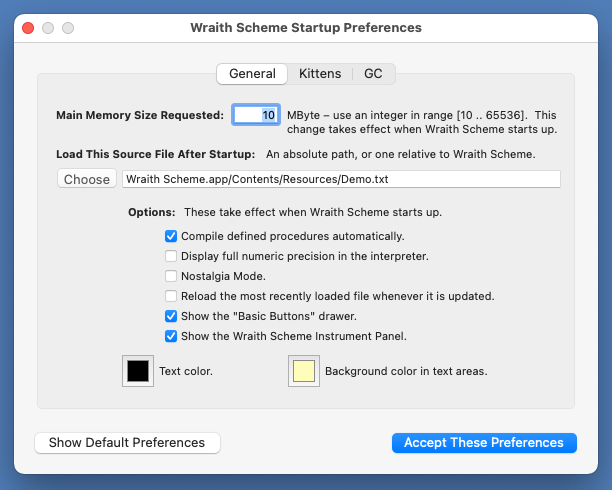
The General Preferences Window, showing default values of Wraith Scheme preferences that do not have to do with parallel processing or garbage collection.
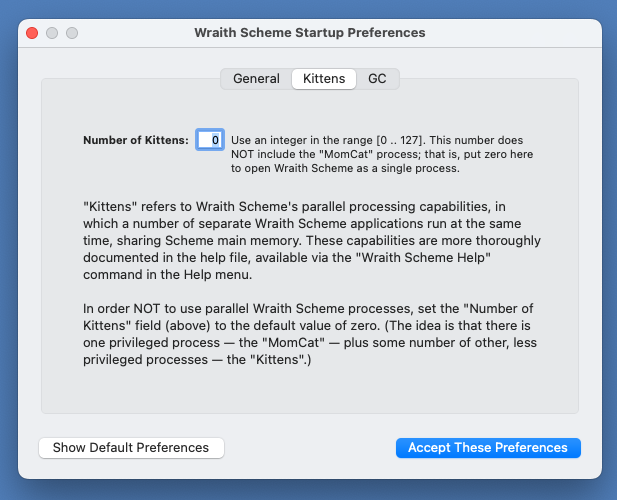
The Kittens Preferences Window, showing default values of Wraith Scheme preferences for parallel processing.
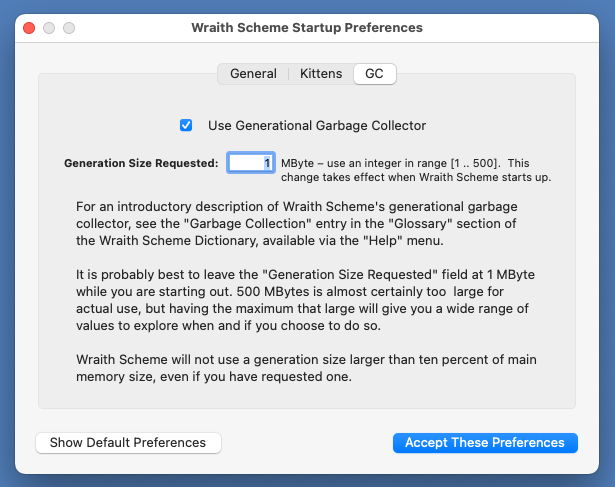
The Garbage Collection Preferences Window, showing default values of Wraith Scheme preferences for garbage collection.
Why do these items not take effect immediately? Why wait till the next time? Changes in a few items could in principle make something happen immediately, but it seemed more consistent, and easier to keep track of, if they all took effect at the same time. So the preferences are only used when Wraith Scheme starts running.
I suggest that if you want more memory, you should slowly increase the size set in the preference, restarting Wraith Scheme each time, to get a feel for what happens and for how long it takes on your computer: Wraith Scheme runs much more efficiently if the total memory it uses is well under the amount of RAM you have installed in your Macintosh, so it is probably a mistake to use more memory than you need.
Note that if you get a fatal-error message advising you to try using a smaller main memory size, you can open the Wraith Scheme preferences window then and there, before Wraith Scheme exits from the fatal error, to change the amount of memory Wraith Scheme asks for next time it runs.
Note that if you try to use a very large Wraith Scheme memory on a Macintosh with a small disk, or on a Macintosh with its disk nearly full, you may run out of available disk space.
There is a limit to how much memory Wraith Scheme can handle, though it is large enough probably not to be of any practical consequence. The limit is provided by limiting how big a memory-size preference you can set in the preferences window. The limit has different values on different kinds of Macintosh computers: On those with Intel processors, the maximum Wraith Scheme memory allowed is 800 MBytes. On those with "Apple silicon" processors, the limit is 65536 MBytes -- 64 GBytes.
The default setting for this item is a file contained within the Wraith Scheme application, that runs a short Scheme demonstration as an introduction to the language.
These two preferences affect only the MomCat. Each kitten has its own default text and background color. Once a kitten is running, you may change those colors from the kitten's Font Menu, but Wraith Scheme will not remember your choices the next time it runs.
There are menu items in the Wraith Scheme Font Menu that will let you change the MomCat window background color and text color at any time. Once again, what these "preferences" settings do is change how the MomCat window looks when Wraith Scheme starts up. After that, you may change the colors as you wish.
Generational garbage collections are much faster than full ones. So if response time is important you may want to use the generational garbage collector, to avoid long waits while the full garbage collector is operating. On the other hand, when Wraith Scheme is using the generational garbage collector, its average speed of operation is somewhat slower than when it is not. So if average speed, or time to complete an operation, is most important, you will probably want to turn the generational garbage collector off.
The combination of garbage collectors in use may be changed only via this preference item, which takes effect only when Wraith Scheme starts. There is no way to turn the generational garbage collector on and off while Wraith Scheme is running.
For a somewhat more detailed introduction to generational garbage collection, see the "Glossary" section of the Wraith Scheme Dictionary.
In any case, Wraith Scheme will not use a generation size larger than ten percent of main memory size, even if you have set the preference to be larger. Wraith Scheme will not change the preference setting in the window, it will simply refuse to do what you ask, and will start up the program with the smaller generation size instead.
For a somewhat more detailed introduction to generational garbage collection, see the "Glossary" section of the Wraith Scheme Dictionary.
There is one other matter about Wraith Scheme Preferences: When a group of Wraith Scheme processes runs in parallel -- as described in the section on parallel processing -- then only one of them -- the MomCat -- will actually have a preferences menu. The reason for that limitation is that most of the preferences available are common to all such processes, and a few of them apply to things that only the MomCat can do.
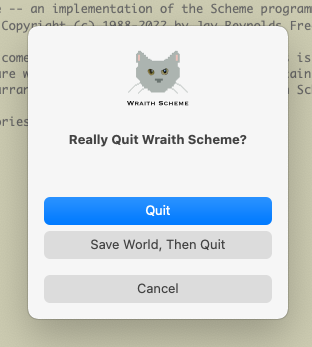
Wraith Scheme's Quit Panel.
In Wraith Scheme parallel processing, the MomCat is essential: Thus when you terminate the MomCat by the "Quit" command or by any other means, Wraith Scheme will do its best to terminate all other Wraith Scheme processes -- all the kittens -- that are running. Individual kittens are less essential: You may terminate one or more of them at any time, without jeopardizing the MomCat or any remaining kittens.
The Interpreter Menu items have to do with your interactions with Wraith Scheme in the Wraith Scheme window.
The Interpreter Menu.
The downside of any kind of "reset" command is the risk of using it by mistake, part way into a long calculation, and thereby losing lots of work and lots of time. For that reason, I did not provide a button for this menu item (if you have never pressed the wrong button of a computer application by mistake, you are a much better person than I am, or at least a much luckier one), and I chose a keyboard equivalent -- option-shift-command-delete -- that you are not likely to type accidentally.
There are three circumstances in which "Reset to Top-Level Loop" will not take effect: First, if Wraith Scheme is garbage-collecting, the reset will not take effect until garbage collection has finished. Second, if Wraith Scheme is sleeping, the reset will not take effect until it has waked up. There are blinking lights in the Wraith Scheme Instrument Panel to indicate when these things are happening. Third, a reset will not take effect while Wraith Scheme is starting up, because there isn't anything there to reset until startup is complete.
If Wraith Scheme is garbage-collecting or asleep when you use the "Reset to Top-Level Loop" command, the command will take effect eventually. If you use that command while Wraith Scheme is initializing, the command will simply be ignored: You will have to try again.
"Discard Typing" only works when you have not yet completed the expression. Once Wraith Scheme has received the final right parenthesis, or whatever it is that marks the end of the expression, Wraith Scheme will start processing it, and it is too late to think about starting over. The "Discard Typing" menu item will not be enabled at that time.
Technical Note: "Discard Typing" is actually "Reset to Top-Level Loop" by another name, but disabled whenever Wraith Scheme has begun evaluating the input it has received, so you can't ruin a long calculation by using this menu item accidentally.
Checking the "Disable Window Output" menu item causes Wraith Scheme to stop printing output into the Wraith Scheme Main Display Panel. Output that would have been printed there will be lost for good. Output to files, including transcript files, is not affected. Any text that you type, drag or paste into Wraith Scheme will appear in the window, but whatever response Wraith Scheme makes to your typing will not be printed.
When this menu item is checked, a panel opens up in the Wraith Scheme window, reminding you that output is disabled, and providing a button you may press to reenable it. You may also uncheck the menu item to reenable normal text output.
The reason for this menu item is that output to the main display panel is slow. If your Scheme program prints lots of things you don't need to see, you might disable output to speed things up. If you do so, however, make sure that any program results you want to preserve are either written to a file or bound to a variable that you can evaluate later, after re-enabling output.
One reason you might want to trim scrollback is that the operation of the main window gets slower and slower as more and more text is scrolled back. That is, Wraith Scheme slows down when there is a lot of text scrolled back.
It is up to you to make sure that the file you select for loading contains something that Wraith Scheme can understand; Wraith Scheme will report an error if it does not.
This menu item will only be enabled when Wraith Scheme is not busy with other processing; it doesn't usually make much sense to load a file at some random time while a Scheme program is executing.
This submenu remembers the names of files that you have loaded in previous sessions of Wraith Scheme, as well as files that you have loaded in the current session. Just because a file is named in the menu, doesn't mean that the code it contains is in Wraith Scheme at present: All the submenu does is relieve you of the task of remembering the names and paths to files that you have recently loaded, and might want to load again.
The submenu can hold the names of up to forty different files. It also has a menu item to clear out all the file names, in case you are tired of looking at them. That menu item only removes the file names from the submenu; it doesn't do anything to the files themselves.
This menu item will only be enabled when Wraith Scheme is not busy with other processing, and when there are actually some file names on it.
I have increased the number of file names displayed in this submenu several times, as the numbers of files in my personal Scheme projects get larger and larger.
The name of the last file that Wraith Scheme loaded in the current session of Wraith Scheme is also displayed in the Wraith Scheme Instrument Panel.
Open a file in your favorite editor and start work on it. You can use any editor or word-processing application you like. When you are ready, save the file, and then use one of Wraith Scheme's commands to load it. You might use the "Load File" menu item, discussed above, for this purpose.
Unless you are very fortunate, the source code won't be right the first time, so you will have to make changes in the file. When you have saved the modified file, use the "Reload Last File" menu item -- or press the corresponding button -- to reload it. If you expect to make many changes in one editing session, you can check the "Automatically Reload Last File After You Save Changes" menu item -- or use the button -- as well, so that Wraith Scheme will reload the file for you automatically whenever you save a new version.
If you need to know what file these menu items will load, move the cursor over the "Reload Last File" button, and the full path to the file will pop up in a "tooltip". The name of the last file loaded is also displayed in the Wraith Scheme Instrument Panel.
These menu items only work after a file has been successfully loaded: Wraith Scheme won't worry about files that it couldn't locate or couldn't open, for example. Furthermore, the menu items will not work -- they won't even be enabled so that you can use them -- until you have already loaded a file into the current session of Wraith Scheme: That is, these two menu items do not remember files from past sessions of Wraith Scheme.
Automatic reloads of updated files will not occur when Wraith Scheme is executing other code. When Wraith Scheme is not busy, it tests for updated files approximately every two seconds.
Automatic reloading will occur in every Wraith Scheme process for which the "Automatically Reload Last File After You Save Changes" menu item has been checked. Normal practice would be to use this menu item in only one Wraith Scheme window, but some files might be usefully loaded into multiple windows. See Kittens -- Parallel Processing in Wraith Scheme
CAUTION!! Loading a world overwrites everything in Wraith Scheme's memory!
Using the "Load World" menu item and then selecting a file which is not a saved world may cause Wraith Scheme to throw up its paws and quit: Wraith Scheme will try to make sure that any file you provide as a world to load really is a saved world, but you should not count on its ability to do so. (By the way, the way you create "saved worlds" is by using Wraith Scheme itself. We'll see how later herein.)
The name of the last world file loaded is displayed in the Wraith Scheme Instrument Panel.
This menu item will only be enabled when Wraith Scheme is not busy with other processing; it rarely makes any sense to load a world at some random time while a Scheme program is executing.
You may give a saved world any name you wish, but the suffix -- the part after the last '.' in the file name -- ought to be "world", and I have set up the file-selecting window to require it.
Saved worlds can be loaded only into the release of Wraith Scheme from which they were originally saved.
This menu item will only be enabled when Wraith Scheme is not busy with other processing; it rarely makes any sense to save a world at some random time while a Scheme program is executing.
This menu item toggles between the "number->string" mechanism and a simpler output format, in which floating-point numbers are displayed with at most seven decimal digits, and explicit exact and inexact prefixes ("#e" and "#i") are not used. This toggling applies only to the procedures "display" and "write", and to output at top level in the Wraith Scheme window. The strings returned by "number->string" itself remain unchanged. The internal representations of numbers remain unchanged.
I put in this feature because some people use a Scheme interpreter as a very fancy calculator, and they might get tired of looking at numbers in unnecessarily long formats. Furthermore, the use of the full precision of "number->string" sometimes produces counterintuitive least-significant digits. Thus if you are using the full precision and type in
(/ 1 3)
Wraith Scheme will print
0.33333333333333331
which is correct in terms of "number->string" -- that is, that number is the best approximation to (/ 1 3) that the system can provide -- but that final "1" might look suspicious if you were expecting "3"s to infinity, and beyond.
The Interpreter Menu has a submenu, the Shortcuts for Typing Menu, which contains five menu items useful for typing into the Input Panel. Each of those menu items has a keyboard shortcut.

The Shortcuts for Typing Menu.
This keyboard shortcut will not work if the cursor or any part of the selected text lies within a line of text other than the most recent one; that is, if you have had to use the Wraith Scheme command history mechanism to scroll back to the text in question.
This keyboard shortcut will not work if the cursor or any part of the selected text lies within a previous line of text; that is, if you have had to use the Wraith Scheme command history mechanism to scroll back to the text in question.
This keyboard shortcut will not work if the cursor or any part of the selected text lies within a line of text other than the most recent one; that is, if you have had to use the Wraith Scheme command history mechanism to scroll back to the text in question.
This keyboard shortcut will not work if the cursor or any part of the selected text lies within a line of text other than the most recent one; that is, if you have had to use the Wraith Scheme command history mechanism to scroll back to the text in question.
The Edit Menu.

The Find Submenu of the Edit Menu.
The menu item "Find in Wraith Scheme Dictionary" searches the Wraith Scheme Dictionary for an entry for whatever text is selected, and displays the result in Safari. If it cannot find such an entry, it displays nothing. (If you happen to have Safari open and visible on your desktop, you may see a window into the Wraith Scheme Dictionary open briefly while Wraith Scheme is searching, but that window will not remain open if there is no entry to be found.)
The Font Menu.
The font menu allows you to increase ("Bigger") or decrease ("Smaller") the font size in the Wraith Scheme window, within limits. The smallest font available is 9 point, and the largest is 36 point. When you use these menu items, the size of all text in the Wraith Scheme window changes all at once -- they aren't "mark and click" style menu items.
The "Change Text Color..." menu item opens up a small window that allows you to change the text color Wraith Scheme uses. That small window contains a standard Macintosh "color well" that you may use to select a color. Once you have done so, use the "Preview" button to see how the color looks in the Wraith Scheme window. When you have a color you like, use the "Done" button to make the small window close. Alternatively, use the "Cancel" button to leave the background color the way it was when the small window first opened.
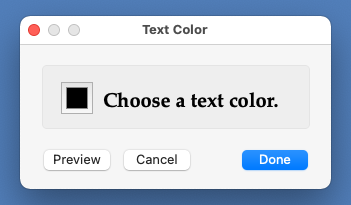
The Change Text Color Window.
When you use the "Change Text Color..." menu item for the MomCat to pick a new text color, and press the "Done" button, Wraith Scheme will ask if you want to make the new color a preference, so that it will automatically be used the next time Wraith Scheme starts up. If you reply "Yes", Wraith Scheme will put the new color into the "Preferences" window on your behalf. Wraith Scheme will not offer that option when you change text color for a kitten, because kitten text colors are not remembered in Wraith Scheme preferences.
The "Change Background Color..." menu item opens up a small window that allows you to change the background color of areas where Wraith Scheme displays text. That small window contains a standard Macintosh "color well" that you may use to select a color. Once you have done so, use the "Preview" button to see how the color looks in the Wraith Scheme window. When you have a color you like, use the "Done" button to make the small window close. Alternatively, use the "Cancel" button to leave the background color the way it was when the small window first opened.
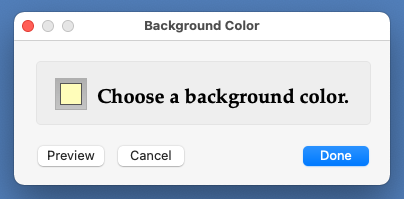
The Change Background Color Window.
When you use the "Change Background Color..." menu item for the MomCat to pick a new background color, and press the "Done" button, Wraith Scheme will ask if you want to make the new color a preference, so that it will automatically be used the next time Wraith Scheme starts up. If you reply "Yes", Wraith Scheme will put the new color into the "Preferences" window on your behalf. Wraith Scheme will not offer that option when you change background color for a kitten, because kitten background colors are not remembered in Wraith Scheme preferences.
The Window Menu.
Most of the contents of the Window Menu are standard Apple menu items. but seven are not:

The Tutorials Menu.
The Tutorials Menu provides links to a variety of tutorials about different aspects of the Scheme language in general or of the Wraith Scheme program in particular. The idea is to read a tutorial in Safari while running Wraith Scheme, and perhaps occasionally cutting and pasting sample code from the tutorial into Wraith Scheme, to see what it does.
I believe the menu item titles are reasonably self-explanatory. Therefore, I will not describe the individual tutorials here.
I cannot give sensible suggestions for the order in which you should read the tutorials. The right order for you will depend on what you are interested in, and on your previous familiarity with programming language interpreters, with Lisp-class programming languages, and with Scheme. I might suggest that everyone at least glance at the first tutorial, "Introduction", and then decide whether to read more.

The Help Menu.
The Help Menu provides access to some rather lengthy HTML files that tell how to use Wraith Scheme.
This file opens in Safari; if Safari is not installed, or is somehow not available, Wraith Scheme will not be able to open the file for you. Later in this section is a description of another way to open the file.
This file opens in Safari; if Safari is not installed, or is somehow not available, Wraith Scheme will not be able to open the file for you. Later in this section is a description of another way to open the file.
This file opens in Safari; if Safari is not installed, or is somehow not available, Wraith Scheme will not be able to open the file for you. Later in this section is a description of another way to open the file.
These files open in Safari; if Safari is not installed, or is somehow not available, Wraith Scheme will not be able to open the files for you. Later in this section is a description of another way to open these files.
This file opens in Safari; if Safari is not installed, or is somehow not available, Wraith Scheme will not be able to open the file for you. In that case, keep reading ...
If for some reason you would like to access these files by some means other than using the menu items, there's a way. The files themselves are buried deep within the Wraith Scheme application. To find them:
There is another way to think about how you may interact with Wraith Scheme:
There are ten ways for Wraith Scheme to provide information to you:
There are seven ways for you to provide information to Wraith Scheme:
When Wraith Scheme encounters an error from which it can recover, its general strategy is to print an error message -- I hope a useful one -- in the Main Display Panel, then abort whatever Scheme processing is going on and return control to you at "top level" in the Wraith Scheme window. For example, suppose you tried to add using a Scheme object that is not a number. You might type:
(+ 2 #t)
whereupon Wraith Scheme would print
#<Built-in procedure "+"> applied to (2 #t):
-> #t
Expected a number for argument list item 1 (zero-based).
Problem: Marked argument has improper type for this operation. (Resetting)
Top-level loop ...
A similar error message, and a similar return to the "top level" of control of Wraith Scheme, would occur even if the problem occurred deep in some elaborate Scheme procedure.
Wraith Scheme may also encounter errors from which no recovery is possible, in which case its general strategy is to open a special panel to present an error message, and then exit. If you should ever see a fatal error message whose cause is not obviously due to some system limitation (such as not having enough memory), I would like to hear about it: Send bug reports to Jay_Reynolds_Freeman@mac.com.
(e::exit)
and then type "return". (That Scheme command is one of the
Enhancements provided by Wraith Scheme.)
This procedure causes an immediate exit: Wraith Scheme will not
ask you to confirm that you really do want to quit. (That omission
provides a way to run a Scheme program that can exit automatically
when it is done.)
This way to quit only works if the Wraith Scheme window is accepting
commands, which it won't be, for example, if a long Scheme procedure
is running; you might have to use the "Reset to Top-Level Loop" menu
item or command -- described a few paragraphs above -- first.
In
Wraith Scheme parallel processing,
the
MomCat
is essential: Thus when you terminate the MomCat by any of these means,
Wraith Scheme will also terminate all other Wraith Scheme processes -- all the
kittens --
that are running.
Reclaiming memory that is no longer in use is an important part of any computer application, and Lisp systems of all kinds have long been equipped with "garbage collectors" to perform that task. Wraith Scheme used to have just one of them, but now it has two, so it is important to tell you a little about what they are, how they work, and how and why to choose between them.
Wraith Scheme has always had a full garbage collector, and as of Wraith Scheme 2.10 it also has a generational garbage collector. These two systems are not completely independent, as we shall soon see. The reason for having two systems is that the full garbage collector sometimes takes an objectionable amount of time to do its job: Wraith Scheme will just sit there, with the red "GC Running" light in the Wraith Scheme Instrument Panel turned on, for long enough to bother you, or perhaps long enough to cause problems if you are using Wraith Scheme to control any kind of real-time process.
The generational garbage collector addresses this problem by doing frequent garbage-collection operations that each only collect a little bit of garbage. Since the amount of garbage collected per collection is small, the operations are fast, and Wraith Scheme is more responsive. On the other hand, the combined time to set up and do many small collections turns out to be more than the time required for one full collection that collects the same amount of garbage, so Wraith Scheme's overall speed is lower when the generational garbage collector is running, than when it is not.
Furthermore, the generational garbage collector is not as efficient as the full one: Some garbage sneaks through it without being collected. Therefore, even when the generational garbage collector is running, Wraith Scheme has to do a full garbage collection occasionally.
You get to decide for yourself which garbage collector to use: There is a check box in the Wraith Scheme Preferences to specify whether you want the generational garbage collector or not. The default setting is to use it, but the choice is yours.
You cannot change which garbage collector is in use while Wraith Scheme is running. If you want to switch from one to another, the only way to do so is to change the preference, then quit Wraith Scheme and restart it.
In that circumstance, the generational garbage collector is slightly more vulnerable to out-of-memory problems than the full garbage collector, in that if the generational garbage collector runs out of memory, there is some chance that you will have to restart Wraith Scheme. The full garbage collector is more likely to give you an opportunity to fix things and then continue, without restarting.
This section includes some hints based on my own personal experience in using Wraith Scheme. What's here is in no sense required practice, or even best practice, it is just a list of miscellaneous tips that have made my own life easier when I myself use Wraith Scheme to develop and run programs.
Some of these matters are complicated, in the sense that you may need more than just a little knowledge of programming and the Unix / macOS operating system in order to understand what I am talking about. If that happens, I apologize, and it won't do any harm to ignore that suggestion entirely.
Herein I describe how Wraith Scheme differs from "R5" Scheme by going through the Revised5 Report on the Algorithmic Language Scheme, section by section, and listing differences between Wraith Scheme and that standard. It is my intention that any essential or non-essential feature of Scheme that is mentioned in the R5 report, is either provided as described in the R5 report, or mentioned here with an indication of how Wraith Scheme differs from the R5 report.
One major difference is that Wraith Scheme provides numerous enhancements and special features, in great part in the form of extra built-in procedures and constants whose identifiers generally begin with "e::" or "c::". I mention some of these features in passing in this section, keeping the descriptions brief for clarity of presentation. I have described them in more detail in a separate Enhancements section.
I have summarized the R5 features that Wraith Scheme lacks, in the Optional Features Omitted section. Each missing feature is also mentioned separately in the discussion of the appropriate section of the R5 report, below.
Note that all of Wraith Scheme's procedures and special forms are described in detail, with examples and discussion, in the Wraith Scheme Dictionary, which accompanies Wraith Scheme and may be opened using the Wraith Scheme Help Menu.
Some procedures that take string arguments will ask you to type in the string to be used when they are called without the argument that normally provides that information. These procedures use the Wraith Scheme Dialog Panel for that purpose.
For example, the conventional operation of
(open-input-file "foo")
is to open an input file named "foo" -- or at least try to -- whereas
(open-input-file)
will ask you to type in the file name to open. Similarly,
(make-string)
asks you to type in the intended content of the string. The full list of standard Scheme procedures that are modified to work this way in Wraith Scheme is:
make-string load call-with-input-file call-with-output-file with-input-from-file with-output-to-file open-input-file open-output-file transcript-on
Several non-standard procedures, described in the "Enhancements" section, also work this way.
1.3.1:
Unless otherwise stated, Wraith Scheme supports all features of Scheme, including optional ones, that are described in the R5 report.
1.3.2:
Wraith Scheme attempts to print sensible error messages for errors indicated in the R5 report, even when the R5 report does not require that an error be signaled. In general, Wraith Scheme will print an error message and then return control to the top level of the Scheme interpreter. If the error occurred within a user-defined function, Wraith Scheme may provide some rudimentary debugging information, such as the names of functions on the call stack when the error occurred.
Some errors are fatal: For them, Wraith Scheme will in general display an error message in a special panel, and then exit.
Where R5 states that the value of an expression is unspecified, Wraith Scheme generally returns #t.
1.3.5:
Wraith Scheme provides numerous functions and variables as enhancements to R5 Scheme, and distinguishes them by naming conventions. In particular, Wraith Scheme uses symbols which begin with the characters "e::" for enhancements that in my opinion will probably be of broad interest to users, and "c::" for more specialized enhancements that will probably be less generally useful. For example,
e::exit
names a function of no arguments which may be called to exit from Wraith Scheme.
The syntax of these naming conventions was inspired by various "package" and "namespace" mechanisms used in other Lisp implementations. Wraith Scheme has a package and namespace mechanism, but the enhancements do not make explicit use of it; that is, "e::" and "c::" are just some of the characters in the identifier. The reason why they don't is because I started creating enhancements long before I decided to add a package mechanism to Wraith Scheme.
2.1:
Identifiers in Wraith Scheme are independent of alphabetic case. Thus for example, Wraith Scheme considers "define", "DEFINE", "Define", and "dEfiNE" all to be the same identifier.
Wraith Scheme prints identifiers with lower-case letters. Thus
'dEfiNE
returns
define
There is a well-known "gotcha" in the specification of identifiers in the R5 report: The language of that report allows identifiers to begin with the character '@', but the use of such identifiers creates syntactic confusion with the symbol ",@" that Scheme uses as shorthand for "unquote-splicing". Thus, consider the Scheme expression
`(a b ,@c)
Is that to be understood as
(quasiquote (a b (unquote @c)))
or as
(quasiquote (a b (unquote-splicing c)))
Given the possibility that identifiers begin with '@', Scheme has no way to distinguish between the two interpretations.
Therefore, in Wraith Scheme, identifiers may not begin with '@': The character '@' may occur within an identifier only in positions other than the first letter.
All identifiers that are syntactic keywords, all identifiers associated with procedures defined in R5, and all identifiers for enhancements provided by Wraith Scheme, are bound to the code that executes those procedures, in a manner difficult to change. You must undo these "permanent" bindings in order to perform such interesting operations as "(set! cons ...)". Wraith Scheme uses an internal flag for each binding to indicate whether it is permanent, and provides the functions "e::permanent?", "e::set-permanent!" and "e::clear-permanent!" -- each taking an identifier as argument -- for your own use, at your own risk. For example
(e::permanent? 'define)
returns #t.
Wraith Scheme does not uniformly allow syntactic keywords to be used as variables, though the mechanisms used to implement hygienic macros will sometimes allow you to get away with doing so.
2.2:
Wraith Scheme recognizes tabs, carriage returns, newlines and blank spaces, as whitespace.
No comments.
4.3:
In addition to the hygienic macro implementation described in this section of the R5 report, Wraith Scheme has an additional, low-level macro implementation, described in Macros -- An Alternate Implementation.
5.2:
Wraith Scheme will not always report an error if internal definitions are used incorrectly within what the R5 report calls a "<body>"; that is, at locations in the <body> other than at the beginning. Internal definitions at locations within a <body> other than at the beginning bind and assign within the top-level environment, not locally. Internal definitions at the beginning of a <body> act within the local environment of that <body>.
That is not to say that you should put definitions in such places.
In Wraith Scheme, "define" recursively searches the expression being bound or assigned for macro "calls", and expands any that it finds.
Wraith Scheme allows optional automatic compilation of top-level defines, by means of the "compile defines" item in the Interpreter Menu. Any such compilation takes place after macro expansion, and only for procedures defined using the procedure-defining syntax that involves parentheses around the name and formal parameters.
Wraith Scheme does not support irrational numbers.
Wraith Scheme's support for rational numbers in which the numerator and denominator are stored as separate values is limited to numbers in which both the numerator and the denominator are within the range of 64-bit signed integers. In other circumstances, Wraith Scheme generally divides the numerator by the denominator and remembers only the quotient.
Wraith Scheme's rational numbers in which the numerator and denominator are stored separately are anticontagious in the sense that Wraith Scheme arithmetic and mathematical operations will not attempt to produce such numbers as results unless all of their inputs are of that kind. (Those operations of course may not even be able to produce such results at all, if the mathematically correct results would require the use of integers outside the range of 64-bit signed integers.) Furthermore, Wraith Scheme's transcendental functions will not attempt to produce such results, "sqrt" will not attempt to do so unless its input is itself a perfect square of either an integer or a fraction, and "expt" will only attempt to do so for a power that is a nonnegative integer.
You may create rational numbers in which the numerator and denominator are stored separately as literal constants, by using the input form
<numerator>/<denominator>
e.g.
-1/3
or you may use the procedure "e::make-long-ratnum", which is one of Wraith Scheme's enhancements for dealing with such numbers.
Wraith Scheme supports four internal representations for numbers: 64-bit signed fixnums (which I sometimes call "fixnums"), IEEE 64-bit flonums (which I sometimes call "flonums"), and two long forms which I call "long complexes" and "long ratnums". Long complexes are used for complex numbers with nonzero imaginary part. A long complex contains two numbers. Each may be either a fixnum, a flonum or a long ratnum. The two numbers are the real and imaginary parts of the complex number. Long ratnums are used for rational numbers in which the numerator and denominator are both remembered separately; they are both stored as fixnums.
A number stored in either of the 64-bit formats is necessarily either an integer or a rational. Therefore, the procedures "rational?" and "real?" will always return #t when applied to any number stored by Wraith Scheme that has zero imaginary part, and will of course return #f when applied to any number stored by Wraith Scheme that has nonzero imaginary part. These procedures, as well as "integer?" and "complex?", will return #f when applied to any Wraith Scheme number that contains a IEEE floating-point infinity or nan.
There was a problem in the implementation of "eqv?" required by the R5 report, when dealing with complex numbers. I have resolved the difficulty as later specified in the R6 report.
The problem was that the R5 report required two complex numbers to be "eqv?" if both had the same numeric values for their real and imaginary parts, and if both also had the same value of the exact bit. Thus in particular:
(define a 1.+1i) ;; ==> a (define b 1+1.i) ;; ==> b (eqv? a b) ;; ==> #t (in pure R5 Scheme).
because both 1+1.i and 1.+1i are inexact. The idea of "eqv?", however, was to capture the notion that equivalent objects give the same result when subject to arbitrary Scheme operations, and in that context it was disturbing that
(real-part a) ;; ==> 1. (an inexact number) (real-part b) ;; ==> 1 (an exact number)
that is, that the real parts of two supposedly equivalent quantities were not the same, one being exact and the other inexact. (The same was true of the imaginary parts of a and b as well.)
Wraith Scheme resolves this dilemma by enforcing the rule that a complex number is exact if, and only if, it exactly describes a single point in the complex plane. If it does, Wraith Scheme will make both its components exact, and if not, Wraith Scheme will make both of its components inexact. Thus:
(define a 1.+1i) ;; ==> a (define b 1+1.i) ;; ==> b (eqv? a b) ;; ==> #t (equal? a b) ;; ==> #t (= a b) ;; ==> #t (exact? (real-part a)) ;; ==> f (exact? (real-part b)) ;; ==> f (exact? (imag-part a)) ;; ==> f (exact? (imag-part b)) ;; ==> f
Note that even if a complex number is exact, its angle and magnitude may not be, because of the limits of the trigonometric and irrational functions used to obtain them.
6.2.3:
Wraith Scheme attempts to preserve maximum accuracy and precision when doing arithmetic. Thus in general, operations yield a result with at least as much precision as the most precise of their operands.
The IEEE floating-point standard provides representations to indicate when floating-point overflow has taken place, and to indicate when an operation cannot produce a numeric result. These representations are called "infinities" and "nans". ("Nan" stands for "not a number".) Wraith Scheme handles these representations so as to facilitate calculations: Procedures that both accept and return numeric values generally accept infinities and nans without balking, and return whatever value is appropriate. However, procedures which perform an explicit or implicit ordering of numeric values report an error when called with a nan as argument. Those procedures are:
= < > <= >= max min positive? negative?
Furthermore, the procedures
= < > <= >= max minreport an error when asked to compare two infinities of the same sign.
The type-checking procedures
number? complex? real? rational? integer?
return #f when called with either an infinity or a nan as an argument, or when called with a complex argument in which one or both of the real and imaginary parts is an infinity or a nan.
Infinities and nans are always inexact.
Wraith Scheme has some procedures to tell whether Scheme objects are infinities or nans. These procedures are enhancements.
Wraith Scheme prints all nans as "nan", and all infinities as "inf". The printed representations of infinities make no distinction between positive and negative infinities, though the internal representations are in fact signed, and their signs can be determined by such procedures as "positive?" and "negative?".
Wraith Scheme will produce infinities or nans when it detects an attempt to divide by zero, and when reading a numeric constant expressed in the form of a fraction that would produce an infinity or a nan if the implied division were performed.. Thus for example, entering
1/0will return
infand similarly,
0/0will return
nan
The general use of infinities and nans was a design choice. Alternatively, I might have arranged to report errors.
6.2.4:
The syntax of Wraith Scheme's numeric constants is insensitive to alphabetic case. #E works as well as #e, #Xfeed is just as good a hexadecimal representation of 65261 as is #xFeeD, 2.0E0 represents the same number as 2.0e0, and so on.
Wraith Scheme allows numeric constants to be written as fractions -- such as 22/7 -- and will store the numerator and denominator separately, as long as both numerator and denominator are within the range of fixnums. See the section on Internal Representations of Numbers. If numerator or denominator is outside of that range, Wraith Scheme will perform the implicit division and return a flonum.
Wraith Scheme will not override a user's use of an explicit exact prefix ("#e") with a number if the number contains too many digits to be stored exactly.
Wraith Scheme will report an error when a string used to represent a numeric constant contains both an explicit "exact" prefix ("#e") and one or more sharps in places where digits might be expected. Thus the text string
#e12##
-- which might conceivably be intended as a number with value somewhere near 1200 -- is not recognized as a number by Wraith Scheme.
Wraith Scheme will report an error when characters are used in the written representation of a number that are inappropriate for the implicit or explicit radix. Thus if you enter
12a3
or
#d12a3
Wraith Scheme will report an error, whereas
#x12a3
will evaluate to
4771
Internal Representations of Numbers:
Wraith Scheme supports four internal representations for numbers: 64-bit signed fixnums (which I sometimes call "fixnums"), IEEE 64-bit flonums (which I sometimes call "flonums"), and two long forms which I call "long complexes" and "long ratnums". Long complexes are used for complex numbers with nonzero imaginary part. A long complex contains two numbers. Each may be either a fixnum, a flonum or a long ratnum. The two numbers are the real and imaginary parts of the complex number. Long ratnums are used for rational numbers in which the numerator and denominator are both remembered separately; the two numbers are the numerator and the denominator, each stored as a fixnum.
Wraith Scheme generally uses 64-bit fixnums to store signed integers from -9,223,372,036,854,775,807 through 9,223,372,036,854,775,807, (that number is two to the sixty-third power, less one) and uses IEEE 64-bit flonums to store real numbers outside that range. Notwithstanding, it is possible that an integer in the range -9,007,199,254,740,991 through 9,007,199,254,740,991 (that number is two to the fifty-third power, less one) will be stored as an IEEE 64-bit flonum: That storage form has enough bits to store such integers without loss of precision.
Wraith Scheme generally observes "flonum contagion", in that when at least one of the operands of a mathematical operation is an IEEE 64-bit flonum, the result will usually be an IEEE 64-bit flonum.
When converting from an external representation of a number to an internal representation, Wraith Scheme will take the presence of any of the normal Scheme exponent markers -- "d", "e", "f", "l", and "s", or the same letters as capitals -- as reason to store the number in question as an IEEE 64-bit flonum.
6.2.5:
The procedures "=", "<", ">", "<=" and ">=" each take two or more arguments. The procedure "=" returns #t if and only if its arguments are all equal. The procedure "<" returns #t if and only if its arguments form a sequence that is strictly increasing; that is, if and only if each of its arguments is greater than its neighbor to the left (if any) and less than its neighbor to the right (if any). The other procedures have similar semantics.
The procedures "quotient", "remainder", "modulo", "gcd" and "lcm" are implemented only for integer arguments whose absolute value is less than 9,223,372,036,854,775,807. If they are called with integer arguments that happen to be stored as flonums, not as fixnums, then they will report an error if any such argument is outside the range in which it can be stored as a flonum without loss of accuracy.
The error messages for out-of-range arguments will state that the argument is of improper type, but will not specifically mention that the problem is one of range. These messages may be confusing if you have not noted the range limit just given.
Furthermore, if the algorithm for "lcm" requires a temporary value outside this range, Wraith Scheme will be unable to finish without loss of precision, and will report an error.
Subject to the error conditions just mentioned, "gcd" and "lcm" return IEEE 64-bit flonums when one or more of their arguments are IEEE 64-bit flonums.
6.2.6
Procedure "string->number" recognizes numbers written in fraction notation, and will return a number that stores the numerator and denominator separately, as long as both numerator and denominator are within the range of integers. Procedure "number->string" will print such a number as a fraction.
If a complex number has a non-zero imaginary part, Wraith Scheme will store each of its real part and its imaginary part separately, as separate, full-fledged Wraith Scheme real numbers. The real and imaginary parts each have their own separate exact bits, and thereby is created some confusion about the exactness of the complex number as a whole: How should Wraith Scheme handle complex numbers whose real and imaginary parts have differing exactnesses, and what exactness should be reported for such a complex number considered as a whole?
The obvious solution of reporting a complex number as exact if, and only if, its real and imaginary parts are both exact, does not work. If that solution were implemented, then consider the two complex numbers 1+1.i and 1.+i: In the first, the real part is exact and the imaginary part is inexact, and in the second, the exactnesses are reversed. These two complex numbers would be numerically equal and would have the same exactness, yet would not behave equivalently under standard Scheme procedures: For example, "real-part" would return different values for the two numbers, and so would "imag-part".
To avoid this conundrum, Wraith Scheme will not allow a complex number to have real and imaginary parts with differing exactnesses. In that context, in brief:
(exact? z)
(exact? (real-part z))and
(exact? (imag-part z))also return #t.
(exact? z)returns #f if, and only if, both
(exact? (real-part z))and
(exact? (imag-part z))also return #f.
Exactness -- "string->number" and "number->string":
Let me summarize how Wraith Scheme's implementations of string->number and number->string deal with exactness. I believe that Wraith Scheme handles these matters correctly, but this section of the R5 report is a bit obscure, and does allow implementors some leeway. The following rules tell how the external representation of a number -- what you type, and what Wraith Scheme prints -- corresponds to the exactness of Wraith Scheme's internal representation of that number.
The idea is that numbers input to Wraith Scheme are considered exact unless some feature of the external representation -- typically one or more embedded '#'s or an explicit inexact prefix ("#i") -- indicates otherwise.
There is a complication with numbers that are expressed in base 10. The problem is, that there are additional means of indicating exactness available to external representations of those numbers: Base 10 is the only base in which the external representations of numbers are allowed to have decimal points or exponents. These act as indicators of inexactness, but "weakly", in that their indications may be overridden by explicit exact prefixes.
In a little more detail:
#e1## #e1##. #e1.##e2 #e#xff##
Thus, examples of numbers which both you and Wraith Scheme should consider inexact are:
100. 1e2 1.37e2 -100. -1e2 -1.37e2
Examples of numbers which both you and Wraith Scheme should consider exact are:
#e100. #e1e2 #e1.37e2 #e-100. #e-1e2 #e-1.37e2
Thus, examples of numbers which both you and Wraith Scheme should consider inexact are:
#i100 10# #i-100 -10#
And examples of numbers which both you and Wraith Scheme should consider exact are:
100 -100
Thus, examples of numbers which both you and Wraith Scheme should consider inexact are:
#i#b1110 #i#o16 #i#xe #i#b-1110 #i#o-16 #i#x-e
And examples of numbers which both you and Wraith Scheme should consider exact are:
#b1110 #o16 #xe #b-1110 #o-16 #x-e
1e2 -1e2
The reasoning as to why numbers such as these are not printed is that (1) Wraith Scheme uses the standard Scheme procedure "number->string" to print numbers, and (2) R5 Scheme requires that procedure to print base-10 inexact numbers with a decimal point, except for infinities and nans, and (3) R5 Scheme requires that the presence of an exponent, without an explicit exact prefix, be taken to mean that the number in question is inexact. Yet even though Wraith Scheme will not print these numbers as output, it will recognize them when input, as respectively inexact 100 and inexact -100, in base 10.
Exact prefixes and the like notwithstanding, Wraith Scheme cannot necessarily store a number that is mathematically identical to a given external representation. For example, Wraith Scheme stores #e1.3 as a number that is certainly not 1.3, but that differs from it by a few digits a long way to the right of the decimal point. Furthermore, if you type in a long string of digits, with no decimal point or exponent, Wraith Scheme will interpret what you have typed as an integer and will do the best it can to store it, but if you have typed too many digits, the ones farthest to the right will have no effect on the value stored. Thus if you type
9999999999999999999999999999999Wraith Scheme will store and print out
#e1.e31
In Wraith Scheme, the empty list counts as true in conditional expressions.
In Wraith Scheme, the empty list is not equivalent (eqv?) to #f.
Wraith Scheme does not provide "t" and "nil". (You can easily define them yourself.)
Wraith Scheme provides two specialized "logic constants", "#u" and "#s", for use in logic programming. (See Friedman, Byrd and Kiselyov, 2005). Wraith Scheme does not include any software based on this work; that's copyrighted, but you couldn't even get Wraith Scheme to read these identifiers unless I built them in, because R5 identifiers are not generally allowed to start with '#'. So here they are, for anyone who wishes to use them.
Each of "#u" and "#s" evaluates to itself.
Wraith Scheme provides a specialized non-printing object, "#n", whose printed representation is an empty string and which furthermore will cause Wraith Scheme's top-level read-eval-print loop to omit printing a newline when #n is the result of the "eval" part of the loop. See the discussion here. Note carefully: "#n" represents a non-printing object. "#\n" represents the ASCII character 'n' (lower-case n).
Wraith Scheme has no uninterned symbols; in particular, those returned by "string->symbol" are already interned. Of course, not every symbol is necessarily associated with a value. Wraith Scheme will report an error when it tries to evaluate an unbound symbol.
The boolean procedures that compare characters all take precisely two arguments. Those procedures are:
char=? char-ci=? char<? char-ci<? char>? char-ci>? char<=? char-ci<=? char>=? char-ci>=?
Wraith Scheme uses the ASCII ordering of characters, and does not accept non-ASCII characters for any purpose.
The procedure "integer->char" is capable of producing any ASCII character, even ones that the Wraith Scheme interpreter does not accept as typed input. Wraith Scheme displays some of these characters strangely.
Wraith Scheme uses text names for two additional characters beyond the R5 Scheme standards of #\newline and #\space. The external representations of these characters are #\tab and #\return; they stand for the ASCII characters whose values as decimal integers are respectively 9 and 13. Wraith Scheme's character-handling procedures handle them in a manner analogous to #\space and #\newline. Also see Slashification.
6.3.5:
When procedure "make-string" is called with no arguments, it prompts you to type the intended content of the string in the Wraith Scheme Dialog Panel. Enclosing double-quotes are not necessary. The full list of standard Scheme procedures that use the Dialog Panel in this manner is given in the section on Run-Time Text Input.
The boolean procedures that compare strings all take precisely two arguments. Those procedures are:
string=? string-ci=? string<? string-ci<? string>? string-ci>? string<=? string-ci<=? string>=? string-ci>=?
Wraith Scheme uses the ASCII ordering of characters, and does not accept non-ASCII characters for any purpose.
Wraith Scheme allows the "backslash" character, '\', to serve as a slightly more general "escape" than is required by the R5 report: Section 6.3.5 of that report reads in part
A doublequote can be written inside a string only by escaping it with a backslash (\), as in
"The word \"recursion\" has many meanings."
A backslash can be written inside a string only by escaping it with another backslash. Scheme does not specify the effect of a backslash in a string when it is not followed by a doublequote or backslash.
Wraith Scheme takes advantage of the freedom implicit in the last quoted sentence in the following way:
"abcdefg\ hijklmn"
results in a string which contains an ASCII newline character after the 'g'. On the other hand, an attempt to input
"abcdefg hijklmn"
-- without the '\' -- would result in an error message, in essence complaining that the first line did not have a terminating double-quote.
Also see #\tab and #\return.
Wraith Scheme implements "dynamic-wind" along the lines of the implementation given by Rees (1992). That implementation involves modifying "call-with-current-continuation". The unmodified version of "call-with-current-continuation" is available as an enhancement, "e::original-cwcc".
The Wraith Scheme procedures "e::reset" and "e::exit", which are enhancements described in the section "Top-Level Control", will leave a call of "dynamic-wind" without invoking the "after" procedure that was part of that call. So will the corresponding commands to the Wraith Scheme interpreter, which are performed via buttons, menu items, or their keyboard equivalents.
Wraith Scheme recognizes only the exact integer 5 as a valid value of the "version" argument for "scheme-report-environment" and for "null-environment".
The null environment contains bindings for three symbols that are not defined in the R5 report; namely "c::begin", "c::if" and "c::lambda". These names follow the naming convention for specialized enhancements outlined in the "Enhancements" section herein.
There is a possible ambiguity in the meaning of "interaction environment". The R5 report describes it as "the environment in which the implementation would calculate expressions dynamically typed by the user"; the only circumstance in which a Wraith Scheme user can type expressions for evaluation is when Wraith Scheme is reading at the top-level loop. I therefore made the interaction environment be the same as the top-level loop environment. Thus, e.g., typing at top-level:
(define a 'top-level) ;; ==> a a ;; ==> top-level (let ((a 'local)) a) ;; ==> local
but
(let ((a 'local)) (eval 'a (interaction-environment)))
;; ==> top-level ;; Not "local"
Input and output procedures such as "open-input-file", that take a string argument that names a file, will ask you to type in a file name when called without the string argument. These procedures will use the Wraith Scheme Dialog Panel for that purpose.
For example,
(open-input-file "foo")
opens an input file named "foo" -- or at least tries to -- whereas
(open-input-file)
will ask you to type in a file name. Similarly,
(call-with-input-file "foo" my-procedure)
calls "my-procedure" with the port obtained by opening "foo", whereas
(call-with-input-file my-procedure)
asks you to type in a file name.
The full list of standard Scheme procedures that use the Dialog Panel in this manner is given in the section on Run-Time Text Input.
The R5 report specification of what "load" is supposed to do is not precise: The "load" procedure clearly should read definitions and expressions from a file and evaluate them, but the report does not specify the environment in which that evaluation is to take place. Wraith Scheme performs such evaluations in the interaction environment, which is also the top-level environment; that is, where you type input in the top-level read-eval-print loop.
There are other, system-dependent I/O features. See the "Enhancements" section.
The procedure "input-port?" returns #f when called with an input port that has been closed. The procedure "output-port?" returns #f when called with an output port that has been closed.
Procedures that open a port for output always create a new file as the destination, destroying any previous file of the same name that may already exist.
Each Wraith Scheme process allows a maximum of eight input ports and eight output ports to be open at once. (The picky wording about "each Wraith Scheme process" is because of Wraith Scheme's enhancements for parallel processing: There may be lots of Wraith Scheme processes running at once, and each of them is entitled to its own set of ports.) The port for a transcript file does not count as one of the eight output ports.
6.6.3:
Wraith Scheme "slashifies" the characters "newline", "return", and "tab", in the procedure "write", but not in the procedure "display": That is, "write" prints "newline" as "\n", "return" as "\r", and "tab" as "\t". "Display" prints these characters literally: A "newline" moves the printing to the start of the next line, and so on.
This treatment matches the escaping of those characters within string constants.
6.6.4:
Each Wraith Scheme process allows only one transcript file to be open at a time. If "transcript-on" is called twice without an intervening call to "transcript-off", the second call closes the first file opened.
Wraith Scheme transcripts record everything that appears in the Main Display Panel, including both text entered by the user and text output from Wraith Scheme itself. They also record interactions that use the Wraith Scheme Dialog Panel, showing both the prompt and the user's reply, formatted like this:
[DIALOG PROMPT] Pathname of file for input? (unquoted) [DIALOG ANSWER] /Users/JayFreeman/fooWraith Scheme transcripts records output from Wraith Scheme even when the Interpreter Menu menu item to disable window output has been checked.
7.1.1:
Wraith Scheme no longer supports numbers that contain "embedded sharps": The rules for what a number may look like that are given in section 7.1.1 of the R5 report allow '#' to substitute for digits in certain places. Earlier versions of Wraith Scheme allowed that syntax, but the present version does not. Thus if you had typed
12###
1.2e4The present version emits an error message instead. If you have been using the "embedded sharp" syntax and wish to transform existing input data into something that works the same way, substitute the digit '0' for any embedded sharp, and make all such input data inexact. In doing your substitutions. Be careful not to alter the '#'s in the two-character sequences that indicate exactness or radix.
3iis equivalent to
+3iThat is, they are both valid external representations of the complex number whose real part is zero and whose imaginary part is three. Yet in contrast, note that
iand
+iare not equivalent: The latter is a pure complex number whose imaginary part is one; the former is the symbol "i", which has no default binding in R5 Scheme and so has no a priori connection to complex numbers.
(define anInf (/ 1 0)) ;; ==> aninf (define aNan (- (/ 1 0) (/ 1 0))) ;; ==> anan (make-rectangular 1 aninf) ;; ==> 1+infi (make-rectangular 0 aninf) ;; ==> infi (make-rectangular 1 anan) ;; ==> nan
Also:
#ei ;; ==> +i #ii ;; ==> 1.i #e1e1i ;; ==> 10i #i1e1i ;; ==> 10.i #e1e10 ;; ==> #e1.e10 ;; "Old Macdonald had a farm ..." #xaei ;; ==> 174i ;; What happened to 'o' and 'u'?
Et cetera ad nauseam.
42 / 137(with white space) or to write a complex number as
73 + 88 i(ditto), but Scheme will not recognize these forms as single numbers: The first will be read and parsed as a sequence of three Scheme objects; namely, the integer forty-two, the symbol "/", which is normally bound to the Scheme procedure for division, and the integer one hundred thirty-seven. The second will be read and parsed as four objects; namely, the integer seventy-three, the symbol "+", which is normally bound to the Scheme procedure for addition, the integer eighty-eight, and the symbol "i", which has no default binding. To obtain the intended meanings as single numbers, you must write
42/137and
73+88iwithout any embedded white space. It is of course also true and unremarkable that because of the embedded white space,
123 45 678does not parse the same way as
12345678-- the former is three numbers while the latter is one -- but this case is very obvious and familiar. The syntactically similar situations involving fractions and complex numbers with embedded white space are less commonly considered.
1+2/3iis to be read as
1+(2/3)iand not as
1+2/(3i)This quirk is particularly vexing when the denominators of the fractions are large, as in
1+137/123456789iwhich must be read as
1+(137/123456789)ieven though that is not the way many people would interpret it at a glance.
In the section-by-section discussions above, of how Wraith Scheme differs from the R5 standard, I have listed the optional R5 features that Wraith Scheme lacks. These features are "optional" in that the R5 report mentions them, perhaps with such language as "some implementations support ...". Here they are once again, all in one place, in summary:
Most of the extra features added in Wraith Scheme are discussed in the section Enhancements, which immediately follows, but they are distinguished from regular R5 features by syntax -- they all start with either "e::" or "c::", as explained in that section. One feature does not: I added
(call/cc <procedure that takes one argument>)as a somewhat traditional synonym for R5's "call-with-current-continuation". The purpose of this tradition is evidently to allow not typing the latter, longer name, so in order to keep the alternate name short, I did not use the "e::" or "c::" prefix.
This section describes Wraith Scheme's non-standard features, procedures and syntax. Many are rather conventional: Most implementations of Scheme will have them in some form, but they are sufficiently dependent on the particular computer and operating system in use that the R5 report cannot specify them. Others deal with matters of controversy in the Scheme community, and have been much discussed in the context of Scheme revisions beyond R5. I have provided what seems best to me.
There are a moderate number of enhancements that are specific to the look and feel of the Apple Macintosh, or that allow you to access special features of the Macintosh itself. And finally, there are some enhancements that allow you to inspect or modify parts of Wraith Scheme at a rather low level. Some of these may be useful in debugging programs, or in satisfying your curiosity about what's going on. Others are there because I needed them for some purpose related to developing Wraith Scheme, or for some personal project using Wraith Scheme.
Most of these enhancements are identified by naming conventions: Wraith Scheme uses symbols which begin with the characters "e::" for enhancements that may well be of broad interest to users, and "c::" for more specialized enhancements that will probably be less generally useful.
Thus in essence, I have established two special namespaces for Wraith Scheme, one comprising all identifiers that begin with "e::" and one comprising all identifiers that begin with "c::". I will probably add more things to both of these namespaces in future releases of Wraith Scheme, so you should avoid defining any additional identifiers from either of these namespaces in your own code.
By and large, enhancements whose names begin with "e::" are reasonably well-documented and handle errors reasonably. They should be no risker to use -- with "risk" in the sense of unexpected crashes and mysterious behaviors -- than standard Scheme procedures, special forms, and macros. Furthermore, these enhancements are likely to continue to exist in the same form in future releases of Wraith Scheme, or at the very least, I will make a big to-do in documentation if there are changes.
Enhancements whose names begin with "c::" will be less-well documented, riskier, and more likely to change in future releases. Most of the "c::" enhancements are provided for my own use in developing Wraith Scheme, or are auxiliaries used by standard Scheme procedures or by "e::" enhancements. I have left them in the release and documented some of them.
You might remember the distinction this way:
e:: for enhancement, c:: for caution
A cynic might have said:
e:: for enhancement, c:: for catastrophe
Note that all of Wraith Scheme's R5 procedures, R5 special forms, R5 macros and "e::" enhancements are described in detail, with examples and discussion, in the Wraith Scheme Dictionary, which accompanies Wraith Scheme and may be reached via the Wraith Scheme Help Menu. Some, but by no means all, of the "c::" enhancements are also documented there.
The term "applicative programming" means different things to different people. As an enhancement, Wraith Scheme has means to make it easy to do a pretty good job at one of the kinds of programming that is commonly called "applicative". Specifically, there is means provided to do programming that is for the most part referentially transparent.
Referential transparency encapsulates the condition that every time you do the same thing, you get the same result. In the context of programming, the idea is that every time you call the same procedure or special form, with the same arguments, you should get the same answer, and furthermore, the procedure should have no observable side effects.
For example, the arithmetic procedure "+" is referentially transparent: Every time you call
(+ 2 2)
you can reasonably expect to get back the same answer -- 4. On the other hand, consider the following procedure, "foo":
(define (foo n)
(let ((return-value a))
(set! a n)
return-value))
Procedure "foo" is not referentially transparent, because it depends on the initial value of "a" (and I have assumed that "a" will be defined before "foo" is executed). For example, suppose that a starts out as 3, and that you call
(foo 42)
twice in a row. The value returned from the first call will be 3, but the value returned from the second call will be a different value, 42.
It is easy to see that the problem with "foo" stems from the use of "set!": It changes state, and that is the difficulty. After the "set!", there is a value in Scheme main memory, that is not garbage, that is different from what it was before. That is an observable side-effect: Any procedure that uses that value to determine its own returned value will not be referentially transparent.
Before getting on with the details of what that means and how it works, I must point out that there are a few problems with this simple notion of referential transparency:
With all that said, the actual details of the enhancement are simple. There is just one new procedure:
(e::perform-applicative <thunk>)
This procedure performs <thunk> with Wraith Scheme's ability to change state turned off, and returns whatever <thunk> did. Specifically, within the code represented by <thunk>, any attempt to use any of the following procedures and special forms will be interpreted as an error:
set! set-car! set-cdr! string-fill! string-set! vector-fill! vector-set! e::clear-permanent! e::disable-big-red-button! e::disable-pushbutton! e::enable-big-red-button! e::enable-pushbutton! e::load-world! e::set-current-directory! e::set-input-port! e::set-level-indicator! e::set-list-print-depth! e::set-list-print-length! e::set-permanent! e::set-tag! e::set-vector-print-depth! e::set-vector-print-length!
If <thunk> should create a continuation which is subsequently returned to (as by "call-with-current-continuation"), then that continuation will inherit the applicative restrictions.
If <thunk> should request another kitten to do something via "e::tell-kitten", then whatever the other kitten is asked to do will also be subject to the applicative restrictions.
If a Wraith Scheme interrupt occurs while the applicative restrictions are in force, the applicative restrictions will be turned off for the duration of the interrupt (unless the interrupt handler turns them back on).
By way of illustration:
(e::perform-applicative (lambda () (+ 2 2))) ;; ==> 4
but
(define a 3) (e::perform-applicative (lambda () (set! a 42)))
produces the error message:
In built-in routine "set!":
Problem: Attempt to use a non-applicative procedure or special form during applicative programming.
Last lambda called (which may have returned) was recently named:
thunk
Recent names of non-tail-recursive stacked lambda expressions:
e::perform-applicative
(Resetting)
Top-level loop ...
Wraith Scheme comes with a simple class system for creating objects with encapsulated data and procedures. That system is generally similar in intent and in operation to the class systems in C++, Java, and other programming languages: It facilitates object-oriented programming in a straightforward way. Notwithstanding, the Wraith Scheme class system is somewhat more crudely implemented than either of those other class systems.
It is beyond the scope of this document to describe what class mechanisms are for, or what object-oriented programming is all about, or how to think in terms of object-oriented design. There are books on those subjects -- hundreds of them. If you are not familiar with these concepts, this section of the Wraith Scheme help file won't help you much: You should probably forget about the Wraith Scheme class system until you have learned more about classes in general. I will proceed on the assumption that you have some familiarity with other class systems and their uses.
The procedure which provides access to the Wraith Scheme class system is
(e::make-simple-class <symbol which the class takes to be its name> <list of classes from which the new class inherits> <list of lists like (<symbol> <object>) for class variables> <list of lists like (<symbol> <object>) for instance variables> )
The first list of lists provides the names of the class variables and their default bindings. The second list of lists provides the names of the class's instance variables and their default bindings. The procedure returns a class in the Wraith Scheme class system.
Many examples follow shortly.
As long as all of the names therein are distinct, the system will do just fine; that is, if there is only one instance variable named "frob" among all those names, Wraith Scheme doesn't need to know which class it was inherited from in order to set it, get it, or apply it as a method.
Wraith Scheme will warn you if a flattened namespace contains any duplicated names, but it will not prevent you from creating classes with such duplications. Just be sure you know what you are doing, if you do.
For example, you could start the names of variables in each class with the name of that class. Thus in a class named "foo", you might have variables "foo-x", "foo-y", and so on. That will work as long as a class has "foo" in at most one place in its inheritance.
You may of course create any specialized methods you wish to run after you have created an instance of a class, but you will have to run them yourself. One way to do that is to create a specialized procedure that creates the class instance, then runs your method, and then returns the modified class instance.
A Simple Class Example -- Right Triangles:
Let's go through a simple example. Suppose we want to have a class of right triangles. It takes two sides to define one -- say, side-1 and side-2. Here is the Wraith Scheme code to create a minimal version of such a class. (You can cut and paste this code into Wraith Scheme to try it out.)
(define right-triangle
(e::make-simple-class
'right-triangle
'()
'()
'((side-1 0) (side-2 0))
)
)
In that code, "e::make-simple-class" is the procedure to make a class, whose full syntax I have not yet described. The first argument, "'right-triangle", -- note the quote -- is what the class will understand its name to be. It will be used, for example, in constructing error messages, things like "While trying to create a class of type 'right-triangle', the world suddenly came to an end. Sorry about that." Note that in this example, that argument happens to be the same as the first argument to "define", here:
(define right-triangle ;; ... )
There is no requirement that those two symbols be the same, but it is good practice to make them so.
The second argument, which is '(), would be a list of classes that "right-triangle" inherited from, except there aren't any.
The third argument, which is also '(), would be a list of class variable names and default values, except that there aren't any yet. (Class variables are shared by all instances of the given class.)
The fourth argument is list of instance-variable names and default values that will be used by each instance of the given class. Again, note the quote. I hope the syntax is obvious, and you do have to provide a default value for each instance variable. There are other ways you could have built up this list. For example, instead of writing
'((side-1 0) (side-2 0)),
you might alternatively have written
(list (list 'side-1 0) (list 'side-2 0))
Now let's make a triangle:
(define first-triangle (right-triangle '()))
The argument to "right-triangle" is a list of overrides to the default instance-variable values, except there aren't any.
We now have created a right triangle whose sides are both zero. You get the instance-variable values like this. Note the quotes.
(first-triangle 'side-1) ;; ==> 0 (first-triangle 'side-2) ;; ==> 0
A triangle with zero-length sides is not very interesting. Let's fix that. Watch those quotes.
(first-triangle 'set! 'side-1 3) ;; ==> #t (first-triangle 'set! 'side-2 4) ;; ==> #t (first-triangle 'side-1) ;; ==> 3 (first-triangle 'side-2) ;; ==> 4
We could have made a triangle with non-zero side lengths by passing in a list of initializers when we made it:
(define second-triangle (right-triangle '((side-1 5)(side-2 12)))) (second-triangle 'side-1) ;; ==> 5 (second-triangle 'side-2) ;; ==> 12
One thing we might want to know about a right triangle is the length of its hypotenuse. Let us redefine the right-triangle class to include a class method that calculates the hypotenuse. For clarity, I will define the method first, then reconstruct the class and the instances.
(define (hypotenuse-code this)
(let
((a (this 'side-1))
(b (this 'side-2))
)
(sqrt (+ (* a a) (* b b)))))
What's this about "this"? Wait and see ...
In the new class definition immediately below, note the use of back-quote and comma in providing the binding for the class variable "hypotenuse". I could also have just used "list" explicitly, as in (list (list 'hypotenuse hypotenuse-code)).
(define right-triangle
(e::make-simple-class
'right-triangle
'()
`((hypotenuse ,hypotenuse-code))
'((side-1 0) (side-2 0))
)
)
(define first-triangle (right-triangle '()))
(first-triangle 'set! 'side-1 3) ;; ==> #t
(first-triangle 'set! 'side-2 4) ;; ==> #t
(define second-triangle (right-triangle '((side-1 5) (side-2 12))))
(first-triangle 'method 'hypotenuse) ;; ==> 5
(second-triangle 'method 'hypotenuse) ;; ==> 13
The point about "this" is that when you send a "method" message to a class instance, the method you name -- in this case "hypotenuse" -- is called with the class instance itself prepended to any other method arguments you may have provided. The effect in the two cases just given is as if "hypotenuse-code" were called as follows:
(hypotenuse-code first-triangle) (hypotenuse-code second-triangle)
Note that you do not have to use the name "this" for the corresponding name in the argument list of "hypotenuse-code". You can call that argument anything you like. Names like "this" or "self" are conventional, though.
Methods may have other arguments than "this". For example, you might have wanted a method for right triangles that returned a boolean value, #t or #f, depending on whether the hypotenuse of the triangle was greater than a passed value. The code for that method might be written like this:
(define (hypotenuse-greater-than-code this x) (> (this 'method 'hypotenuse) x))
Then you could have yet another redefinition of the right triangle class:
(define right-triangle-again
(e::make-simple-class
'right-triangle-again
'()
`((hypotenuse ,hypotenuse-code)
(hypotenuse> ,hypotenuse-greater-than-code)
)
'((side-1 0) (side-2 0))
)
)
(define first-triangle-again (right-triangle-again '()))
(first-triangle-again 'set! 'side-1 3) ;; ==> #t
(first-triangle-again 'set! 'side-2 4) ;; ==> #t
(define second-triangle-again (right-triangle-again '((side-1 5) (side-2 12))))
(first-triangle-again 'method 'hypotenuse) ;; ==> 5
(second-triangle-again 'method 'hypotenuse) ;; ==> 13
(first-triangle-again 'method 'hypotenuse> 8) ;; ==> #f
(second-triangle-again 'method 'hypotenuse> 8) ;; ==> #t
In the last two calls, the effect is as if "hypotenuse-greater-than-code" were called as follows:
(hypotenuse-greater-than-code first-triangle-again 8) (hypotenuse-greater-than-code second-triangle-again 8)
Let's see about inheritance. First let's define a simple class for colored objects:
(define colored-object
(e::make-simple-class
'colored-object
'()
'()
'((color chartreuse))
)
)
(define test-colored-object
(colored-object '((color vermilion))))
(test-colored-object 'color) ;; ==> vermilion
Now let's define a class for a colored right triangle
(define colored-right-triangle
(e::make-simple-class
'colored-right-triangle
(list right-triangle colored-object)
'()
'()
)
)
The new class inherits from "right-triangle" and from "colored-object", and does not add any more instance variables of its own. Let's make and test some colored triangles.
(define first-triangle (colored-right-triangle '()))
(first-triangle 'set! 'side-1 3) ;; ==> 0
(first-triangle 'set! 'side-2 4) ;; ==> 0
(first-triangle 'set! 'color 'burgundy)
(define second-triangle
(colored-right-triangle
'((side-1 5) (side-2 12) (color puce))))
(first-triangle 'method 'hypotenuse) ;; ==> 5
(first-triangle 'color) ;; ==> burgundy
(second-triangle 'method 'hypotenuse) ;; ==> 13
(second-triangle 'color) ;; ==> puce
If you would like to investigate some of the inner details of a class, there are a few extra variable names that all classes will have, and all class instances will respond to.
(first-triangle 'class-name) ;; ==> colored-right-triangle (first-triangle 'class-variable-names) ;; ==> (hypotenuse) (first-triangle 'all-variable-names) ;; ==> (side-1 side-2 color all-variable-names inheritance class-variable-names class-name this hypotenuse) (first-triangle 'inheritance) ;; ==> (colored-right-triangle (right-triangle) (colored-object))
That last says that "colored-right triangle" inherits both from "right-triangle" and all its ancestors (except there aren't any), and from "colored-object" and all its ancestors (except there aren't any of those, either).
(first-triangle 'this) ;; ==> #<Interpreted lambda expression, possibly named ">*<">
It would probably be a bad idea to "set!" "this". Don't say I didn't warn you.
Inheritance -- A Familiar Example:
Here is an example of multiple inheritance based on the genetic inheritance of a child from the two previous generations.
(define maternal-grandmother (e::make-simple-class 'maternal-grandmother '() '() '())) (define maternal-grandfather (e::make-simple-class 'maternal-grandfather '() '() '())) (define paternal-grandmother (e::make-simple-class 'paternal-grandmother '() '() '())) (define paternal-grandfather (e::make-simple-class 'paternal-grandfather '() '() '())) (define mother (e::make-simple-class 'mother `(,maternal-grandmother ,maternal-grandfather) '() '())) (define father (e::make-simple-class 'father `(,paternal-grandmother ,paternal-grandfather) '() '())) (define child (e::make-simple-class 'child `(,mother ,father) '() '())) (define a-child (child '())) (a-child 'inheritance) ;; ==> (child (mother (maternal-grandmother) (maternal-grandfather)) (father (paternal-grandmother) (paternal-grandfather))) ;; ;; ... or, reformatted for clarity ... ;; ;; ==> (child ;; (mother ;; (maternal-grandmother) ;; (maternal-grandfather) ;; ) ;; (father ;; (paternal-grandmother) ;; (paternal-grandfather) ;; ) ;; )
Class variables are shared by all instances of the given class. They are commonly used to hold methods associated with the class, but there are other possible uses. Perhaps you wish to implement a counter of some sort that is shared by all instances of a class, or maybe an inter-instance signaling mechanism. Here is an example that shows the use of a class variable as a counter.
(define (increment-counter-code this)
(this 'set! 'counter (+ (this 'counter) 1)))
(define class-variable-example
(e::make-simple-class
'class-variable-example
'()
`((counter 0)
(increment-counter ,increment-counter-code)
)
'()
)
)
(define instance-1 (class-variable-example '()))
(define instance-2 (class-variable-example '()))
(instance-1 'counter) ;; ==> 0
(instance-2 'counter) ;; ==> 0
(instance-1 'method 'increment-counter)
(instance-1 'counter) ;; ==> 1
(instance-2 'counter) ;; ==> 1
(instance-2 'method 'increment-counter)
(instance-1 'counter) ;; ==> 2
(instance-2 'counter) ;; ==> 2
As you see, the new value of the class variable is seen by both instances, no matter which instance has changed it.
Class variable values are only shared by instances of a particular class. There is no sharing of class variables between different classes, even if one inherits a class variable from another, or if both inherit the same class variable from a common ancestor.
For example, suppose that class "root" has a class variable named "root-var". Suppose that classes "branch-one" and "branch-two" both inherit from "root". Then all instances of "branch-one" will share one value of "root-var", all instances of "branch-two" will share another, independent value of "root-var", and all instances of "root" itself will share yet a third independent value of "root-var".
Methods and Procedures as Variables:
It is important to note that you may, if you wish, store a procedure which is not intended to be used as a method, as the value of a class variable or an instance variable. Recall that when you invoke a class instance with "'method", the value of the variable you name is treated as a procedure, and that the actual class instance in question is prepended to whatever other arguments you supply, for you to use as the value of "this" or of some other convenient variable name.
Alternatively, suppose we had a class whose sole purpose was to store functions to do trigonometric or geometric calculations. Such a class might very well store a hypotenuse procedure, which we could get out and apply to any two numbers that we considered to be the sides of a right triangle. That is not as contrived an example as it seems: Perhaps we are doing calculations in Euclidean and non-Euclidean geometries, and we want to see what the properties of shapes are in several such instances of geometries. Anyway, let's define a simple class:
(define (hypotenuse-procedure a b)
(sqrt (+ (* a a) (* b b))))
(define geometry
(e::make-simple-class
'geometry
'()
`((hypotenuse ,hypotenuse-procedure))
'()
)
)
(define my-geometry (geometry '()))
To use the hypotenuse procedure, we just pull out the value of the variable "'hypotenuse" and use it as a procedure.
((my-geometry 'hypotenuse) 8 15) ;; ==> 17
I hope you see the difference. The symbol "'method" appeared nowhere in the use of the "geometry" class. We are in effect just storing ordinary procedures, which do not need a "this" variable, as the values of variables of the class.
The Wraith Scheme class system provides means to lock both class and instance variables for critical-section access. You might need to lock an instance variable if a particular instance of a class were being used by two or more kittens. You might need to lock a class variable if different instances of the same class were being used by different kittens. The mechanism to block access, and to change a value while you have it locked, is the same in both cases. Here is an example, in which "foo" is an instance of a class, which has "bar" as a variable -- either a class variable or an instance variable.
(define foo (e::make-simple-class 'foo '() '((bar 1)) '())) ;; ==> foo (define my-foo (foo '())) ;; ==> my-foo (my-foo 'bar) ;; ==> 1So far so good, but we do not want to evaluate what we get next.
(define block-list (my-foo 'block-binding 'bar)) ;; ==> block-list -- don't print!Block-list returns a list, the first item of which is the value of bar just before the lock was established, and the second of which is an object that is suitable only for use with procedures for critical-section access, like "c::release-block" (which see), or like 'set-blocked-binding, as shown a few lines down. If you try to display or otherwise access the cadr of block-list, or if any other kitten tries to access the value of "bar", the Wraith Scheme process involved will stall until some other process has released the block.
The operation of 'block-binding on a variable used in a class is entirely analogous to the operation of "e::block-symbol-binding" on a non-class variable.
The first item in the blocked list is the value of the variable just before the lock was established.
(car block-list) ;; ==> 1
There are a few useful things you can do with a blocked binding. You may set its value of by using the blocked binding in the following way:
(my-foo 'set-blocked-binding! (cadr block-list) 42) ;; ==> #tFor an analogous Wraith Scheme procedure, see "e::set-blocked-binding!".
When you are all done with the block, you may release it by using the Wraith Scheme procedure "c::release-block".
(c::release-block (cadr block-list)) ;; ==> #t (my-foo 'bar) ;; ==> 42You could equally well put code like this inside a class procedure, using "this" instead of "my-foo".
;; ... (let ((block-list (this 'block-binding 'bar))) (display (car block-list)) (newline) (this 'set-blocked-binding! (cadr block-list) 42) (c::release-block (cadr block-list)) (display (this 'bar)) (newline) ) ;; ...
(e::make-simple-class <symbol which the class takes to be its name> <list of classes from which the new class inherits> <list of lists like (<symbol> <object>) for class variables> <list of lists like (<symbol> <object>) for instance variables> )
For example, to create a class with one instance variable, "a", and a class variable "add-to-a", which will be a method that will add a number to "a":
(define (add-to-a-code this n) (+ (this 'a) n))
(define foo-class
(e::make-simple-class
'foo
'()
`((add-to-a ,add-to-a-code))
'((a 0))
)
)
(define my-foo (foo-class '())) (define my-foo (foo-class '((a 42))))
class-name ;; Symbol naming the class.
class-variable-names ;; List of symbols which name
;; the class variables.
inheritance ;; A tree, in list form, showing
;; the (multiple) inheritance of
;; the given class.
all-variable-names ;; List of symbols which name
;; all the variables of the given
;; instance of the class -- both
;; class and instance variables.
this ;; The instance of the class.
(my-foo 'a) ;; Returns my-foo's value of a. (my-foo 'set! 'a 3) ;; Sets my-foo's value of a to 3. (my-foo 'method 'add-to-a 42) ;; Adds 42 to my-foo's value of a. (my-foo 'block-binding 'a) ;; Blocks the binding of my-foo's a. (my-foo 'set-blocked-binding! (cadr <something obtained from 'block-binding>) 137 ) ;; Sets the blocked binding to 137
(c::release-block (cadr <something obtained from 'block-binding>))
Wraith Scheme contains a simple compiler: What it produces is not native code for the Macintosh processor, but merely a somewhat more optimized form of Scheme, which the interpreter can evaluate more quickly.
Wraith Scheme has an internal "compile defines" flag that causes each "define" automatically to compile the quantity being defined, provided that "define" is used with the syntax
(define (<name> <argument> ...) ... )
that is, with parentheses around the function name and argument list.
That flag is turned on and off by checking and unchecking the "compile defines" item of the interpreter menu, or by using the procedures described in the Enhancements section under State Flags. With the flag on,
(define (inc x) (+ x 1))
will create a compiled procedure called "inc", that adds one to its argument.
The idea of compilation is to do as much of the work of a program as possible just once, at compile-time, instead of many times, every time the program is run. Thus the compiler ...
Precalculates the positions within the environment of variables (including the arguments) referenced by compiled procedures,
Inserts the actual values of variables that are "permanent", into the bodies of compiled procedures.
Code that has had these things done runs much faster than code that has not.
Even if the "compile defines" menu item is not checked, the compiler will expand macros in procedures that are "define"d using the syntax
(define (<name> <argument ...>) ... )
If the "compile defines" menu item is not checked, there is still a way to compile things, using the procedure "e::compile-form":
(e::compile-form <form>)
in which <form> evaluates to what you want to compile. "<Form>" will typically be either a lambda expression or a symbol to which a lambda expression is bound. You will probably wish to bind the value returned by "e::compile-form" to a symbol, for subsequent use. For example, you might first enter
(define inc (lambda ( x) (+ x 1)))
followed by
(define inc (e::compile-form inc))
The result would be a compiled procedure called "inc", that adds one to its argument.
The compiler attempts to do something sensible with every <form>, but compilation has no effect on <form>s which do not evaluate to lambda expressions: Thus for example
(e::compile-form '(1 2 3)) ;; ==> (1 2 3).
If you define a lambda expression with "compile defines" flag off, then turn it on, you can compile the expression easily, as shown here:
With "compile defines" off:
(define foo (lambda ...)).
Then, after turning "compile defines" on:
(define foo (e::compile-form foo))
The compiler includes some other procedures of interest:
(e::define-no-compile <symbol> <form>) (e::define-no-compile (<symbol> ... ) <form> ... )
"e::define-no-compile" acts as "define" does when the "compile defines" flag is unchecked: That is, even if "compile defines" is checked, and even if quantity being defined evaluates to a lambda expression, nevertheless "e::define-no-compile" will merely bind the evaluated quantity to the <symbol>, without compiling it. Use "e::define-no-compile" to make sure something never gets compiled.
"e::define-no-compile" recursively searches its second argument for macro "calls", and expands any that it finds, before binding the result to the <symbol>.
Effective use of the compiler requires understanding how it uses the "permanence" mechanism. To make a symbol permanent is to make a promise to the compiler, that whatever value is associated with the symbol at compile-time will continue to be associated with it at run-time. Thus the compiler can substitute the value for the symbol once and for all in compiled code, and save the time required to look up the symbol time after time, at run-time. The down side of permanence is that if you ever decide to make a permanent symbol un-permanent, and change its value, you will have to recompile all the procedures that use it, that were compiled while it had the first permanent value. Otherwise, those procedures will continue to use the old value.
The typical symbols you will probably wish to make permanent are the names of procedures, and there is a special procedure to help a bunch of compiled, permanent procedures all know that they are all permanent. That function is "e::substitute-new-permanent-symbols"; you use it on a procedure that has already been compiled, to let that procedure know about symbols that it contains, that have been made permanent after it was compiled:
(e::substitute-new-permanent-symbols <form>)
Note that you do not have to bind the result of "e::substitute-new-permanent-symbols" to anything; that procedure modifies its argument: It looks through the function body for symbols that are permanent, and replaces those symbols with their actual values.
Here is some boiler-plate for how to use the "permanence" mechanism effectively in compiled code. Suppose that the "compile defines" menu item is checked, and that you wish to compile three functions, "foo", "bar" and "baz", that call each other, or that call themselves recursively, or both. The idea is to define them all first, then make them all permanent, then apply "e::substitute-new-permanent-symbols" to all of them. You do all this with the "compile defines" flag set:
(define my-function-names '(foo bar baz)) (define (foo ...) ...) (define (bar ...) ...) (define (baz ...) ...) (map e::set-permanent! my-function-names) (map e::substitute-new-permanent-symbols my-function-names)
The debugging mechanism provided with Wraith Scheme is very incomplete, though there is a hook for making it better. Wraith Scheme's mechanism for handling recoverable errors -- the kind that eventually return control to top level --knows to look for a symbol called "e::debug". If that symbol is bound to a procedure, the error-handling message will call it with a single argument. Thus you may create a debugger merely by defining "e::debug", like this:
(define e::debug (lambda (x) ...))Wraith Scheme will then call "e::debug" as part of its error handling, after the error message has been printed, instead of returning control to the top-level environment.
The argument to "e::debug" will be a non-empty list of all the environments in the lexical scope of the place where the error happened.
The last three environments of that list make up the top-level environment, which is also the interaction environment specified in the R5 report: Among those three members of the environment list, the first will be a vector, each of whose elements is a list of symbols. That vector is used as a hash table. The symbols it contains include those naming all of Wraith Scheme's enhancements to Scheme, plus all top-level symbols that you yourself have defined.
The second of those last three environments is a list that contains symbols defined in the R5 report that are not reserved words of Scheme. It plus the third environment comprise the Scheme report environment as defined in the R5 report.
The third of the last three environments is a list containing the symbols required by null environment, as defined in the R5 report. Those symbols are in essence the reserved words of the Scheme programming language. Wraith Scheme also puts a few other low-level symbols in that environment; they name macros and special forms that the reserved words need in order to function properly.
If the list of environments that is passed to "e::debug" has more than just three members, its first member will be a list of the symbols bound in the lexical scope most local to the error, its second will be a list of the symbols bound in the next lexical scope outward, and so on till the top level. Only one environment -- the first of the last three -- will be a vector; all the others will be lists.
You may have your "e::debug" do whatever you like with this information. You might display the symbols. It will be hard to obtain their values, because the environment list passed to "e::debug" as an argument is not the one Wraith Scheme searches automatically from within "e::debug", when looking for variable bindings. What's more, the environment list is not a very interesting data structure for debugging. Much more useful would be access to Wraith Scheme's run-time stack (which is different from the central processor's "machine stack"). You can always show the contents of this stack, whether from the debugger or not, by calling the procedure "e::show-stack", but there is presently no reasonable way to learn what procedures are associated with specific items on the stack, or to investigate any particular stacked item in more detail.
Your "e::debug" probably ought to terminate with a call to "e::reset", so that Wraith Scheme will return to top-level for further input after "e::debug" has run.
Be careful that "e::debug" is correct code. It is difficult to recover from errors in the debugger. Recursive errors are particularly nasty: The handling of an error in the debugger invokes another copy of the faulty debugger, which causes another error, and so on.
In addition to whatever the debugger may do, Wraith Scheme handles non-fatal errors simply: It prints out some information about the error and what caused it, before invoking any debugger that may be present. If no debugger is present, Wraith Scheme then returns control to the top-level loop. Different things might happen when a debugger is loaded -- depending on what the debugger is supposed to do.
The printed information will include the name of the last lambda expression entered before the error was encountered, whether or not that lambda expression had returned. It will also include the names of all lambda expressions whose activation records are stacked in Wraith Scheme's internal stack; however, this list will not include the names of lambda expressions that were departed from by a tail-recursive call: Their activation records will by then no longer be stacked.
If you are wondering what I mean by the "name" of a lambda expression, wait for a few paragraphs.
By the way, fatal errors are handled differently, depending on what they are and when they occur: Usually, Wraith Scheme will print out some kind of message and then exit. Any debugger present will not be called.
If the you ever see an with a message like
"Implementation error ..."
or
"Implementation: ..."
then I would very much appreciate a bug report with as many details as you can provide. (In particular, include the entire message.) Such messages indicate that I have inadequately guarded against some particular problem: It's my fault; I will be eager to do better.
Bug reports may be sent to Jay_Reynolds_Freeman@mac.com.
The internal representation of a Wraith Scheme lambda expression has a place where Wraith Scheme can record an identifier, which I will somewhat incorrectly refer to as the lambda expression's name. This information can be of great use in a stack trace, for error reporting or debugging. That isn't quite as simple as storing the identifier to which the lambda expression is bound, because a lambda expression may be bound to more than one identifier, as in
(define (dessert-topping) (lambda () ...) ;; It's a dessert topping! (define floor-wax dessert-topping) ;; No! It's a floor wax!
Or a lambda may have no name at all, as in
((lambda (n) (+ n 1)) 3)
What Wraith Scheme does is initialize each lambda expression's "internal" name to (). If a lambda is subsequently bound or assigned to a symbol, Wraith Scheme records that symbol within the lambda expression, as its name. Thereafter, if that lambda expression should subsequently be rebound or reassigned by "define", by "set!", by "e::define-no-compile", Wraith Scheme overwrites the old internal name with the new one. Those are the only ways to cause an internal name to be overwritten: Wraith Scheme will not give a new internal name to a lambda which already has one, when that lambda is rebound or reassigned by any other means.
In particular,Wraith Scheme will not set the internal name of a lambda expression to one of the top-level loop variables: I personally find that way too confusing when I am staring at debugger output.
Thus a lambda expression which has been named at top-level will not be renamed if it gets passed to a procedure as a parameter, or if it gets rebound locally by "let" or some similar mechanism. On the other hand, lambda expressions which do not have top-level names will be named at first opportunity, even if only by being bound to a local variable or to a formal parameter.
You might say that lambda expressions want names so badly that they will grab one at the first opportunity, and will give it up only when forced to do so.
I hope these conventions will correspond reasonably to your notions of what a lambda expression ought to think its name is, and that they will help with debugging in any case.
In case it is not yet clear, this business of storing a lambda expression's name inside the lambda expression is an addition to, not a substitute for or alteration of, the normal Scheme operations of binding and assignment: It is merely a debugging aid. If you didn't know about the "internal" names (and if you never made any mistakes that caused a stack trace to be printed), you'd never notice they were there. What's more, you don't need to know about them to use Wraith Scheme.
Wraith Scheme has a data type, "float matrix", for matrices composed of IEEE 64-bit floating-point numbers, and has procedures to operate on those matrices. Float matrices are non-atomic, which means that the data representing them is stored in Scheme main memory, but the details of that storage are different than for other non-atomic data types, such as lists, strings and vectors. Thus special procedures are required to deal with them.
The elements of float matrices are stored as IEEE 64-bit floating-point numbers, just as are Wraith Scheme's regular flonums, but the procedures to manipulate them do not keep track of exactness. Thus Wraith Scheme will present any data elements retrieved from a float matrix as inexact -- with the "exact bit" not set.
Float matrices may be initialized, or have their data elements otherwise set, using any kind of real number known to Wraith Scheme, including fixnums, flonums, and long ratnums, but all such numbers will be converted to IEEE 64-bit floating-point numbers before being stored into float matrices. Such conversions may result in loss of precision, such as when loading an integer outside the range that can be expressed precisely as IEEE 64-bit floating-point numbers, or when loading a number in fraction form, such as 1/3.
The row and column numbers of Wraith Scheme float matrices are zero-based. Thus a 3x4 float matrix has rows 0, 1, and 2, and has columns 0, 1, 2, and 3.
The data elements of float matrices are stored in Scheme main memory in row-major order; that is, the linear order in memory is first row, second row, third row, and so on. When working with large matrices, operations may be much faster if elements are accessed in row-major order.
Float matrices can be very large -- they are limited in size only by the amount of Scheme main memory available. The number of bytes used by a float matrix with M rows and N columns is 8 * M * N for the data, plus a few tens of bytes more for storing M and N, and for other data describing the byte block.
Procedures involving very large float matrices can take a long time to execute, particularly on Macintoshes with small amounts of physical memory. Operations that are particularly slow include matrix multiplication, matrix inversion, and calculating the determinant of a matrix. These operations all have execution times that are proportional to the cube of the matrix side, hence the times increase rapidly as matrix size increases.
If you need to interrupt such an operation by telling Wraith Scheme to reset or quit, it may take a while before Wraith Scheme responds. In extreme cases, it may be necessary to quit Wraith Scheme from the Macintosh Finder.
The best way to become familiar with the speed and interrupt-response time of Wraith Scheme float matrix procedures on your Macintosh is to experiment. Try things out with small matrices first, and increase matrix size gradually.
There are many procedures dealing with float matrices:
Creating and initializing float matrices:
(e::make-float-matrix <positive integer> <positive integer> [<real>])
(e::make-float-matrix-from-vector <positive integer> <positive integer> <vector>)
(e::make-float-matrix-identity <positive integer>)
(e::float-matrix-fill-from-vector! <float-matrix> <vector>)
(e::float-matrix-fill-column-from-vector! <float-matrix> <nonnegative integer> <vector>)
(e::float-matrix-fill-row-from-vector! <float-matrix> <nonnegative integer> <vector>)
(c::float-matrix-generate-random <positive integer> <positive integer>)
Operations involving float matrix content or description:
(e::float-matrix-copy <float matrix>)
(e::float-matrix-dump-to-vector <float matrix>)
(e::float-matrix-dump-column-to-vector <float matrix> <nonnegative integer>)
(e::float-matrix-dump-row-to-vector <float matrix> <nonnegative integer>)
(e::float-matrix-get-columns <float matrix>)
(e::float-matrix-get-element <float matrix> <nonnegative integer row> <nonnegative integer column>)
(e::float-matrix-get-rows <float matrix>)
(e::float-matrix-set-element! <float matrix> <nonnegative integer row> <nonnegative integer column> <real>)
Predicates and comparisons:
(e::float-matrix? <object>)
(e::float-matrix-antisymmetric? <object>)
(e::float-matrix-diagonal? <object>)
(e::float-matrix-identity? <object>)
(e::float-matrix-square? <object>)
(e::float-matrix-symmetric? <object>)
(e::float-matrix-= <float matrix> <float matrix>)
(c::float-matrix-check-identity <square float matrix>)
This procedure is useful for testing other procedures.
(c::float-matrix-check-zero <square float matrix>)
This procedure is useful for testing other procedures.
Matrix operations:
(e::float-matrix-add <float matrix> <float matrix>)
(e::float-matrix-determinant <float matrix>)
(e::float-matrix-cross-product <1x3 float matrix> <1x3 float matrix>)
(e::float-matrix-cross-product A B)calculates the quantity more conventionally written as
A x B
(e::float-matrix-dot-product <float matrix> <float matrix>)
(e::float-matrix-hadamard-product <float matrix> <float matrix>)
(e::float-matrix-invert <float matrix>)
(e::float-matrix-multiply <float matrix> <float matrix>)
(e::float-matrix-multiply-by-scalar <float matrix> <real>)
(e::float-matrix-normalize <float matrix>)
(e::float-matrix-product-of-diagonals <square float matrix>)
(e::float-matrix-subtract <float matrix> <float matrix>)
(e::float-matrix-trace <square float matrix>)
(e::float-matrix-transpose <float matrix>)
(e::float-matrix-transpose-square-matrix! <square float matrix>)
Wraith Scheme provides two related capabilities that together allow other programs -- that is, other Macintosh applications or other Unix processes -- (1) to share data with Wraith Scheme and (2) to interrupt Wraith Scheme when necessary; for example, when they have new data ready to share.
These two capabilities are probably the most complicated and bewildering of Wraith Scheme's enhancements. They will probably only be of interest to users who are at least moderately experienced programmers in other programming languages, and who have at least some familiarity with Unix system calls and computer architecture. In particular, knowledge of memory-mapping and of hardware and software interrupts is almost certainly required to understand and to use these enhancements.
Overview of the Foreign-Function Interface:
The intent is that data can be shared by way of shared memory areas created using the Unix "mmap" function. Wraith Scheme has a variety of procedures that allow Wraith Scheme to create memory-mapped areas associated with files that you select. Those files may be read or written by any Wraith Scheme process -- MomCat or kitten. You can then create other programs which also memory-map the same files, and those other programs can then thereby share data with Wraith Scheme.
The interrupt system allows other processes to signal Wraith Scheme when they have something for it to do. It is based on the Unix "signal" capability, and uses the signal called "SIGUSR1". It also uses another area of shared memory, which contains a table of flags indicating what a Wraith Scheme process should do when it receives a SIGUSR1 signal. There are 1024 such flags, so that in effect, there are 1024 different interrupts. That same area of shared memory also contains a table of the Unix process identifications (PIDs) of the MomCat and kittens, which any other process may use to figure out just where to send the SIGUSR1.
Wraith Scheme itself contains a table of 1024 interrupt handlers, stored in Wraith Scheme main memory, that tell what to do for each interrupt. Each handler tells what kitten is expected to handle the interrupt -- and that need not be the same as the kitten that received the SIGUSR1 -- and an S-expression which that kitten is supposed to evaluate to deal with the interrupt. You may set interrupt handlers at will.
The way a kitten receiving a SIGUSR1 responds to that signal, is by adding the given S-expression into the input queue of the kitten that is supposed to handle it. The interrupt will not be handled until that latter kitten is waiting in its top-level loop with nothing else to do. Interrupts are also disabled during garbage collection.
Note carefully, that two separate actions are required for Wraith Scheme to deal with an interrupt:
A and B may be the same process, though it is probably better that they be different.
The Wraith Scheme process that responds to the interrupt may or may not be the one that handles it.
This mechanism provides what I might describe as a "coarse-grained" foreign-function interface: It is technically possible to use the interface to allow Wraith Scheme to make lots of calls to simple functions that run quickly. Yet it is probably more useful to use it for foreign functions that do substantial autonomous work, such as processing large data structures at Wraith Scheme's behest, or preparing large data structures for Wraith Scheme's perusal.
The Unix "mmap" function is in my opinion poorly documented and seems to be little used, or at least little understood. Its original purpose was evidently to direct the operating system to copy an entire file into a contiguous area of a process's address space, so that its contents could be read and written as elements of a big array, or perhaps a big struct, instead of forever having to seek back and forth in the file and use functions like "read" and "write" to access data. For many uses of files, this mmap interface much simplifies and speeds up file access.
When the file is loaded in, the operating system retains the ability to "page out" portions of the file that are little used. In doing so, the operating system uses the file itself as the "swap space" for the paged-out portions.
More than one process can use the same mmapped file. The operating system keeps track of the actual physical address of the file image, maps an appropriate portion of each process's virtual address space to the physical image of the file, and tells the process where it is via the value returned from "mmap" itself. This mechanism is very useful -- perhaps when the file is a big database that is required by several different processes. The processes that use the file have to make sure to use an appropriate protocol that will not get the database mixed up because of near-simultaneous writes and so on, but they would have to do that even if they were accessing the file on a disc.
When two processes use "mmap" to share memory, they kind of use the function backwards from its original intent. One of the processes creates a scratch file of the appropriate length, and writes it full of zeros (or whatever). Then all of the processes mmap the scratch file to their own address space, wherein it becomes an area of memory that is shared by all processes.
Details and Procedures for Sharing Memory:
Wraith Scheme encapsulates information about shared memory areas in Wraith Scheme objects called "memory-mapped blocks", which are stored in Wraith Scheme main memory. Notwithstanding the name, such a Wraith Scheme object does not actually contain a memory-mapped area, just a pointer to it, along with other information about the block in question.
When several Wraith Scheme processes -- a MomCat and some kittens -- are running in parallel, they are all separate Unix processes. Therefore, even though the "memory-mapped block" object is itself stored in Scheme main memory, where any of those Wraith Scheme processes can get at it, actual the memory-mapped area, to which the memory-mapped block points, is not accessible to any given Wraith Scheme process until that process itself has used the Unix "mmap" function to make the block available to itself.
There is one Wraith Scheme procedure, "e::make-memory-mapped-block", to memory-map the block the first time (in which case a file associated with it is also created and written full of zeros). That procedure memory-maps the block only in the Wraith Scheme process which executes it, and returns a memory-mapped block object describing and pointing to the actual area that has been mapped. A second Wraith Scheme procedure, "e::memory-map-block-in-current-kitten", takes a pre-existing instance of memory-mapped block as an argument, and uses the information stored in it to memory-map the block anew in whatever Wraith Scheme process is executing that second primitive. In this way, a given memory-mapped block may be made available to as many Wraith Scheme processes as need it.
The reason why the first of those two primitives does not immediately memory-map the block in all extant Wraith Scheme processes is that there is no way for one Wraith Scheme process to get another Wraith Scheme process to do something immediately. You could be misled into thinking that all Wraith Scheme processes had memory-mapped the block when in fact they had not.
The memory regions used for these blocks are allocated from a large area of Wraith Scheme shared memory that is reserved when Wraith Scheme starts running. The allocation mechanism is trivial -- it simply goes straight through the available area until it runs out. There is no provision to "free" the memory in such a memory-mapped blocks.
The amount of memory available for these blocks depends on whether you are using a Macintosh with Intel processors or one with Apple's proprietary processors ("Apple silicon"): In the former, it is about 150 MByte, and in the latter it is more than 100 GByte. (The reason for the difference has to do with how Apple's programming software reserves memory for the two different processor types.)
Utility Procedures for Memory-Mapped Blocks:
Utility procedures that deal with memory-mapped blocks follow. See the more detailed descriptions in the Wraith Scheme Dictionary.
(e::make-memory-mapped-block <size in bytes> <path to associated file>)
Create and return a memory-mapped block of the given size, associated with the given file, memory-mapped in the Wraith Scheme process that executed the procedure, with the file written full of zeros.
(e::memory-map-block-in-current-kitten <a memory-mapped block>)
Memory-map an existing memory-mapped block in the Wraith Scheme process that is executing the procedure, which is presumably one in which that block has not already been mapped. Associate the block with the same file with which it was originally mapped, but do not change the file.
(e::memory-mappable-space-size)
Return the size in bytes of that portion of Wraith Scheme's pre-reserved block of mappable memory that has not yet been allocated.
(e::make-offsets <start-offset> <list of variable names and sizes>)
Given a starting offset, and a list of pairs of variable names and sizes, define new Scheme variables using the given names, that point to the given locations. The names of the new variables are obtained by appending "-offset" to the variable names given. Returns the total of all the sizes.
This procedure creates pointers that other procedures can use to reference memory in mmapped blocks, but this procedure itself does not attempt to read or write anything that the pointers point to.
(e::memory-mapped-block? <object>)
Is the object a memory-mapped block?
Procedures for Accessing Memory-Mapped Blocks:
There are many procedures for accessing memory-mapped blocks. They include (1) a procedure for atomic test-and-set within memory-mapped blocks, (2) procedures for reading and writing four lengths of integer data, one at a time or in vectors, with optional sign-extension, (3) procedures for reading and writing floating-point numbers, one at a time or in vectors, (4) procedures for reading and writing "C"-style (null-terminated) strings, one at a time, and (5) procedures for converting back and forth between C-style booleans on the one hand, and #t and #f on the other.
The first procedure provides atomic test-and-set of the least significant bit in a 64-bit integer in a memory-mapped block.
(e::peek-poke-atomic <memory-mapped block> <offset>)
Returns whether the bit was zero before the test-and-set operation. If several processes attempt this operation at the same time, at most one will find that the bit was zero.
The next four procedures provide read access to memory-mapped blocks for individual data elements. They are perhaps most useful if the data are integers.
(e::peek8 <memory-mapped block> <offset>) (e::peek16 <memory-mapped block> <offset>) (e::peek32 <memory-mapped block> <offset>) (e::peek64 <memory-mapped block> <offset>)
Return the content of the given location, as a 64-bit integer, not sign-extended.
Note that there is no requirement that the content addressed actually be intended as an integer; Wraith Scheme has no idea of what other programs may be storing at that location.
The next three procedures also provide read access to memory-mapped blocks
for individual data elements.
They are like the procedures immediately above, except that
the three below sign-extend the result when converting it to a 64-bit
signed integer.
(e::peek8-sign-extend <memory-mapped block> <offset>) (e::peek16-sign-extend <memory-mapped block> <offset>) (e::peek32-sign-extend <memory-mapped block> <offset>)
Return the content of the given location, as a 64-bit integer, sign-extended.
Each is called with a memory-mapped block as its first argument, and an offset in bytes from the beginning of the block, at which the read is to take place, as its second argument. The reads are respectively of quantities 8, 16 and 32 bits in length -- that is, one, two and four bytes -- and the offsets must be integral multiples of those numbers of bytes. The quantities returned are 64-bit integers, and the data returned are sign extended. Thus a peek8-sign-extend of a byte with all bits on returns -1, not 255.
Note that there is no requirement that the content addressed actually be intended as an integer; Wraith Scheme has no idea of what other programs may be storing at that location.
The next four procedures provide read access to memory-mapped blocks
for vectors of data. They load a Scheme vector with data from
a vector in a memory-mapped block. They are perhaps most useful
if the data are integers.
(e::peek8-set-vector! <memory-mapped block> <offset> <vector>) (e::peek16-set-vector! <memory-mapped block> <offset> <vector>) (e::peek32-set-vector! <memory-mapped block> <offset> <vector>) (e::peek64-set-vector! <memory-mapped block> <offset> <vector>)
Return the content of the given locations, as a vector of 64-bit integers, not sign-extended, by modifying the given vector and returning it.
Each is called with a memory-mapped block as its first argument, an offset in bytes from the beginning of the block, at which the read is to begin, as its second argument, and a vector as its third argument. The number of data elements to be read is presumed to be the length of the vector that is passed as the last argument to the procedure. The individual reads are respectively of quantities 8, 16, 32 and 64 bits in length -- that is, one, two, four and eight bytes -- and the offsets must be integral multiples of those numbers of bytes. The quantities returned are 64-bit integers, but the data returned are not sign extended. Thus a byte with all bits on is read as 255, not -1. The data read are stored in the given vector, and that vector is returned as modified.
Note that there is no requirement that the content addressed actually be intended as integers; Wraith Scheme has no idea of what other programs may be storing at that location.
The next three procedures also provide read access to memory-mapped blocks
for vectors of data. They are like the procedures immediately above, except that
the three below sign-extend the results when converting them to 64-bit
signed integers.
(e::peek8-set-vector-sign-extend! <memory-mapped block> <offset> <vector>) (e::peek16-set-vector-sign-extend! <memory-mapped block> <offset> <vector>) (e::peek32-set-vector-sign-extend! <memory-mapped block> <offset> <vector>)
Return the content of the given locations, as a vector of 64-bit integers, sign-extended, by modifying the given vector and returning it.
Each is called with a memory-mapped block as its first argument, an offset in bytes from the beginning of the block, at which the read is to begin, as its second argument, and a vector as its third argument. The number of data elements to be read is presumed to be the length of the vector that is passed as the last argument to the procedure. The individual reads are respectively of quantities 8, 16 and 32 bits in length -- that is, one, two and four bytes -- and the offsets must be integral multiples of those numbers of bytes. The quantities returned are 64-bit integers, and the data returned are sign extended. Thus a byte with all bits on is read as -1. The data read are stored in the given vector, and that vector is returned as modified.
Note that there is no requirement that the content addressed actually be intended as an integer; Wraith Scheme has no idea of what other programs may be storing at that location.
The next four procedures provide write access to memory-mapped blocks
for individual integers.
(e::poke8 <memory-mapped block> <offset> <integer>) (e::poke16 <memory-mapped block> <offset> <integer>) (e::poke32 <memory-mapped block> <offset> <integer>) (e::poke64 <memory-mapped block> <offset> <integer>)
Each is called with a memory-mapped block as its first argument, an offset in bytes from the beginning of the block, at which the write is to take place, as its second argument, and an integer to be placed there as its third argument. The writes are respectively of quantities 8, 16, 32 and 64 bits in length -- that is, one, two, four and eight bytes -- and the offsets must be integral multiples of those numbers of bytes. The integers to be written must be in the range appropriate for a 64-bit fixnum, and will silently have their more significant bits removed in sufficient quantity that the result fits in the space provided.
The next four procedures provide write access to memory-mapped blocks
for vectors of integers.
(e::poke8-set-vector! <memory-mapped block> <offset> <vector>) (e::poke16-set-vector! <memory-mapped block> <offset> <vector>) (e::poke32-set-vector! <memory-mapped block> <offset> <vector>) (e::poke64-set-vector! <memory-mapped block> <offset> <vector>)
Each is called with a memory-mapped block as its first argument, an offset in bytes from the beginning of the block, at which the write is to begin, as its second argument, and a vector of integers to be written as its third argument. The number of data elements to be written is presumed to be the length of the vector that is passed as the last argument to the procedure. The individual writes are respectively of quantities 8, 16, 32 and 64 bits in length -- that is, one, two, four and eight bytes -- and the offsets must be integral multiples of those numbers of bytes. The integers to be written must be in the range appropriate for a 64-bit fixnum, and will silently have their more significant bits removed in sufficient quantity that the result fits in the space provided.
The next procedure provides read access to memory-mapped blocks
for individual floating-point numbers.
(e::peek64-float <memory-mapped block> <offset>)
This procedure is called with a memory-mapped block as its first argument, and an offset in bytes from the beginning of the block, at which the write is to take place, as its second argument. The offset must be a multiple of eight.
The next procedure provides write access to memory-mapped blocks
for individual floating-point numbers.
(e::poke64-float <memory-mapped block> <offset> <number>)
This procedure is called with a memory-mapped block as its first argument, an offset in bytes from the beginning of the block, at which the write is to take place, as its second argument, and a number as its third argument. The offset must be a multiple of eight. It does not matter whether the third argument is stored as a fixnum or a flonum; Wraith Scheme will convert any fixnums to flonums before performing the store.
The next procedure provides read access to memory-mapped blocks
for vectors of floating-point numbers.
(e::peek64-float-vector <memory-mapped block> <offset> <vector>)
This procedure is called with a memory-mapped block as its first argument, an offset in bytes from the beginning of the block, at which the read is to begin, as its second argument, and a vector as its third argument. The offset must be a multiple of eight. The number of flonums to be read is presumed to be the length of the given vector. The data read are stored in the given vector, and that vector is returned as modified.
The next procedure provides write access to memory-mapped blocks
for vectors of floating-point numbers.
(e::poke64-float-set-vector! <memory-mapped block> <offset> <vector>)
This procedure is called with a memory-mapped block as its first argument, an offset in bytes from the beginning of the block, at which the write is to take place, as its second argument, and a vector as its third argument. The offset must be a multiple of eight. The number of flonums to be written is presumed to be the length of the given vector. It does not matter whether the elements of the given Scheme vector are stored as a fixnums or flonums; Wraith Scheme will convert any fixnums to flonums before performing the stores. The data read are stored in the given vector, and that vector is returned as modified.
The next procedure provides read access to memory-mapped blocks
for null-terminated strings. Strings of this form are commonly used in C,
C++, and many other programming languages.
(e::peek-c-string <memory-mapped block> <offset>)
This procedure is called with a memory-mapped block as its first argument, and an offset in bytes from the beginning of the block, at which the read is to take place, as its second argument.
If any subsequent action should change the content of the given memory-mapped block at the given offset, the Scheme string already returned by this procedure will not change; it contains a copy of the original data, not some kind of reference or pointer to the original data.
The next procedure provides write access to memory-mapped blocks
for null-terminated strings. Strings of this form are commonly used in C,
C++, and many other programming languages.
(e::poke-c-string <memory-mapped block> <offset> <string>)
This procedure is called with a memory-mapped block as its first argument, an offset in bytes from the beginning of the block, at which the write is to take place, as its second argument, and a string as its third argument. There must be sufficient space in the memory-mapped block, after the given offset, for the null-terminated string to fit.
The next two procedures convert back and forth between C-style booleans
and Scheme objects. They are useful for dealing with foreign booleans.
(e::c-boolean->scheme-boolean <number>)
(e::scheme-boolean->c-boolean <Scheme object>)
Details and Procedures for the Interrupt System:
The Wraith Scheme Cocoa implementation actually has three slightly different interrupt mechanisms in place and available to users. They are all based on the Unix "signal" software interrupts. Only one is used for the foreign-function interface, but I will describe the others here as well.
The first interrupt mechanism is a very simple signal-handler for the Unix "SIGINT" interrupt, that resets Wraith Scheme when that signal is received. It has actually been in Wraith Scheme for a long time, even in most of the 32-bit versions; I just forgot to document it. If anything sends the SIGINT interrupt to any Wraith Scheme process, that process will probably reset itself to the top-level loop soon. If it does not, the problem is most likely an implementation error, and my fault.
To use this mechanism, imagine that you have used the Unix "ps" command, or some other means, to determine the Unix process identification number of a Wraith Scheme process. Suppose for purposes of discussion that that process identification is 12345. Then, bearing in mind that the literal value of SIGINT is 2, you might type
kill -2 12345
in a Terminal shell. That Wraith Scheme process should shortly reset itself.
Incidentally, SIGINT is what is typically sent to Unix command-line processes when the user types "control-C". Note, however, that control-C doesn't work for Macintosh applications -- typing control-C to Wraith Scheme will not make it stop running.
The second interrupt mechanism involves a signal-handler for the Unix "SIGALRM" interrupt, and some procedures to use the underlying Unix "alarm" mechanism, which in turn will use this interrupt.
The procedures that deal with this mechanism are:
(e::alarm)
This procedure is actually not defined in Wraith Scheme. You get to define it yourself, as a lambda expression with no arguments, to do whatever you want to have happen when an "alarm" interrupt occurs.
(e::alarm?)
Returns whether an alarm is presently set.
(e::alarm-time)
Returns the Unix time at which any presently set alarm will go off. If no alarm is set, returns -1.
(e::set-alarm! <non-negative integer>)
If the integer is positive, sets an alarm to go off that number of seconds in the future. If the integer is zero, turns off any alarm that has already been set. Normally returns #t, but may return #f if any of the underlying Unix system calls, that are used to set up the alarm, should fail.
You may use the procedure "e::set-alarm!" to cause Wraith Scheme to interrupt itself at a time in the future; when that time occurs, the procedure "e::alarm" will run. You may also use the procedures "e::alarm" and "e::alarm-time" respectively to tell whether an alarm is presently set and at what time (Unix time) it will occur.
You may also cause "e::alarm" to run by sending a "SIGALRM" signal to Wraith Scheme from some other program.
Use of these procedures makes it possible to start something happening automatically at a specified time in the future. These procedures provide a rather straightforward interface to the Unix "alarm" system call, which is the mechanism Wraith Scheme uses for implementing them.
The alarm is made to go off by pushing the S-expression '(e::alarm) into the input queue of the Wraith Scheme kitten in which the alarm was set. If that kitten is busy doing something else at the time, the alarm will not be processed until the kitten is free. Thus the alarm system does not provide a truly asynchronous interrupt; for an alarm to happen promptly you must run it in a kitten that is not busy.
If the symbol "e::alarm" is not bound to a value, or is not bound to a lambda expression, then no alarm will go off. Wraith Scheme will report an error if an alarm goes off while "e::alarm" is bound to a lambda expression that requires arguments.
The third interrupt mechanism is more general and more powerful: It uses the Unix "SIGUSR1" interrupt, and provides a way whereby any Unix process -- such as any application -- may send an interrupt to any Wraith Scheme process, and in so doing may indicate which of a user-selected variety of interrupt handlers will run in response to the interrupt. As I write these words, there are 1024 logically distinct interrupts, any combination of which may be requested at the same time, and each such interrupt may have its own, different handler, in the form of Wraith Scheme code that you specify. The mechanism to do these things has several parts that you may use.
To begin with, there is a region of memory-mapped shared memory, associated with a publicly known binary file, that contains a table of 1024 boolean flags used to specify what interrupts are requested. The idea is that any program that needs to interrupt Wraith Scheme may memory-map that file into its own address space, set whatever flag corresponds to the interrupt it needs, and then send signal SIGUSR1 to some Wraith Scheme process. As an aid to finding out the Unix process identifications (PIDs) of Wraith Scheme processes, that piece of memory-mapped shared memory also contains a table of all the PIDs of all running Wraith Scheme processes, indexed by kitten number. The file also contains a table of flags that show whether an interrupt handler is installed or not.
Wraith Scheme automatically maintains the table of PIDs and the table of flags that shows whether interrupt handlers have been installed. Wraith Scheme also will automatically clear the flag that shows whether a particular interrupt has been requested, when a requested interrupt has been handled. You yourself must set the flags indicating that an interrupt is requested. Further discussion of the set-and-clear mechanism for interrupt-requested flags follows shortly.
Wraith Scheme will create that file for you at path "Library/Application Support/WraithScheme/Wraith Scheme Interrupt Information" relative to your home directory. Thus in my own file system, the full path to that file is "/Users/JayFreeman/Library/Application Support/WraithScheme/Wraith Scheme Interrupt Information", but in your file system, your user name will appear instead of "JayFreeman".
To save typing, Wraith Scheme provides a procedure that you may call to obtain the full path to that file. See the discussion of procedure "e::interrupt-file-information", below. Note that you may have to add extra double-quotes to the string returned, because of the embedded blank spaces, depending on what you want to do with the path.
Here is a C++ typedef for the structure of that file, and some #defines for the constants in it that are valid as I write these words. The file contains exactly one instance of this struct, aligned starting at offset zero in the file.
#define ABSOLUTE_MAX_KITTENS 32
#define NUMBER_OF_INTERRUPTS 1024
typedef struct interruptInformationFileContent_struct {
volatile int KittenPID[ ABSOLUTE_MAX_KITTENS ]; // 32-bit int!!
volatile char interruptRequested[ NUMBER_OF_INTERRUPTS ];
volatile char interruptInstalled[ NUMBER_OF_INTERRUPTS ];
} interruptInformationFileContent;
Note one possible "gotcha" in using that typedef. The array "KittenPID" is an array of 32-bit integers. Depending on your convention and personal preference, you may have to change the declaration of the array depending on whether you use the typedef in 32-bit or 64-bit code.
Each Wraith Scheme process memory-maps that same piece of shared memory into its own address space as well. Thus, Wraith Scheme can look through the table to find which interrupt or interrupts are pending. There is an implicit prioritization of interrupts, as well: Whenever a Wraith Scheme process responds to SIGUSR1, it will look through the interrupt flags in numerical order, starting with interrupt zero. If you have not specified a handler for some interrupt, nothing happens, but if a handler is specified, Wraith Scheme will arrange for it to run (just what that means is explained in a paragraph or two). Once the handler has been set up to run, Wraith Scheme clears the flag for that interrupt, and proceeds to the next interrupt that has a flag set.
There is also a table of interrupt handlers stored in Wraith Scheme main memory, indexed by interrupt number. An empty list corresponds to "no handler". A valid non-empty table entry is a cons cell whose car is a kitten number -- the number of the kitten that is supposed to execute the handler -- and whose cdr is an S-expression to be added to the input queue for that kitten. I refer to this S-expression as the "handler" for the interrupt. It can be anything you like -- just a number or a string might be enough to demonstrate that an interrupt is working (it will eventually appear in the Wraith Scheme window of the kitten in question) -- but what will presumably be most useful will be a quoted procedure application, something like
'(do-something-wonderful foo bar baz)
that the kitten in question is supposed to execute.
You have the option of using the table in the interrupt information file, that shows whether interrupt handlers are installed, to decide whether or not to request an interrupt, or to present an error message if some other part of your code has neglected to install a necessary interrupt handler. Wraith Scheme will in any case not attempt to handle an interrupt for which no handler has been installed. If you inadvertently request an interrupt for which no handler has been installed, Wraith Scheme will not present an error message, but it will clear the interrupt-requested flag for that interrupt.
Be careful not to confuse the table of interrupt handlers with the table of booleans showing whether particular handlers have been installed. The former is a data structure in Wraith Scheme main memory; the latter is a data structure in the publicly-known binary file describing the state of the Wraith Scheme interrupt system.
Finally, Wraith Scheme has a critical-section blocking mechanism to make sure that even if two separate Wraith Scheme processes should receive SIGUSR1 at the same time, no pending interrupt will run more than once.
Let's summarize: When a Wraith Scheme MomCat or kitten processes a SIGUSR1 interrupt for which you have defined a handler, it will end up adding an S-expression of some kind to the input queue of some Wraith Scheme process. The process whose input queue gets the S-expression may or may not be the process that received the SIGUSR1. You can send the SIGUSR1 interrupt to any Wraith Scheme process you like, but the kitten to whose queue the S-expression gets added will always be the kitten whose kitten number is the car of the entry for that interrupt in the table of interrupt handlers.
Note that the same table of interrupt-pending flags is shared by all Wraith Scheme processes, as is the same table of interrupt handlers and the same table indicating whether handlers have been installed. Therefore it does not matter which Wraith Scheme process receives a SIGUSR1; any one can deal equally well with any interrupt. Notwithstanding, the response time for handling an interrupt will necessarily depend on how busy the Wraith Scheme process was when it received the SIGUSR1 signal.
The procedures that deal with interrupts are:
(c::interrupt-handler-vector)
Return the entire vector of 1024 interrupt handlers. It is probably not a good idea to change interrupt handlers by modifying this vector directly; Wraith Scheme is quite likely to crash if the format of the vector entries is not exactly right: Use the following procedures instead.
(c::set-interrupt-handler! <interrupt-number> <kitten-number> <S-expression>)
Set an entry in Wraith Scheme's table of interrupt handlers to make the given interrupt be handled by means of the given kitten evaluating the given S-expression.
(c::clear-interrupt-handler! <interrupt-number>)
Make Wraith Scheme ignore the given interrupt, by setting its entry in Wraith Scheme's table of interrupt handlers to the empty list.
(c::clear-interrupt-requested! <interrupt-number>)
Clears the interrupt-requested flag for the given interrupt, which may be useful for debugging or error-handling if it has accidentally been set.
(c::interrupt <kitten-number> <interrupt-number>)
Turn on the interrupt flag for the given interrupt, and send SIGUSR1 to the given kitten: Wraith Scheme thereby sends an interrupt to itself.
(e::interrupt-file-information)
This procedure provides easy access to the name and size of the public file that contains the Wraith Scheme interrupt flags and the list of Wraith Scheme Unix process identifiers. It returns a multiple-values return whose first element is a string giving the full absolute path to the file, and whose second element is an integer indicating its size in bytes.
Precautions for Using Interrupts:
The Wraith Scheme interrupt system has a great deal of power and flexibility, but also has some important limitations. Notably, there is no queue of pending interrupts. Therefore:
Demonstrating the Foreign-Function Interface in Wraith Scheme:
The foreign-function interface is set up so that it is possible to demonstrate how it works just by having different Wraith Scheme processes use it to share information and to interrupt each other. That will at least let you put off the scary task of writing actual memory-mapping code on your own, for a while. Here is how to do a short demonstration.
First, get Wraith Scheme going with at least two kittens besides the MomCat. In one kitten, enter the following Scheme code:
(define a (e::make-memory-mapped-block 1000 "/tmp/foo")) (e::memory-mapped-block? a) (e::poke8 a 0 1) (e::poke16 a 2 2) (e::poke32 a 4 3) (e::poke64 a 8 4)
What that does is define a memory-mapped block of size 1000 bytes, associated with file "/tmp/foo", double-check that it has been created (with the test predicate, "e::memory-mapped-block?", and then poke some data into it, at offsets 0, 2, 4, and 8.
Next, go to some other kitten, and let's see about accessing that data from there. If you just try to do it right away, you will get an error:
(e::peek8 a 0) Problem: Memory-mapped block has not yet been mapped for this kitten -- cannot read value. (Resetting) Top-level loop ...
because you have not yet told that kitten to do any memory-mapping. What you must first do is
(e::memory-map-block-in-current-kitten a)
which will use the information stored in the Scheme "memory-mapped block" object "a" to map the same block in the current kitten. Then you can read the data:
(e::peek8 a 0) 1 (e::peek16 a 2) 2 (e::peek32 a 4) 3 (e::peek64 a 8) 4
What about interrupts? Let's put in a simple handler for interrupt 19, that will run on kitten 1.
(c::set-interrupt-handler! 19 1 '(display "Hello, world\n"))
You can run that code in any kitten you like. Now, let's go to kitten 2, and from there interrupt kitten 0, and cause it to respond to interrupt 19. In kitten 2's input, type this:
(c::interrupt 0 19)
There will be nothing showing in kitten 0's window to show that it has responded to the interrupt, but if you look in the window for kitten 1 you will see
Hello, world #t
which was not there before. The interrupt handler has run.
Remember to delete the shared-memory file, "/tmp/foo", when you are done with it. Wraith Scheme can't very well do that for you automatically, because it has no idea what other processes may be using the file and when they will be done with it.
Demonstrating the Foreign-Function Interface with Other Programs:
Get Wraith Scheme going and look in the "Source Code Examples" submenu of the "Help" menu. There are several C++ programs there that are designed to illustrate the Wraith Scheme foreign-function interface. Open the one labeled "Memory Map C++ Demo".
Copy that code to a file somewhere, then compile it from a Unix (Terminal) command line, with the command that is shown in the program text itself. (To do so may require that you have Apple's "Xcode" development environment installed on your Macintosh, or that you have installed various Unix utilities by other means. It works for me with Xcode installed on my Mac Pro.) Don't run it yet.
Once that code is ready to run, cut and paste the following Scheme code into Wraith Scheme. I have added comments in-line in the code block to explain what is happening.
;; The first line creates a memory-mapped block that ;; is associated with the file "/tmp/foo" -- the same ;; file that the compiled C++ program is going to use. (define a (e::make-memory-mapped-block 1000 "/tmp/foo")) ;; Now, let's put some data in the file. (e::poke8 a 0 1) (e::poke16 a 2 2) (e::poke32 a 4 3) (e::poke64 a 8 4) ;; Let's check to be sure it is there -- ;; These commands should return 1, 2, 3 and ;; 4, respectively. (e::peek8 a 0) (e::peek16 a 2) (e::peek32 a 4) (e::peek64 a 8) ;; But notice that when we look 16 bytes further ;; on in the memory-mapped block, there is nothing ;; there but zeros. (e::peek8 a 16) (e::peek16 a 18) (e::peek32 a 20) (e::peek64 a 24) ;; Now let's run that C++ program. You could run it from ;; the Unix command line as well. All the C++ program ;; does is copy the data we put into the memory-mapped ;; block by using Scheme, into new locations 16 bytes ;; further on. Any output from the program goes into a ;; log file, so you can see what happened if there were ;; errors. (e::system "/tmp/MMapDemo >& /tmp/MMapDemo.log &") ;; However you are running the program, wait a second ;; or two to be sure it has had time to load and run. ;; Now, let's look and see if the data have been ;; copied. If all goes well, these next commands should ;; return, respectively, 1, 2, 3 and 4. (e::peek8 a 16) (e::peek16 a 18) (e::peek32 a 20) (e::peek64 a 24)
The Unix/C++ "mmap" function is a bit tricky to use, and I find it rather poorly documented, but this example should get you started on using it to share data between Wraith Scheme and other programs.
Now let's try an example that uses interrupts to tell Wraith Scheme
when the data have been copied. This is a whole new program that
is closely similar to the preceding one.
Get Wraith Scheme going and look in the "Source Code Examples" submenu of the "Help" menu. There are several C++ programs there that are designed to illustrate the Wraith Scheme foreign-function interface. Open the one labeled "Memory Map / Interrupt C++ Demo".
Copy that code to a file somewhere, then compile it from a Unix (Terminal) command line, with the command that is shown in the program text itself. (To do so may require that you have Apple's "Xcode" development environment installed on your Macintosh, or that you have installed various Unix utilities by other means. It works for me with Xcode 3.2 installed on my Mac Pro.) Don't run it yet.
Once that code is ready to run, cut and paste the following Scheme code into Wraith Scheme. I have added comments in-line in the code block to explain what is happening.
;; The first line creates a memory-mapped block that
;; is associated with the file "/tmp/foo" -- the same
;; file that the compiled C++ program is going to use.
(define a (e::make-memory-mapped-block 1000 "/tmp/foo"))
;; Now, let's put some data in the file.
(e::poke8 a 0 1)
(e::poke16 a 2 2)
(e::poke32 a 4 3)
(e::poke64 a 8 4)
;; Let's check to be sure it is there --
;; These commands should return 1, 2, 3 and
;; 4, respectively.
(e::peek8 a 0)
(e::peek16 a 2)
(e::peek32 a 4)
(e::peek64 a 8)
;; But notice that when we look 16 bytes further
;; on in the memory-mapped block, there is nothing
;; there but zeros.
(e::peek8 a 16)
(e::peek16 a 18)
(e::peek32 a 20)
(e::peek64 a 24)
;; Next, we need an interrupt handler.
(c::set-interrupt-handler! 42 0
'(begin (display (list (e::peek8 a 16)
(e::peek16 a 18)
(e::peek32 a 20)
(e::peek64 a 24)))
(newline)))
;; Now let's run that C++ program. You could run it from
;; the Unix command line as well. What the C++ program
;; does is first copy the data we put into the memory-mapped
;; block by using Scheme, into new locations 16 bytes
;; further on. Any output from the program goes into a
;; log file, so you can see what happened if there were
;; errors. Then it waits five seconds and sends an
;; interrupt -- number 42 -- to the MomCat, which will
;; read the copied values from shared memory and print
;; them out.
(e::system "/tmp/MMapInterruptDemo >& /tmp/MMapInterruptDemo.log &")
Two other programs demonstrate the use of the Wraith Scheme foreign-function
interface with Unix Sockets.
Get Wraith Scheme going and look in the "Source Code Examples" submenu of the "Help" menu. There are several C++ programs there that are designed to illustrate the Wraith Scheme foreign-function interface. Open the ones labeled "Socket C++ Demo -- Client Part" and "Socket C++ Demo -- Server Part".
Copy those source listings to files somewhere, then compile them from a Unix (Terminal) command line, with the commands that are shown in the program text itself. (To do so may require that you have Apple's "Xcode" development environment installed on your Macintosh, or that you have installed various Unix utilities by other means. It works for me with Xcode 3.2 installed on my Mac Pro.) Don't run them yet.
Once those two programs are ready to run, start Wraith Scheme. You don't need any extra kittens for the demo, but more than one is perhaps more fun. Enter the following Scheme code (in any kitten).
(define server-mmapped-block (e::make-memory-mapped-block 1000 "/tmp/serverMMap")) (c::set-interrupt-handler! 42 0 '(begin (display (e::peek-c-string server-mmapped-block 0)) (newline))) (define client-mmapped-block (e::make-memory-mapped-block 1000 "/tmp/clientMMap"))
Next, if you did not type the previous Scheme commands in the MomCat, go to the MomCat's window and type
(e::memory-map-block-in-current-kitten server-mmapped-block)
You must do that because the interrupt handler you have set up is going to have the MomCat read from that memory-mapped block.
Now, in a Terminal shell window, start the "SocketServer" program:
> SocketServer Making server socket: Binding... Starting to listen with a queue of 100 elements ... Server waiting for a connection ...
At that point, type control-Z and then "bg", which will keep the "SocketServer" program running in the background, and let you start the "SocketClient" program as well.
^Z [1]+ Stopped SocketServer > bg [1]+ SocketServer & > SocketClient Making client socket: Client is connecting ... Client has a connection, client Unix process identification is <whatever> Server has a connection. ################################ Message 0 ################################
Note that the Unix process identification of the client is provided by the Terminal-shell message from the client that begins "Client has a connection...".
Now go back to Wraith Scheme, and in the kitten where you entered the first batch of Scheme code, type what follows, being careful to change the second line of code so that it contains the actual process number of the client:
(e::poke-c-string client-mmapped-block 0 "Your favorite string.") (e::system "kill -2 <Unix process identification of client>")
In the MomCat's Wraith Scheme Window, you will find that the interrupt handler has typed
Your favorite string.
You can repeat the "e::poke-c-string" and "e::system" commands as many times you like, with whatever strings you like. The Terminal shell window will provide a description of what is going on like the following, in which I mindlessly repeated the command to poke "Your favorite string." several times, and in which the Unix process identification of the MomCat happened to be 2923.
################################ Message 0 ################################ Client wrote "Your favorite string." to server. Server read "Your favorite string." from client. About to do a system call with "kill -30 2923". ################################ Message 1 ################################ Client wrote "Your favorite string." to server. Server read "Your favorite string." from client. About to do a system call with "kill -30 2923". ################################ Message 2 ################################ Client wrote "Your favorite string." to server. Server read "Your favorite string." from client. About to do a system call with "kill -30 2923". ################################ Message 3 ################################ Client wrote "Your favorite string." to server. Server read "Your favorite string." from client. About to do a system call with "kill -30 2923". ################################ Message 4 ################################ Client wrote "Your favorite string." to server. Server read "Your favorite string." from client. About to do a system call with "kill -30 2923". ################################ Message 5 ################################
Foreign-Function Interface Recommendations and Reminders:
I might recommend the following general principles for using the Wraith Scheme foreign-function interface.
system("kill -30 <a Wraith Scheme process identifier>");
You can get the process identifier of any Wraith Scheme kitten by using the <interrupt info> pointer mentioned above, like this:
<kitten process identifier> = <interrupt info>->KittenPID[ kittenNumber];
See the demonstration programs a few sections above for more details on how to use the interrupt information data structure.
Wraith Scheme has an enhancement that allows creation and use of data structures that are set up automatically to be forgotten -- purged from Scheme main memory -- after some time has passed, even if they are not garbage in the formal sense of the word. The interface to forgettable objects lets you ask whether an object still exists before trying to use it, and provides you with knowledge and control of the precise details of when and if it disappears.
So what good is that?
As with most of the enhancements to Wraith Scheme, I put this one in because I thought I might use it in personal projects. I was intending to provide a facility usable by artificial intelligence projects to mimic the "short-term memory" of biological minds. Stored data can go away, and instead of having a program crash when it tries to use an invalid reference, the interface provides a way to tell that "I forgot", which the program can then deal with, perhaps by rebuilding a data structure or by going out and making a new, current, observation of relevant real-world data. (That is sort of like what you and I do when we forget things, though perhaps without the whining.)
Note the difference in behavior from standard Lisp garbage collection of unreferenced items. With forgettable objects, a program can have what it thinks is a valid reference to something, and it won't find out that the reference no longer works till it tries to use it.
But wait, there's more! I tried to create a mechanism that would also allow several other useful behaviors related to forgetting things, such as:
A forgettable object is in essence a new kind of Scheme object, which is a wrapper around any Scheme object and two additional items:
Technical Note: Expiration times are "Unix times" -- unsigned integers which are interpreted as seconds since the beginning of calendar year 1970 (common era). In Apple Macintosh 64-bit applications, such as Wraith Scheme, these integers are 64-bit, which means that Wraith Scheme's mechanisms for dealing with time will cease to operate correctly approximately 3 000 000 000 000 years from now.
If you are still using Wraith Scheme then, and you would like a better mechanism to deal with time, send me some EMail and I will see what I can do ...
Technical Note: Wraith Scheme's particular implementation of forgettable objects actually involves three new kinds of Scheme objects: forgettable-unexpired, forgettable-forgotten, and forgettable-remembered.
When a forgettable object is asked for its content, via procedure "e::forgettable-object", it returns two values. The first value is a boolean which is true if, and only if, its content is remembered. The second value depends on the first: If the object's content is remembered, the second value is that content. If not, the second value is #t.
A forgettable object cannot forget its content if that content is bound to something else in Wraith Scheme; that is, if the content is otherwise not garbage. The connection between a forgettable object and its content is something like what other programming languages call a "weak reference", but be careful, that term means different things to different people.
Garbage collection treats forgettable objects reasonably: A forgettable object is not garbage as long as any Wraith Scheme process has a way of accessing it in Scheme memory. The content of a forgettable object is not garbage as long as at least one of two conditions obtains: (1) The forgettable object itself is not garbage, or (2) any Wraith Scheme process has a way -- a chain of pointers -- of accessing that content in Scheme memory, other than through the forgettable object itself.
For example, a probability of remembering of 0.75 corresponds to a 75 percent chance of being remembered, and a 25 percent chance of being forgotten.
Programming Interface to Forgettable Objects:
(e::make-forgettable <given object> <a Unix time> <probability of remembering> )
Create and return an unexpired forgettable object containing the given object, with the given Unix time as its expiration time, and with the given probability of remembering.
(e::forgettable? <object>)
Is the given object a forgettable object?
(e::forgettable-forgotten? <object>)
Is the given object a forgettable object that has been forgotten?
(e::forgettable-remembered? <object>)
Is the given object a forgettable object that has been remembered?
(e::forgettable-unexpired? <object>)
Is the given object a forgettable object that is neither forgotten nor remembered?
(e::forgettable-object <forgettable-object>)
Returns multiple values: The first is #t if the forgettable object has not been forgotten and #f if it has been forgotten; the second is the stored object if the forgettable object has not been forgotten and is undefined if that object has been forgotten.
(e::forgettable-expiration-time <forgettable-object>)
Returns multiple values: The first is #t if the forgettable object has not been forgotten and #f if it has been forgotten; the second is the expiration time, which is still remembered by the forgettable object even if the object stored within it has itself been forgotten.
(e::forgettable-remember-probability <forgettable-object>)
Returns multiple values: The first is #t if the forgettable object has not been forgotten and #f if it has been forgotten; the second is the probability of remembering if the forgettable object has not been forgotten and is undefined if that object has been forgotten.
(e::set-forgettable-expiration-time! <forgettable-object> <a Unix time>)
Change the expiration time of the forgettable object to the new value provided. This operation will succeed if, and only if, the forgettable object is unexpired. Return #t if the operation was successful and return #f if not.
(e::set-forgettable-remember-probability! <forgettable-object> <probability>)
Change the probability of remembering of the given forgettable object to the new value provided. This operation will succeed if, and only if, the forgettable object is unexpired. Return #t if the operation was successful and return #f if not.
e::entropy-death
This symbol is bound to the largest value that Wraith Scheme can store as a signed fixnum; if taken as a Unix time, it corresponds to approximately 3 000 000 000 000 years in the future.
Technical Note: It is presumptuous of me to label an epoch so near with a symbol that suggests that the Universe will have achieved entropy death by then. I beg forgiveness from inhabitants of solar systems whose suns are faint red dwarves.
Some Uses of Forgettable Objects:
Wraith Scheme's "Kitten Graphics" system is in essence an implementation of the "Turtle Graphics" drawing system that Seymour Papert created for the Logo programming language in the late 1960s. I renamed it to fit Wraith Scheme's overall feline theme. The general idea of turtle graphics is that some kind of virtual creature moves around the drawing area carrying a pen to draw with. It responds to program commands to go forward, turn left or right, press the pen down so as to make a line, pick the pen up, and so on, and thereby draws a picture.
In the original system, the virtual creature was not virtual: It was an actual robot that crawled around a piece of paper taped to the floor. In Wraith Scheme Kitten Graphics, the virtual creature is a kitty pushing a ball of yarn.
The system draws in a special window, the Wraith Scheme Kitten Graphics window.
That window is closed when Wraith Scheme starts running. You may open it by checking
the "Show Kitten Graphics Window" menu item in the Wraith Scheme
Window Menu. That window looks like the following image:
The Kitten Graphics Window.
The kitty is in her "home" position, in the center of the drawing area of the window and facing upward, ready to start drawing. Her home position is always in the center of the drawing area, even if you have resized the window.
In the image shown, the kitty is pushing a ball of black yarn. Thus the next line to be drawn will be black.
There is a way to make the kitty invisible, so you can see the entire drawing without the kitty getting in the way -- I will describe how to do that shortly. There is another point to remember about kitty visibility: Drawing goes much faster when the kitty is invisible -- it takes the Macintosh a good deal of time to draw her image. On the other hand, drawing is much cuter when the kitty is in sight!
Drawing takes place in the square area that occupies most of the window. The background color of that area starts out the same as the background color of the text areas of the Wraith Scheme main window, but that is mostly so you can tell the different Kitten Graphics windows apart if you have more than one Wraith Scheme kitten running. You can reset the background color by using the color well that is at the right center of the window.
The kitty's ability to draw has nothing to do with whether she is visible or not: Hiding the kitty just gets her out of the way so you can see the entire drawing, and also speeds up the drawing process itself.
When you push the "Kitty Come Home" button, no line will be drawn while the kitty is returning to her home position.
I will give a detailed description of the Wraith Scheme procedures for drawing shortly, but before I go into detail let's give a simple example. Let's draw a square. The first Scheme procedure we use is "e::kitty-forward". We will go forward 100 points -- a "point" is the Macintosh unit for measuring distance on the computer screen. The command is:
(e::kitty-forward 100)
The result is:
The first line of a square.
Now let's turn left 90 degrees:
(e::kitty-left 90)
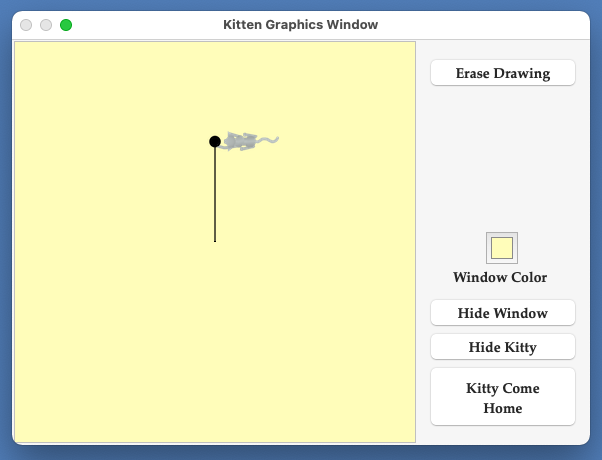
After turning left.
Go forward 100 more and turn left again:
(e::kitty-forward 100) (e::kitty-left 90)
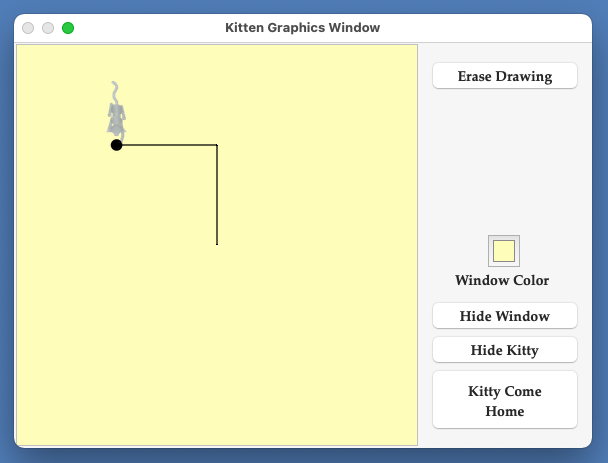
Two sides of a square.
Finish the square:
(e::kitty-forward 100) (e::kitty-left 90) (e::kitty-forward 100)
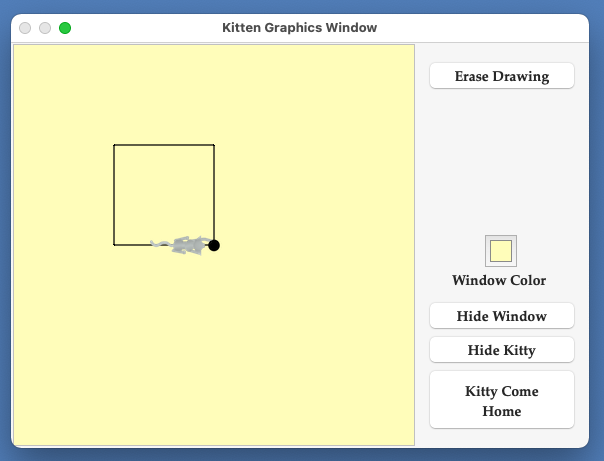
The completed square..
How about changing the background color to pale blue and hiding the kitty:
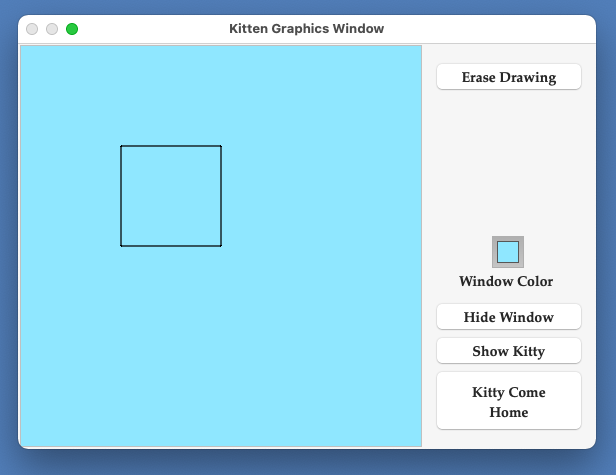
Tidied up.
I think that should have given you a good introduction to how this graphical system works ...
and it does get fancier ...
The procedures that deal with Kitten Graphics all start with "e::kitty-". They are:
(e::kitty-color)
(e::kitty-color? <object>)
(e::kitty-come-home)
This operation may also be performed with the "Kitty Come Home" button, located near the lower right corner of the Wraith Scheme Kitten Graphics Window.
If you perform this operation by pushing the button, and the kitty is in motion when you do so, the motion will not stop: It is possible that the kitty will immediately move away from home position. To stop the kitty, you must reset Wraith Scheme to top level.
This operation works whether the kitty is visible or not, and does not change the visibility of the kitty, only her location.
The kitty does not draw anything during her journey homeward.
(e::kitty-erase-drawing)
(e::kitty-forward <real number>)
The kitty will draw a line during this operation if, and only if, the pen is down.
(e::kitty-heading)
(e::kitty-hide)
This operation may also be performed with the "Hide Kitty" button, located near the lower right corner of the Wraith Scheme Kitten Graphics Window. That button has the title "Hide Kitty" when the kitty is visible, and "Show Kitty" when the kitty is invisible.
The kitty's ability to draw has nothing to do with whether she is visible or not. The kitty will draw whenever the pen is down, without regard to her visibility.
(e::kitty-left <real number>)
Makes the kitty turn left by the number of degrees which is its argument. Negative numbers make the kitty turn right.
(e::kitty-line-width)
(e::kitty-line-width? <object>)
(e::kitty-pen-down)
Tells the kitty to start drawing. The kitty will continue drawing until advised otherwise, except when she is being brought home by the "e::kitty-come-home" operation.
(e::kitty-pen-down?)
(e::kitty-pen-up)
Tells the kitty to stop drawing. The kitty will do no further drawing until advised otherwise.
(e::kitty-right <real number>)
Makes the kitty turn right by the number of degrees which is its argument. Negative numbers make the kitty turn left.
(e::kitty-set-color <integer>)
Changes the color with which lines will be drawn. This operation does not change whether the pen is up or down, and does not change the color of any lines that have already been drawn.
Line colors are represented by exact integers, as follows:
The reason for the rather odd order of colors is so that the same numbers may be used for sense light colors as for line colors, with similar result. Wraith Scheme sense lights predate Wraith Scheme kitten graphics, and only the integers [0..7] are used for sense light colors.
(e::kitty-set-line-width < real number >)
Changes the width in points (Macintosh screen coordinate units) with which lines will be drawn. This operation does not change whether the pen is up or down, and does not change the width of any lines that have already been drawn. The range of allowed line widths is rather arbitrarily limited to [0..10].
(e::kitty-show)
Makes the kitty visible.
This operation may also be performed with the "Show Kitty" button, located near the lower right corner of the Wraith Scheme Kitten Graphics Window. That button has the title "Show Kitty" when the kitty is invisible, and "Hide Kitty" when the kitty is visible.
The kitty's ability to draw has nothing to do with whether she is visible or not. The kitty will draw whenever the pen is down, without regard to her visibility.
(e::kitty-x)
(e::kitty-y)
Here is some sample Scheme code for simple drawings. Cut and paste these procedures into Wraith Scheme and try them out. Note that some of these procedures call others, so you will probably want to load them all. Some of the code is a little simplistic, but it will give you a sense of what kinds of things are possible with kitten graphics.
;; "circle-right" makes the kitty turn right in an approximation of a
;; circle of radius r -- actually a polygon of n sides.
(define (circle-right r n)
(letrec ((d (/ (* 2 c::pi r) n))
(theta (/ 360 n))
(circle-right-aux
(lambda (k)
(cond ((<= k 0) #t)
(#t (e::kitty-forward d)
(e::kitty-right theta)
(circle-right-aux (- k 1)))))))
(e::kitty-forward (/ d -2))
(circle-right-aux n)
(e::kitty-forward (/ d 2))
))
;; "circle-left" makes the kitty turn left in an approximation of a
;; circle of radius r -- actually a polygon of n sides.
(define (circle-left r n)
(letrec ((d (/ (* 2 c::pi r) n))
(theta (/ 360 n))
(circle-left-aux
(lambda (k)
(cond ((<= k 0) #t)
(#t (e::kitty-forward d)
(e::kitty-left theta)
(circle-left-aux (- k 1)))))))
(e::kitty-forward (/ d -2))
(circle-left-aux n)
(e::kitty-forward (/ d 2))
))
;; "many-circles" draws sixteen circles of radius r that meet
;; in a single point and are symmetrically spaced in angle.
(define (many-circles r)
(let ((one-pair
(lambda (theta)
(e::kitty-come-home)
(e::kitty-right theta)
(circle-left r r)
(e::kitty-come-home)
(e::kitty-right theta)
(circle-right r r))))
(for-each one-pair
(list 0 22.5 45 67.5 90 112.5 135 157.5))))
;; "splat" draws sixteen lines r long radiating
;; away from a single point, symmetrically spaced in angle.
(define (splat r)
(let ((one-line
(lambda (theta )
(e::kitty-come-home)
(e::kitty-right theta)
(e::kitty-forward r)
(e::kitty-forward (* r -2)))))
(for-each one-line
(list 0 22.5 45 67.5 90 112.5 135 157.5))))
;; "spiral" makes a vaguely spiral figure that has
;; n steps whose size increases from the initial value
;; of "step"
(define (spiral n step)
(cond ((> n 0)
(e::kitty-forward step)
(e::kitty-right 15)
(spiral (- n 1) (* step 1.02)))
(#t #t)))
;; With odd n, "n-point" makes an n-pointed star
;; out of lines that are "step" long.
(define (n-point n step)
(e::kitty-right (/ 360 (* n 4)))
(letrec ((aux
(lambda (k step)
(cond ((> k 0)
(e::kitty-forward step)
(e::kitty-right (- 180 (/ 180 n)))
(aux (- k 1) step))
(#t #t)))))
(aux n step)))
;; "color-test" demonstrates the different pen colors.
(define (color-test)
(define (test-color n)
(e::kitty-set-color n)
(e::kitty-forward 30)
(e::kitty-right 36)
(display (e::kitty-color))
(newline))
(for-each test-color '(0 1 2 3 4 5 6 7 8 9))
#t)
;; "up-and-down" demonstrates the commands to
;; raise and lower the pen.
(define (up-and-down)
(e::kitty-forward 10)
(e::kitty-pen-up)
(display (e::kitty-pen-down?))
(newline)
(e::kitty-forward 10)
(e::kitty-pen-down)
(display (e::kitty-pen-down?))
(newline)
(e::kitty-forward 10)
(e::kitty-pen-up)
(display (e::kitty-pen-down?))
(newline)
(e::kitty-forward 10)
(e::kitty-pen-down)
(display (e::kitty-pen-down?))
(newline)
(e::kitty-forward 10)
(e::kitty-pen-up)
(display (e::kitty-pen-down?))
(newline)
(e::kitty-forward 10)
(e::kitty-pen-down)
(display (e::kitty-pen-down?))
(newline)
(e::kitty-forward 10)
(e::kitty-pen-up)
(display (e::kitty-pen-down?))
(newline)
(e::kitty-forward 10)
(e::kitty-pen-down)
(display (e::kitty-pen-down?))
(newline)
)
;; "position-test" sends the kitty to a series of known positions
;; and prints them out in the Wraith Scheme Main Window.
(define (position-test)
(display (list (e::kitty-x) (e::kitty-y) (e::kitty-heading)))
(newline)
(e::kitty-forward 30)
(e::kitty-right 90)
(display (list (e::kitty-x) (e::kitty-y) (e::kitty-heading)))
(newline)
(e::kitty-forward 30)
(e::kitty-right 90)
(display (list (e::kitty-x) (e::kitty-y) (e::kitty-heading)))
(newline)
(e::kitty-forward 30)
(e::kitty-right 90)
(display (list (e::kitty-x) (e::kitty-y) (e::kitty-heading)))
(newline)
(e::kitty-forward 30)
(e::kitty-right 90)
(display (list (e::kitty-x) (e::kitty-y) (e::kitty-heading)))
(newline)
)
;; "fancy-colors" displays a lot of colored circles ...
(define (fancy-colors)
(e::kitty-set-color 1)
(many-circles 15)
(e::kitty-set-color 4)
(many-circles 30)
(e::kitty-set-color 8)
(many-circles 45)
(e::kitty-set-color 3)
(many-circles 60)
(e::kitty-set-color 5)
(many-circles 75)
(e::kitty-set-color 6)
(many-circles 90)
(e::kitty-set-color 7)
)
The Wraith Scheme enhancements for parallel processing are new and novel, and their development was fraught with bugs. It is therefore most important to note that you do not have to use them. Indeed, Wraith Scheme's default preferences are set up so that Wraith Scheme will run as a single process until and unless you request otherwise.
Introduction to Wraith Scheme Parallel Processing:
Since Wraith Scheme is named after a cat, I decided to continue the feline metaphor. The privileged Scheme process is called the "MomCat", and the others are called "kittens". The image of a mother cat trying to ride herd on a bunch of rambunctious offspring is perhaps appropriate.
There is no way to add kittens to a group of parallel Wraith Scheme processes that is already running. You may remove a kitten from a group via, e.g., the "Quit" command from that kitten's Wraith Scheme menu, but there is no means to put back a kitten that is gone, or to add a new one if you need more, other than changing the Wraith Scheme Preferences and restarting Wraith Scheme.
Each kitten has a number that identifies it uniquely. The MomCat also has a kitten number, which is always zero, and the terms "MomCat" and "kitten 0" are synonyms. The other kittens are numbered consecutively from 1.
Wraith Scheme with four processes running. Note the colored kitten icons at the far right end of the dock.
It is probably fair to say that one of the main reasons why I added a parallel processing capability to Wraith Scheme was because I thought it would be a neat thing to do. Notwithstanding, a few additional comments might offer useful guidance if you are contemplating using this capability.
Plausible uses for parallel Wraith Scheme might include running completely separate programs, running distinct programs which all need to act on a common data structure, or using one Wraith Scheme process to inspect or monitor another.
Among the hidden virtues of this kind of parallelism are reduction in swapping due to sharing a common Scheme memory, and leveraging the Unix mechanisms to switch and schedule processes instead of having to write your own.
Thus, for example, if two or more kittens apply "set!" to the variable "x" at more or less the same time, the value of "x" after all the "set!" operations have returned will be a value that one of the kittens intended, but if you do not impose any additional locking or sequencing mechanisms, there is no guarantee which of the several values of "x" will obtain.
On the other hand, the storage location referenced by "x" should not end up in an invalid state, such as might occur if different portions of the data structure at that storage location had ended up written by different kittens, who were perhaps attempting to write different kinds of values at more or less the same time.
Operations like "define", "set-car!", and "set-cdr!" -- indeed, everything that ends with a '!', and some others -- are similarly protected; that is, from the viewpoint of the Wraith Scheme evaluation engine, they are what is called atomic operations.
(e::kitten-number)
(c:kitten-reset <kitten-number>)
(e::momcat?)
(e::number-of-kittens)
Thus if you start a group of Wraith Scheme processes comprising a MomCat and five kittens, "e::number-of-kittens" returns five, and the kittens are numbered from zero -- the MomCat -- up to and including five.
(e::show-kittens)
I am not going to list the names of all these variables; there are too many.
Note that you may access any top-level loop variable from any process, not just from the process whose top-level loop binds the variable. Thus for example, if kitten 3 wishes to know what the last expression printed in kitten 5's top-level loop was, it may evaluate ">*<-5" to find out.
(e::tell-kitten <kitten-number> <any Scheme object>)
To see how the mechanism works, consider the normal operation of a conventional top-level read-eval-print loop. In psuedocode, and neglecting error-handling and some administrative details, it works like this:
loop forever {
read from the keyboard, characters which are
the text representation of a Scheme object.
parse the input and create a corresponding actual
Scheme object -- perhaps an S-expression or
an atom -- stored in Scheme memory.
evaluate what you've got.
print what results.
}
loop forever {
loop forever {
if there is anything in the input queue {
dequeue the item first put in
exit the inner loop.
}
if the user has typed any non-whitespace {
read from the keyboard, characters which
are the text representation of a
Scheme object.
parse the input and create a corresponding
actual Scheme object -- perhaps an
S-expression or an atom -- stored in
Scheme memory.
exit the inner loop.
}
}
evaluate what you've got.
print what results.
}
Note that the contents of the queue are not text strings, but Scheme objects which have already been parsed and evaluated.
For example:
(e::tell-kitten 1 '(+ 2 2))
puts into the input queue for kitten one the Scheme object (quote (+ 2 2)). When kitten one gets around to dealing with that queued object, it evaluates it -- to the number "4" -- and prints the text string "4" in its Wraith Scheme window. On the other hand, without the quote, the action is rather different. In the process of the procedure call:
(e::tell-kitten 1 (+ 2 2))
the argument "(+ 2 2)" is evaluated before the procedure is called. Thus what ends up in kitten one's input queue is the object "4" itself -- the work of evaluation has already been done.
The message here is that in order to make sure that the kitten addressed does the work, remember to quote the Scheme object that is the second argument of "e::tell-kitten".
The "e::tell-kitten" procedure is atomic, in the sense that no garbling or missing objects will arise if more than one kitten uses the procedure with the same first argument at the same time; for example, if kitten 1 executes
(e::tell-kitten 3 '(+ 2 2))at the same time that kitten 2 executes
(e::tell-kitten 3 '(+ 4 5))then kitten three will receive both commands in one order or the other, and will print out both 4 and 9 in its Wraith Scheme window in one order or the other.
A reset of any kind -- whether because of an error or because of use of the "Reset" command -- clears the input queue of the kitten that was reset.
(c::kitten-busy? <kitten-number>)
(c::kitten-input-queue <kitten-number>)
(c::kitten-empty-queue? <kitten-number>)
(c::kitten-purge-queue <kitten-number>)
(c::block <Scheme object in main memory>)
(c::release-block <locked Scheme object in main memory>)
(e::block-any-binding <pair>)
(e::block-symbol-binding <symbol>)
(c::set-blocked-binding! <lock from e::block-symbol-binding> <object>)
(e::test-and-clear! <pointer to pair containing a fixnum>) (e::test-and-set! <pointer to pair containing a fixnum>)
These procedures are said to "succeed" if, and only if, they change the value in the pair. Thus, "e::test-and-clear!" succeeds if, and only if, the previous value in the pair was nonzero, while "e::test-and-set!" succeeds if, and only if, the previous value in the pair was zero.
The procedures are atomic in the sense that if many kittens are trying to use "e::test-and-clear!" on the same pair at the same time, only one will succeed, and similarly for "e::test-and-set!". They are thereby useful for lockless coding in Wraith Scheme, provided that the programmer uses them correctly and consistently, and does not modify the number within the pair by means of other procedures.
For more detailed examples of the use of these procedures, see their entries in Wraith Scheme Dictionary, which is available via the Wraith Scheme Help menu.
Mechanisms useful for debugging parallel Wraith Scheme programs include:
It is extremely useful to have at least one more kitten operating than your Scheme program actually needs, to use as a debugging or monitoring window into how things are going. You can use such a kitten -- that is, you can perform Scheme operations in its Wraith Scheme window -- to examine your program, even as it runs: You can check the value of global data, evaluate expressions, and perhaps use other self-monitoring features of your program that you yourself have built in.
Among the variables you might choose to evaluate in the Wraith Scheme window of an extra kitten might be the top-level loop variables of the kittens that are actually running your program.
(e::show-locks)
This procedure is deceptive, because other kittens may be setting and releasing locks as it runs: The state of locks displayed may not be current moments later.
(c::release-locks)
This procedure is dangerous and deceptive, for several reasons:
An analogy with medical practice may be useful: Releasing locks is unlikely to cure a sick patient, but it may help prepare the cadaver for autopsy, provided that it doesn't blow up the morgue in the process.
(c::let-deadlock-time-out <a kitten number>)
This procedure provides a way to debug circumstances in which kitten is trying to lock access to a Wraith Scheme object that is already locked, and has remained locked for a worrisome amount of time. The "worrisome amount of time" is guaranteed to be at least 0.01 seconds, but may be longer, depending on the speed of your Macintosh and on what else -- other than Wraith Scheme -- it is doing.
This procedure does not apply to locks of bins of the hash tables used to control access to Wraith Scheme's oblist and top-level environment.
If the kitten whose kitten number is passed to the procedure has been trying to obtain access to a locked object for more than the "worrisome amount of time" just described, this procedure will cause it to give up trying, print out some information about what it was attempting to lock, and reset to top-level.
This procedure may be applied to any kitten and called from any kitten.
This procedure is dangerous, because release of deadlocks may cause Wraith Scheme to crash or hang.
Once again, by analogy with medical practice, this procedure is a post-mortem diagnostic tool, not a cure for the patient.
The names of those six files are:
Do not delete or modify any of these files while Wraith Scheme is running! Doing so will cause Wraith Scheme to crash.
In normal operation, Wraith Scheme will remove these files when the MomCat exits, for there is then no further need for them. If Wraith Scheme should crash, or otherwise exit abnormally, the files may escape deletion. When Wraith Scheme is not running, you may safely remove any of these files that you find, if you wish. Wraith Scheme will in any case delete any old copies of the files that it finds, the next time it starts up.
The total size of these six files is somewhat more than twice as large as the amount of memory that Wraith Scheme uses for Scheme memory.
The seventh auxiliary file is in the "/tmp" directory: It is
This file will only exist if Wraith Scheme needs to write something into it. Delete it if you wish -- Wraith Scheme will recreate it if need be. If you encounter any bugs in Wraith Scheme, and this file seems to contain anything useful in diagnosing them, please include a copy of it with any bug report you send to me.
There are a couple of optimization techniques involving Wraith Scheme's parallel processing capability, that you might want to know about.
First, the locking mechanisms that maintain the integrity of Wraith Scheme main memory when several processes are active, are disabled when you start up Wraith Scheme with just the MomCat. The locking mechanisms are intrinsically slow, so if you only need to run code in one Wraith Scheme window, your Scheme programs will run faster if you start up Wraith Scheme to use only one process.
Second, items in Wraith Scheme main memory can be read faster when they are being read by the Wraith Scheme process that most recently used them -- that is, the process that has most recently read, written or modified them -- than when they are being read by some other Wraith Scheme process. Thus for example, it makes sense to load files, create top-level data items, and do compilations, in the Wraith Scheme window that will most often use the code and data items thereby created, and it makes sense to perform repeated calculations on a single data structure in a single Wraith Scheme process.
Third, with an eye toward the day when Non-Uniform Memory-Access (NUMA) computers become more common, Wraith Scheme's garbage-collection mechanism attempts to group items in Wraith Scheme main memory according to which Wraith Scheme process has most recently used them -- that is, the process that has most recently read, written or modified them. The assumption here is that a process that has recently used a particular item is likely to use it again: Thus, improving the localization of items in Wraith Scheme main memory may allow even a simple NUMA page-placement algorithm to preposition data used by a particular process so that it is close (in the NUMA sense) to where that process is executing, and thereby save memory-access time. At any rate, such is my pious hope. (Note, however, that Wraith Scheme will not break apart a cdr-coded list whose various members have been most recently used by different kittens.)
Fourth, the locking mechanisms that Wraith Scheme uses to protect the integrity of Wraith Scheme main memory are not used for Scheme code which is being run. That is not to say that you cannot modify Scheme code -- lambda bodies, procedure applications, and the like -- for you certainly can, but if one Wraith Scheme kitten attempts to modify code which a different kitten is in the act of running, a crash of one or both kittens is likely.
Wraith Scheme provides some support for logic programming in Scheme along the lines of Friedman, Byrd and Kiselyov, 2005). Wraith Scheme does not include any of the fancy software from this work; that's copyrighted, but I hope there are enough primitives to get you going.
Each of "#u" and "#s" evaluates to itself.
(e::logic-constant? <object>)
There may be more support for logic programming in future releases of Wraith Scheme.
Wraith Scheme provides a specialized non-printing object, "#n", whose printed representation is an empty string, and which furthermore will cause Wraith Scheme's top-level read-eval-print loop to omit printing a newline when #n is the result of the "eval" part of the loop.
"#n" evaluates to itself. To see what "non-printing" means, compare the following examples, in which I have added comments to distinguish what you type at the keyboard from what Wraith Scheme prints at the end of evaluation:
#t ;; You type #t, and then a newline.
#t ;; Wraith Scheme evaluates #t as #t, which it prints, followed by a newline.
#n ;; You type #n, and then a newline, but Wraith Scheme prints nothing.
;; In that last example, Wraith Scheme actually evaluated #n to #n, but
;; that result was not displayed, nor was a newline.
(define x 3) ;; You type this definition, and then a newline.
x ;; Wraith Scheme prints "x", and then a newline
x ;; You type "x", and then a newline.
3 ;; Wraith Scheme prints its value, 3, and then a newline.
x ;; You type "x", and then a newline (again).
3 ;; Wraith Scheme prints its value, 3, and then a newline.
(define y #n) ;; You type this definition, and then a newline.
y ;; Wraith Scheme prints "y", and then a newline.
y ;; You type "y" and a newline, and Wraith Scheme prints nothing.
y ;; You type "y" and a newline again, and Wraith Scheme prints nothing.
I added "#n" primarily as a value to return from interrupt handlers. I had some interrupts that were called frequently but mostly did nothing; I wanted to have them print nothing at all so as not to clutter up log files with repetitive meaningless output. An interrupt handler has to return something to the top-level read-eval-print loop of the kitten which handles it, so a non-printing object was just the thing to use for a returned value.
Note that you can inspect the non-printing object and get a printable result. Thus in the previous example, the input:
(e::inspect y)
produces the output:
0000000000000025-0000000000000004: Peculiar Leaf -- Not a Car #<Non-printing object>
(e::non-printing-object? <object>)
You might consider the 'n' in "#n" to stand for "non-printing" or for "nothing".
Many implementations of programming languages provide an implementation of some kind of "package" system, with the dual goals of not cluttering up the namespace and of providing a sane way to deal with situations when two libraries or other modules of code use the same name for different purposes. Wraith Scheme has such a system, but to skirt possible cognitive dissonance, I have consciously avoided such common names as "use", "require", "import" or "export" for its procedures.
Wraith Scheme's package system comprises some new functions with the following goals:
The user also provides a list of procedures from the file which are to be exported, and optionally renamed. The package procedure installs them in the appropriate environment.
There are two top-level procedures for load and export. I will also describe one lower-level procedure that is used as a primitive in the source code for the top-level ones.
(c::load-with-environment-list <optional path to file> <environment list>)
This procedure is used as a primitive in constructing the higher-level procedures that follow.
(e::load-and-export-to-top-level <path to file> <list of export descriptors>)
An export descriptor is either the name of a symbol defined in the file, whose value is to be exported to the top-level environment with the same name, or a list of two symbols, the first of which is the name of a symbol defined in the file, and the second of which is the name to be used when exporting it to the top-level environment.
(e::load-and-export-to-calling-environment <path to file> <list of export-descriptors>)
An export descriptor is either the name of a symbol defined in the file, whose value is to be exported to the calling environment with the same name, or a list of two symbols, the first of which is the name of a symbol defined in the file, and the second of which is the name to be used when exporting it to the calling environment.
(define (foo-internal) (display "This is foo-internal.\n"))
Suppose we evaluate the following expression at top level:
(e::load-and-export-to-top-level "SimplePackage.s" '((foo-internal foo)))
We will then find that if we evaluate "(foo)" at top level, we see the message "This is foo-internal." Thus the procedure "foo-internal" from "SimplePackage.s" has indeed been exported, but renamed to "foo". If we try to evaluate "(foo-internal)" at top level, we will find that no binding of "foo-internal" exists at top-level.
Alternatively, suppose we had evaluated:
(e::load-and-export-to-top-level "SimplePackage.s" '(foo-internal))
In that case, "SimplePackage.s" would have exported its binding of "foo-internal" to top level, but still named "foo-internal".
Now suppose that file "ComplexPackage.s" contains:
(e::load-and-export-to-calling-environment "SimplePackage.s" '((foo-internal foo))) (define (bar-hidden) (foo) (display "This is bar-hidden\n"))
File "ComplexPackage.s" is set up to import "SimplePackage.s" and use one of the latter's definitions -- "foo-internal" renamed to "foo". We might then load "ComplexPackage.s" into top level by evaluating
(e::load-and-export-to-top-level "ComplexPackage.s" '((bar-hidden bar)))
We would then find that if we evaluated "(bar)" at top level, we would get two messages, first "This is foo-internal", and then "This is bar-hidden", while the only new symbol defined at top level would be "bar".
You may nest packages arbitrarily in this manner.
This subsection describes some of the procedures and special forms that are present in Wraith Scheme, that are not part of the R5 standard. I have by no means described all such extras: If you explore the system with the various low-level inspection tools described herein, you will find many procedures I do not mention. I am not trying to keep secrets: Rather, I have described only those enhancements that seem stable enough to use in your own code. The ones not described may change in detail or disappear entirely in future releases of Wraith Scheme.
All the global symbols that I have used in constructing these enhancements start with either "e::" ('e' for enhancement) or with "c::" ('c' for compiler). To avoid naming conflicts with present and future enhancements, please do not create global symbols that start with either of these trios of characters.
And please be wary about using any "c::" procedures in your own code. Some will cause a crash -- Wraith Scheme will cease to operate -- if misused.
There are several procedures which allow direct manipulation of the individual bits of a 64-bit fixnum.
(e::bit-and <integer> <integer>)
(e::bit-not <integer>)
(e::bit-or <integer> <integer>)
(e::bit-xor <integer> <integer>)
Returns the bit-by-bit Boolean exclusive "or" of the arguments.
(e::bit-shift-left <integer> <integer>)
(e::bit-shift-right-arithmetic <integer> <integer>)
(e::bit-shift-right-logical <integer> <integer>)
See Long Ratnums and Continued Fractions.
In the past, there has been considerable controversy in the Scheme community concerning what "eval" ought to do, and whether it even ought to be part of the Scheme language at all. It took a long time for people to agree on the definition of "eval" used in R5 Scheme. Some of the procedures listed here predate that agreement and remain for backward compatibility. Some are low-level procedures used by various Wraith Scheme enhancements, and are mentioned here in case you wish to use them as primitives in your own work.
(e::cons-with-continuation <object>)
This procedure is left over from older releases of Wraith Scheme, that did not implement the "R5" Scheme standard. That standard has an "eval" procedure, which Wraith Scheme now supports. Yet "e::cons-with-continuation" is still there, in case anyone wants to use it.
Many Lisps would call this procedure "eval". It causes its argument to be evaluated in the same environment as that in which "e::cons-with-continuation" itself was called.
Thus:
(e::cons-with-continuation '(+ 2 2)) ;; ==> 4 (define b 3) ;; ==> 3 (define a 'b) ;; ==> a (e::cons-with-continuation a) ;; ==> 3
What is going on in that last example is that when you type
(e::cons-with-continuation a) ;; ==> 3
the reader gets 'a, and the usual practice of evaluating the arguments to a procedure before calling it means that what is passed to "e::cons-with-continuation" is b. Procedure "e::cons-with-continuation" thus pushes b onto the next-to-be-evaluated end of the continuation, whereupon it is immediately evaluated to 3, which is what the top-level read-eval-print loop prints out.
The main use of "eval" and similar features is a bit more complicated, however: One typically builds up the argument to be passed to eval a piece at a time, often in quite distinct and changing environments, then evals it all at once:
(define to-be-evaled '()) (set! to-be-evaled (cons 'operator to-be-evaled)) (define x 42) (define y 88) (set-cdr! to-be-evaled (list 'x 'y)) (define x 2) (define y 2) (define operator +) to-be-evaled ;; ==> (operator x y) (e::cons-with-continuation to-be-evaled) ;; ==> 4
In contrast, suppose we had slightly changed the line containing "set-cdr!" ...
(define to-be-evaled '()) (set! to-be-evaled (cons 'operator to-be-evaled)) (define x 42) (define y 88) (set-cdr! to-be-evaled (list x y)) ;; NOTE: No quotes. (define x 2) (define y 2) (define operator +) to-be-evaled ;; ==> (operator 42 88) (e::cons-with-continuation to-be-evaled) ;; ==> 130
(e::push-list-into-continuation <proper-list>)
This procedure pushes the items of a list, one at a time, cdr end first, into the continuation. It isn't the same as repeated application of "e::cons-with-continuation" (discussed immediately above), because none of the items pushed gets popped from the continuation until "e::cons-with-continuation" itself has completed execution.
Since items of the list are pushed into the continuation cdr end first, they come out of the continuation in the order in which they appeared in the original list.
(c::eval-in-environment <thunk> <environment-list>)
This procedure is a generalization of the standard R5 Scheme "eval" procedure. The latter allows evaluation only in a particular set of environments; the present procedure allows evaluation in any Wraith Scheme environment list. For a precise discussion of what is meant by an environment list, see the section on "Environments" in the Wraith Scheme Dictionary.
(c::symeval <symbol>)
(c::symeval-in-environment <symbol> <environment-list>)
This procedure is a specialization of "c::eval-in-environment", described above: Its first argument must be a symbol, and its second a Wraith Scheme environment list. For a precise discussion of what is meant by an environment list, see the section on "Environments" in the Wraith Scheme Dictionary.
(e::current-directory)
Returns a string that is the full pathname of the "current directory", which is where Wraith Scheme operations look for files when you do not provide a complete pathname. The last character in the string returned will be a '/'.
(e::error-port)
This procedure allows you to write your own error handlers that send messages to the same port that Wraith Scheme uses.
(e::file-exists? <string naming a file>)
The name of this procedure is slightly misleading, in that it is possible that the named file may exist but not have appropriate Unix permission settings for reading by the current user of Wraith Scheme. In that case, the procedure will return #f.
There is no way to tell whether a returned value of #f means that the file does not exist, or that some directory along the path does not exist, or that there is some other problem: The procedure returns #f if for any reason it cannot find the indicated file, or cannot open it for reading.
This procedure closes any file that it opens.
(e::program-directory)
Returns the path to the directory containing the Wraith Scheme application itself; that is, a Unix path that starts with "/" and ends just before the name "Wraith Scheme.app". The last character in the string returned will be a '/'.
(e::set-current-directory! <string naming directory>) (e::set-current-directory!) ;; With no argument, uses a dialog.
Changes the "current directory" to the directory whose pathname (full or partial) is given by the string. Appends a '/' to the pathname, if the pathname does not already end in a '/'. Returns the pathname, as a string. Reports an error when the string is not a valid pathname (full or partial) to a directory. The "current directory" is where Wraith Scheme operations look for files when you do not provide a complete pathname.
(e::startup-directory)
(e::transcript-on-append)
R5's regular "transcript-off" stops the use of any transcript file that is open.
(e::nan? <object>)
(e::inf? <object>)
(e::inspect <object>)
Displays some useful information about the <object> and returns the <object>. Just what is displayed depends on what the <object> is. The fact that "e::inspect" returns its argument means that you can generally wrap a call to "e::inspect" around any expression in a Scheme program, to see what is going on, without otherwise interfering with the operation of the program.
(e::inspect-world <string naming a file>) (e::inspect-world)
Assumes that the string is a path to a Wraith Scheme world file, and on that basis, attempts to open the world file and examine its contents, without actually making the file become the world in use by Wraith Scheme. Reports an error if there is insufficient memory to load the file, and may cause Wraith Scheme to fail and quit if the file is not actually a Wraith Scheme world.
If no file name is given, puts up a standard dialog box for selecting a file to inspect.
(e::coerce-to-long-ratnum-if-possible <real>)
(e::coercible-to-fixnum? <object>)
(e::coercible-to-long-ratnum? <object>)
(e::continued-fraction-list->real <list of integers>)
(e::derationalize <real number>)
(e::long-ratnum? <object>)
(e::make-long-ratnum <integer> <integer>)
(e::real->continued-fraction-list <real>)
In addition to the "hygienic" macro implementation described in the R5 report, Wraith Scheme provides a "lower-level" macro implementation, that is more like the macro implementations in older forms of Lisp.
Besides, several key elements of Wraith Scheme are written as Scheme macros using the older macro implementation.
(e::expand-macro <macro>)
(e::macro? <object>)
(e::macro <symbol> <expression>)
(e::macro-body <expression>)
(e::macro <symbol> <expression>)
is equivalent to
(define <symbol> (e::macro-body <expression>))
Wraith Scheme implements this older form of macros in a rather conventional way. I will first describe this facility simply, glossing over some technical points, and will then fill in the details.
To begin, "e::macro" resembles "define": The action of
(e::macro <symbol> <expression>)
is to evaluate the <expression>, to declare that whatever the evaluation returns is a macro, and finally to bind that macro to the <symbol>.
The action of "e::macro-body" more nearly resembles the evaluation of a lambda expression: That is, the action of
(e::macro-body <expression>)
is merely to evaluate the <expression> and declare that whatever the evaluation returns is a macro.
There is one catch: The final action of the <expression> must be to evaluate a lambda expression of one argument, so that the procedure thereby created is the value that will become the macro. Wraith Scheme reports an error if the value of the <expression> is not a procedure that was derived from a lambda expression of one argument.
A macro is invoked, or "called", by evaluating a pair whose car evaluates to a macro. That is, if you have defined
(e::macro my-macro ...)
then you may invoke my-macro as
(my-macro <stuff>)
The action of such a call is (1) to pass the entire pair -- in this case "(my-macro <stuff>)" -- to the procedure associated with the macro; whereupon (2) that procedure does whatever it is supposed to do, to the pair; and (3) the result returned by that procedure is itself evaluated.
Here is a simple example. Suppose you are tired of writing assignment statements in the form "(set! foo bar)", and would rather write them as "(assign bar to foo)" Define the macro:
(e::macro assign (lambda (form) `(set! ,(cadddr form) ,(cadr form))))
You can then write
(define foo #f) ;; ==> foo (define bar 3) ;; ==> bar (assign bar to foo) ;; ==> foo
The last expression assigns bar, which evaluates to 3, to foo. Now
foo ;; ==> 3
Let's look closely at how that works. The macro call "(assign 3 to foo)", causes the entire expression, "(assign 3 to foo)" to be passed as the argument "form" to "(lambda (form) `(set! ,(cadddr form) ,(cadr form))))". That procedure returns a list whose first element is "set!", whose second element is the cadddr of the form (namely the symbol "foo"), and whose third element is the cadr of the form, namely the number 3. That list, "(set! foo 3)" is in turn evaluated, causing 3 to become the value of foo.
You can see what is happening by evaluating
(e::expand-macro '(assign 3 to foo)) ;; ==> (set! foo 3)
This expression causes only the first two parts of the macro call "(assign 3 to foo)" to take place: It returns the unevaluated result from the procedure, namely the list "(set! foo 3)".
If you want to see the lambda expression itself, instead of what happens when you apply it, use "e::inspect". When you enter
(e::inspect assign)
Wraith Scheme prints some information about where in Scheme memory the macro is located, then prints the lambda expression itself, though not as nicely pretty-printed as I have provided it here.
(lambda (form)
(quasiquote (set! (unquote (cadddr form))
(unquote (cadr form)))))
Note in passing that "assign" is not a very well-behaved macro. For simplicity, it does not include various tests for syntax errors. A better version would have a lambda expression that checked that "form" was a list of exactly four elements, that the third element was the symbol "to", and that the fourth element was a symbol.
The matter I have glossed over is what environments the various evaluations take place in. (Many people find the subject of environments confusing: You need not worry too much about this matter at first, though it may come back to haunt you if you become a serious Scheme enthusiast.)
Briefly, the expansion of a macro -- that is, the evaluation of the procedure of one argument that is assigned to the macro name -- takes place in the lexical scope of the macro definition; but the second evaluation, of whatever expression the expansion returns, takes place in the lexical scope of the macro call.
Here is an example that may make this issue clearer. Maybe ...
First, let's define a global variable, named "my-variable", whose value is the symbol "global-value".
(define my-variable 'global-value) ;; ==> my-variable my-variable ;; ==> global-value
Now let's create a macro named "foo", whose body contains several instances of the symbol "my-variable".
(e::macro foo
(display "Defining foo -- my-variable is ")
(display my-variable)
(newline)
(lambda ( the-argument-is-not-used )
(display "Expanding foo -- my-variable was ")
(display my-variable)
(display " in the environment where foo was defined.")
(newline)
(display "In the present environment my-variable is ")
'my-variable))
As "foo" is being defined, the first two "display"s and the subsequent "newline" are evaluated, so that what appears in the Wraith Scheme window is
Defining foo - my-variable is global-value foo
The "display"s printed the value of "my-variable" in the environment where foo was defined; that value was still "global-value". The lambda expression was then converted into a procedure, which became the value of "foo", which was returned and displayed at top level. The procedure uses "my-variable" in the fifth-from-last line of its definition, in "display". The value of "my-variable" so referenced is again from the environment in which "foo" was defined. So when "foo" is called, it will print (reformatted here to make the lines shorter):
Expanding foo -- my-variable was global-value in the environment where foo was defined.
before the lambda expression returns any value.
The value returned by the lambda expression is a quoted symbol, "'my-variable", and that leading quote is a key to understanding what happens next. This expression will be evaluated in the environment in which the call to "foo" took place. In that environment, "my-variable" will not necessarily have the same value that it did in the environment where "foo" was defined. Thus after the return value has itself been evaluated, it will become
"In the present environment my-variable is <?>"
We don't now know for sure what the "<?>" will be.
To continue the example, let's create a local environment in which "my-variable" has as value the symbol "local-value", and call "foo" in that environment. We might evaluate
(let () (begin (define my-variable 'local-value) (foo)))
What gets printed is, after reformatting it to make the lines shorter:
Expanding foo -- my-variable was global-value in the environment where foo was defined. In the present environment my-variable is local-value
(e::all? <list>)
(e::any? <list>)
(e::atom? <object>)
(e::closed-port? <object>)
(e::fixnum? <object>)
(e::float? <object>)
These formats can represent integers, rationals which are not integers, IEEE nans and IEEE infinities. Wraith Scheme finds occasion to use IEEE formats for all of these entities.
(e::forced? <object>)
(e::long-complex? <object>)
(e::promise? <object>)
(e::deep-copy <object>)
(e::error <string>)
(e::warning <string>)
(e::gensym)
(c::load-from-string <string>)
(e::make-integer-range <integer> <integer> <nonzero integer>)
(e::make-integer-range 0 10 1)
returns (0 1 2 3 4 5 6 7 8 9).
(e::original-cwcc <object>)
(e::read-string-with-prompt <string>)
(e::reduce <binary-operation> <list> [<start-value>])
(e::reduce + (list 2 3 4 5) 42)
calculates ((((42 + 2) + 3) + 4) + 5), which is 56.
(e::select <predicate> <list> [<key>])
(e::select positive? '(1 -1 0 2 -2 3 -3)) ;; ==> (1 2 3)
but
(e::select positive? '((a 1) (b -1) (c 0) (d 2) (e -2) (f 3) (g -3) ) cadr) ;; ==> ((a 1) (d 2) (f 3))
Thus for example, the list elements may be some sort of structure, and the <key> gives you the chance to pull out a particular part of the structure for testing by the <predicate>: In the case just shown, the structure is a list of two items, and the particular part is the second item.
You could always do the same thing by using a specialized lambda expression for the <predicate>, but sometimes using the <key> makes things clearer.
(e::system <string>)
(e::system "cal > ~/calendar.out")
puts a calendar for the present month in a file called "calendar.out" in your home folder.
This procedure is very powerful; it is a doorway into the capability of the the entire Unix system. Unfortunately, there is no easy way to obtain the details of what happened, other than recording them to a file (as in the example just given) for subsequent examination.
(e::time)
(e::usleep <integer>)
Only the part of Wraith Scheme that reads, evaluates, and prints Scheme expressions is put to sleep by this command. Wraith Scheme will respond to many user actions while sleeping; for example, changes in window size. Actions that would cause the processing of Scheme expressions will not take place until Wraith Scheme has waked up, and may block other user actions until wake-up has taken place.
In principle, calling "e::usleep" with a sufficiently large argument could cause Wraith Scheme to sleep for an objectionable length of time. Users of this command might well learn how to force Wraith Scheme to quit by asking the Macintosh Finder to assist: Hold the "ctrl" key down while clicking on the Wraith Scheme icon in the Dock.
(e::version)
Wraith Scheme implements the procedures "values" and "call-with-values", as described in the "R5" report. The implementation features an additional kind of Scheme object, which I have unimaginatively labeled a "multiple values return". The intended use of these objects is to pass data between "values" and "call-with-values", but if you should happen to call "values" in some context other than providing input to "call-with-values", you might encounter one. Thus, for example, at top level:
(values 2 3 4) ;; ==> #<Multiple Values Return> List of values: (2 3 4)
Furthermore:
(e::multiple-values? <object>)
Straight R5 Scheme provides no convenient way to format numbers in varying ways without writing a lot of code on your own. Wraith Scheme has a few enhancements to do some of the common formatting tasks, and perhaps to make it easier to create your own code to do more such tasks.
The interface is built on a single low-level procedure, which uses the numeric formatting capabilities of the underlying C++ implementation in which Wraith Scheme is written. (I do not propose to tell you how to do numeric formatting in C in this document, since there are plenty of widely available sources that do a better job of that than I could. For example, try typing "man printf" in a Unix shell, such as the Macintosh "Terminal" application.)
The low-level procedure is:
(c::number->string-with-c-format <number> <string>)
snprintf( scratch, 256,
<your number coerced to double>,
<your format string>)
in which "scratch" is a pointer to a buffer containing 256 characters. Following this C++ call, the content of "scratch" is again copied into a newly-allocated string in Wraith Scheme's main memory, so there is no need to worry about saving "scratch" or overwriting it.
Note that "c::number->string-with-c-format" does no checking whatsoever of whether its "string" argument is appropriate for use as a C++ "format" string. Thus there is a noteworthy probability that ill-considered use of this procedure may cause Wraith Scheme to crash. This procedure is perhaps best used as a primitive for procedures which are themselves well tested and debugged.
Thus for example:
(c::number->string-with-c-format 1 "%.3f") ;; ==> "1.000" (c::number->string-with-c-format 29.95 "For the low, low price of only $%.2f!!") ;; ==> "For the low, low price of only $29.95!!"
There are two additional procedures which operate at slightly higher level:
(e::number->string-with-n-decimals <number> <number>)
For example:
(e::number->string-with-n-decimals 1/3 3) ;; ==> "0.333" (e::number->string-with-n-decimals (- (/ 1000 3)) 6) ;; ==> "-333.333333"
(e::money->string <number>)
(e::money->string 29.95) ;; ==> "29.95"
If only one value will ever be bound or assigned to a particular symbol, you can speed up the operation of both interpreted and compiled code by making that symbol "permanent". You can reverse the process later, if necessary; but if you do, be sure to recompile any compiled expressions that use the symbol: Otherwise, strange things may happen. It is possible -- though perhaps not useful -- to make permanent a symbol that already has different values bound to it in different scopes.
Wraith Scheme will report an error if you attempt to bind or to assign a value to a permanent symbol.
Most of the symbols that denote the built-in primitive operations of Wraith Scheme are permanent. These symbols include "+", "car", "if", "call-with-current-continuation" and so on.
(e::set-permanent! <symbol>)
(e::clear-permanent! <symbol>)
(e::permanent? <symbol>)
The folks at MIT's project MAC, who wrote the original "MACLisp" (a 1970's-vintage Lisp that ran on mainframe computers, not -- as you might suppose from the name alone -- a Lisp for the Macintosh) issued special error messages if you tried to alter the values of T and nil in that system. They were:
VERITAS AETERNA -- do not setq T! NIHIL EX NIHIL -- do not setq nil!
They had the right idea. (Welcome to the twilight zone -- a CalTech graduate -- me -- just said something complimentary about MIT.)
Perhaps you can figure out how I know about those error messages ...
Elsewhere herein I tell how, in the early stages of development of Pixie Scheme -- Wraith Scheme's predecessor -- I accidentally managed to create nearly nine billion separate and operationally inequivalent kinds of truth and falsehood.
I have occasionally wondered whether Jeff Raskin deliberately spelled "Macintosh" the way he did in order to include a subtle reference to project MAC. Or maybe he just thought somebody was all wet and needed a raincoat.
Eight procedures deal with parameters that control how much of a complicated list or vector gets printed, and thereby incidentally prevent Wraith Scheme from entering an infinite loop when asked to print a circular data structure. There are four such parameters, but their values are not directly available: You must use the functions to manipulate them. One parameter limits the number of elements of a list that will be printed. If this parameter is 3, then '(1 2 3 4 5) will print as
(1 2 3 ...)
The second parameter similarly limits the number of elements of a vector that will be printed.
The third parameter limits the depth of nested lists that will be printed. If that parameter is 3, then '(((((foo))))) will be printed as
(((...)))
The fourth parameter similarly limits the depth of nested vectors that will be printed.
(e::list-print-depth)
(e::list-print-length)
(e::vector-print-depth)
(e::vector-print-length)
(e::set-list-print-depth! <positive integer>)
(e::set-list-print-length! <positive integer>)
(e::set-vector-print-depth! <positive integer>)
(e::set-vector-print-length! <positive integer>)
Two procedures provide access to a quite good Unix random number implementation:
(e::random)
(e::srandom <integer>)
See the Unix documentation for details of "random" and "srandom".
One procedure provides simple access to the Macintosh's built-in speech-synthesis capability.
(e::string->speech) ;; With no argument, uses a dialog. (e::string->speech <string>)
Five procedures deal with sorting and merging. These provide similar functionality to that in Scheme SRFI 95, which is on line at http://srfi.schemers.org/srfi-95/srfi-95.html as I write these words. (SRFI means "Scheme Request For Implementation", and refers to a large body of code specifications which the Scheme community has decided would be useful if generally available.) I cannot implement that SRFI precisely because it depends on another SRFI which I have not implemented, but I chose to provide similar functionality.
The merge and sort procedures are stable when used with comparison predicates that return #f when applied to identical arguments.
See the source code file "SortMerge.s", which is provided as part of the open-source distribution of Wraith Scheme and Pixie Scheme III, for details of the origin and copyright of the source code for these functions. In essence, much of that code derives from the work of Aubrey Jaffer, and is in public domain.
(e::merge <list> <list> <comparison procedure> [<key>])
Without the optional <key>, merges in sorted order, two lists which have already been sorted using the <comparison procedure>. That procedure might descriptively be named "less?", and is presumed to accept two arguments and to return a boolean value indicating whether the first argument is "less" than the second. For example:
(e::merge (list 1 3 5) (list 2 4) <) ;;==> (1 2 3 4 5)
If the optional <key> is present, then the procedure for deciding which of two elements is less, during both the initial sorts of the separate lists and the merge itself, is that the <key> is first applied to the elements being compared, and then the <comparison procedure> is applied to the results thereby obtained. A common use of the <key> is if the elements being compared are some kind of structure, such as a list or vector, and the "less?" procedure is intended to apply to only one element of the structure. For example, if the lists are themselves composed of two-element lists, and the desired comparison is based on the second elements of those lists, then the <key> "cadr" could be used to extract the second elements for comparison. For example:
(e::merge (list '(a 1) '(b 3) '(c 5)) (list '(d 2) '(e 4)) < cadr) ;;==> ((a 1) (d 2) (b 3) (e 4) (c 5))
You could always do the same thing by using a specialized lambda expression for the <predicate>, but sometimes using the <key> makes things clearer.
(e::merge! <list> <list> <comparison procedure> [<key>])
(e::sort <list or vector> <comparison procedure> [<key>])
Without the optional <key>, uses the <comparison procedure> to decide how to sort. That procedure might descriptively be named "less?", and is presumed to accept two arguments and to return a boolean value indicating whether the first argument is "less" than the second. For example:
(e::sort (vector 2 3 1) <) ;;==> #(1 2 3)
If the optional <key> is present, then the procedure for deciding which of two elements is less is that the <key> is first applied to the elements being compared, and then the <comparison procedure> is applied to the results thereby obtained. A common use of the <key> is if the elements being compared are some kind of structure, such as a list or vector, and the "less?" procedure is intended to apply to only one element of the structure. For example, if the lists are themselves composed of two-element lists, and the desired comparison is based on the second elements of those lists, then the <key> "cadr" could be used to extract the second elements for comparison. For example:
(e::sort (list '(a 2) '(b 3) '(c 1)) < cadr) ;;==> ((c 1) (a 2) (b 3))
You could always do the same thing by using a specialized lambda expression for the <predicate>, but sometimes using the <key> makes things clearer.
(e::sort! <vector> <comparison procedure> [<key>])
(e::sorted? <list or vector> <comparison procedure> [<key>])
Without the optional <key>, uses the <comparison procedure> as the basis for deciding whether one element is less than another. That procedure might descriptively be named "less?", and is presumed to accept two arguments and to return a boolean value indicating whether the first argument is "less" than the second. For example:
(e::sorted? (vector 1 2 3) <) ;;==> #t
If the optional <key> is present, then the procedure for deciding which of two elements is less is that the <key> is first applied to the elements being compared, and then the <comparison procedure> is applied to the results thereby obtained. A common use of the <key> is if the elements being compared are some kind of structure, such as a list or vector, and the "less?" procedure is intended to apply to only one element of the structure. For example, if the lists are themselves composed of two-element lists, and the desired comparison is based on the second elements of those lists, then the <key> "cadr" could be used to extract the second elements for comparison. For example:
(e::sorted? (list (c 1) (a 2) (b 3)) < cadr) ;;==> #t
You could always do the same thing by using a specialized lambda expression for the <predicate>, but sometimes using the <key> makes things clearer.
Several procedures allow Scheme programs to examine and modify the internal flags that control whether defines are compiled automatically, and whether the display routines for numbers use the full precision available.
(e::set-compiler-on!) (e::clear-compiler-on!) (e::compiler-on?)
(e::set-show-full-precision!) (e::clear-show-full-precision!) (e::show-full-precision?)
(e::active-room)
(e::active-store-size)
(e::aging-room)
(e::full-gc)
The speed of garbage collection will vary from fast -- when the Wraith Scheme main memories are contained entirely within physical memory chips -- to very slow -- when the Wraith Scheme main memories are in part stored as virtual memory, on disk. It takes a long time to "swap"; that is, to move data back and forth between disk and physical memory. On a 2006 model Macbook, with a 2 GHz Intel Core Duo processor and 1 GByte of memory, with no other user processes but Wraith Scheme running, with a Wraith Scheme main memory size of nearly 1 GByte, with a substantial portion of main memory containing non-garbage, I have seen garbage collection take as long as twenty minutes.
Newer Macintosh computers are more powerful, but Wraith Scheme can use that power, so garbage collection still can take lots of time. On a Mac Mini with an 8-core Apple M1 processor and 8 GB of memory, with no other user processes but Wraith Scheme running, with a Wraith Scheme main memory size of 64 GByte, I have seen garbage collection take as long as half an hour.
(e::ninety-percent-used?)
(e::room)
(e::show-room)
(e::store-size)
This section deals with procedures that allow examination or modification of some of the internal data structures used by Wraith Scheme. Abuse of some of these functions will cause fatal errors, crashes and other disasters. Detailed description of these data structures is beyond the scope of this help file; however, experienced Lisp programmers will know what I am talking about.
(e::bound-instance? <symbol>)
(e::get-tag <object>)
(e::set-tag! <object> <integer>)
(e::show-active-memory)
Fair warning: This procedure can generate enormous amounts of output.
(e::show-aging-memory)
Fair warning: This procedure can generate enormous amounts of output.
(e::show-dynamic-environment-list)
(e::show-environment)
(e::show-environment-list)
(e::show-memory)
Fair warning: If you call this procedure when Wraith Scheme is using a large main memory -- say a gigabyte -- and if that memory is full, or nearly so, the procedure may well attempt to generate hundreds of millions of lines of output.
(e::show-stack)
(e::stack-depth)
(e::write-continuation)
(e::write-stack)
Several procedures allow top-level control of the operation of the Wraith Scheme application:
(e::exit)
In Wraith Scheme parallel processing, the MomCat is essential: Thus when you terminate the MomCat by any of these means, Wraith Scheme will also terminate all other Wraith Scheme processes -- all the kittens -- that are running. That is, in the MomCat, "e::exit", the "Quit" command, the "Quit" menu item, and the little red dot all act as global "kill" commands for all Wraith Scheme processes that you are running.
When you use the "Quit" command or menu item, or click on the "close window" widget, Wraith Scheme will ask you to confirm that you really want to exit. (Otherwise a simple error -- perhaps accidentally picking the wrong menu item, could lose of a lot of work.) But when you evaluate "(e::exit)" in the Wraith Scheme window, or in a program, there will be no dialog, the program will just quit.
(e::reset)
Stops whatever Wraith Scheme is doing, and returns control to you. You can also invoke the "e::reset" procedure from the "Reset to Top-Level Loop" menu item or the corresponding keyboard command, "option-shift-command-delete". If Wraith Scheme is doing the "wrong thing" -- perhaps a program has entered an infinite loop -- the keyboard and menu commands will force execution to halt. Within a Scheme program, "e::reset" is useful for error handling, as a way to stop execution without returning some kind of error flag back through many procedure calls.
(e::set-input-port!) ;; With no argument, uses a dialog. (e::set-input-port! <string with a path to a file>)
"e::set-input-port!" is a procedure that only a developer could love. It makes a permanent change in where the system gets its top-level input. Its intended use is in testing error-handling, in the following way: When "e::reset" is evaluated, it normally returns control to the Wraith Scheme window, so that the next input to Wraith Scheme after an "e::reset" evaluation is whatever is next typed into the window. But if "e::set-input-port!" has been called, then the next input after the reset will be taken from the port passed to "e::set-input-port!". Thus to perform many tests of a program that calls "e::reset" for error handling, you might create a text file containing those tests, enter Wraith Scheme, open a transcript, and call "e::set-input-port!" with the name of that text file. The tests will start to run, and when "e::reset" is called, Wraith Scheme will perform the next test in the file, instead of returning control to the Wraith Scheme window.
Note that you cannot use "load" instead of "e::set-input-port!" for the same effect: If "e::reset" were called by any of the forms being loaded, then the "load" procedure itself would terminate immediately, and control would return to the Wraith Scheme window.
This procedure will only work correctly when called from top-level; in particular, it will not work when called by code that is being executed via the "load" procedure.
(c::disable-window-output) (c::enable-window-output) (c::window-output-enabled?)
These procedures allow you to control whether Wraith Scheme writes output to the Wraith Scheme window or not. The first two respectively disable and enable that output, the third returns a boolean indicating whether output is enabled or not.
Output to files, including transcript files, is not affected by these procedures. Furthermore, anything you type into the Wraith Scheme Input Panel will be echoed in the Wraith Scheme window, even if window output is disabled.
These procedures use the same mechanism to control window output as does the "Disable Window Output" menu item, in the Interpreter Menu, but the procedures do not cause display of the panel that drops down from the top of the Wraith Scheme window to remind you that output is disabled.
(c::down-in-flames!!!)
I created this procedure so that I could easily test Wraith Scheme's mechanism for reporting fatal errors.
Several procedures allow a Wraith Scheme process to act as a server for Unix sockets.
These procedures have been in Wraith Scheme for some time, but were undocumented earlier: I am by no means a socket wizard, and the procedures are a bit primitive, so it is a bit embarrassing turning them loose. Still, they might be useful for some purposes. For a better socket interface, you might write separate C++ programs to deal with sockets, and use them by way of the Wraith Scheme foreign-function interface.
Detailed discussion of the use of Unix sockets is beyond the scope of the Wraith Scheme help file.
(c::socket-create-and-listen <string-naming-socket> <backlog>)
(c::socket-accept <socket number>)
(c::socket-write <socket number> <string>)
(c::open-input-socket <socket number>)
(c::socket-fgets <input port connected to a socket>)
The Wraith Scheme Sensory Devices Drawer opens on the right side of the Wraith Scheme window. You can open it with an item in the Wraith Scheme Window Menu. That drawer contains a some input devices that you can mouse on in order to communicate with Wraith Scheme: It has five pushbuttons, four sliders, and eight sense switches. Here is an image showing what they look like.
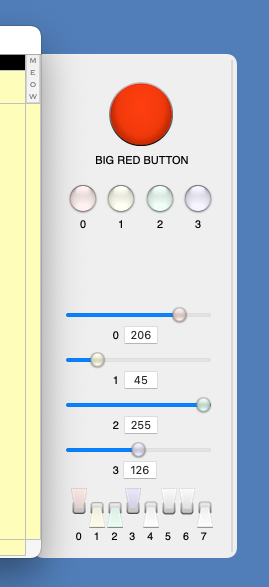
The Sensory Devices Drawer.
All of the items in the Sensory Devices Drawer are input devices. You can push the buttons. You can drag the handles of the sliders to new positions, or type into the little windows associated with the sliders. You can toggle the sense switches up and down. There are Wraith Scheme procedures that allow programs you write to obtain the results of your actions.
The pushbuttons -- both the big red one and the four smaller ones below it -- can be set up to trigger a Wraith Scheme Interrupt when pressed. The pushbuttons have no default actions, though. There are no interrupts yet associated with them when Wraith Scheme starts up. They won't do anything until you arrange interrupts for them, but after you have done so, you can make the code for the interrupt -- the interrupt handler -- run whenever you like, by pushing the button.
In contrast, the sense switches and the sliders are not set up to use interrupts. There are Wraith Scheme procedures that read their values, and your programs may use those procedures at any time, but there is no mechanism for informing a program automatically that the sliders or sense switches have changed. The idea is that you set those items the way you want them, and your program reads them when it reaches a point where it needs their values.
Furthermore, there is no way for a program to move the sliders, or to flip the sense switches up and down. All the items in the Sensory Devices Drawer are input devices only: You use them to provide information or direction to a Wraith Scheme program.
When Wraith Scheme starts running, the sliders are set at zero, and the sense switches are in the "off" position -- which is "down".
There are procedures to obtain the value of each slider and to tell whether each sense switch is on or off. Each slider has a small window below it that shows its numeric value -- an integer in the range [0..255]. The slider setting and the value in the associated small window are connected automatically; no programming is required to make one change when the other does.
Several procedures allow Wraith Scheme programs to access these devices. Example code for how to use the procedures follows the procedure descriptions. Remember that the MomCat and any kittens that may be present all have their own separate sensory devices drawers. Each of these procedures operates on the sensory devices of the Wraith Scheme process where the procedure is executed.
(e::big-red-button-enabled?)
(e::big-red-button-interrupt-number)
(e::disable-big-red-button!)
(e::disable-pushbutton! <pushbutton-number>)
(e::enable-big-red-button! <interrupt-number>)
e::enable-pushbutton! <pushbutton-number> <interrupt-number>)
(e::pushbutton-enabled? <pushbutton-number>)
(e::pushbutton-interrupt-number <pushbutton-number>)
(e::sense-switches)
(e::slider <slider-number>)
Here is some Wraith Scheme source code to demonstrate the operation of all of the sensory input devices just mentioned, as well as the level indicators that are described in the next section. This code will operate when only the MomCat is present. Once it has been executed, the pushbuttons will be set up to trigger interrupts that print messages to the MomCat's window. Every time you execute "test-sliders-et-al", the value of each level indicator will be set to the value of the corresponding slider, and the values of the sense switches will be printed out in binary.
(c::set-interrupt-handler! 42 0
'(display "AIIEEEE!! You pushed the BIG RED BUTTON!\n"))
(c::set-interrupt-handler! 10 0
'(display "You pushed button 0.\n"))
(c::set-interrupt-handler! 11 0
'(display "You pushed button 1.\n"))
(c::set-interrupt-handler! 12 0
'(display "You pushed button 2.\n"))
(c::set-interrupt-handler! 13 0
'(display "You pushed button 3.\n"))
(e::enable-big-red-button! 42)
(e::enable-pushbutton! 0 10)
(e::enable-pushbutton! 1 11)
(e::enable-pushbutton! 2 12)
(e::enable-pushbutton! 3 13)
(define (test-sliders-et-al)
(e::set-level-indicator! 0 (e::slider 0))
(e::set-level-indicator! 1 (e::slider 1))
(e::set-level-indicator! 2 (e::slider 2))
(e::set-level-indicator! 3 (e::slider 3))
(display
(string-append
"Sense switches: "
(number->string (e::sense-switches) 2)
"\n"))
)
The general rule is that all the items in the Wraith Scheme Instrument Panel are output devices: You use Wraith Scheme procedures to set their values, or Wraith Scheme sets them on its own, to provide status information. There is nothing there that you can press, drag, mouse on or type into, to make things happen in a Wraith Scheme program.
If you mouse the bottom of the Wraith Scheme Instrument Panel and pull down -- at the location shown by the arrow in the figure below, or anywhere on the bottom border of the panel ...
Mouse and pull down at the location of the arrow.
... you will find some level indicators hiding above the nominal top of the instrument panel.
The Wraith Scheme Instrument Panel, showing the level indicators at the top.
The level indicators are output devices, whose values are under user control. From the viewpoint of Wraith Scheme, they are output devices -- you cannot read their values by means of Wraith Scheme procedures. Furthermore, there is no way to set their values by touching them or by typing into them; the values can only be changed by Wraith Scheme procedures.
Each level indicator has a small numeric display to its left that shows its numeric value -- an integer in the range [0..1024]. The level indicator setting and the value in the associated numeric display are connected automatically; no programming is required to make one change when the other does. Just as for the sensory input devices, the MomCat and any kittens that may be present all have their own separate level indicators. The procedure to set level indicators affects the level indicators in the Wraith Scheme process where that procedure is executed.
Here is the procedure to set level indicators.
(e::set-level-indicator! <level-indicator-number> <integer>)
At the end of the preceding section is some Wraith Scheme code that demonstrates the operation of the level indicators and the sensory input devices. Here below is a procedure that will make each level indicator continuously display four times the value of the slider that has the same number.
(define (track-sliders) (e::set-level-indicator! 0 (* 4 (e::slider 0))) (e::set-level-indicator! 1 (* 4 (e::slider 1))) (e::set-level-indicator! 2 (* 4 (e::slider 2))) (e::set-level-indicator! 3 (* 4 (e::slider 3))) (track-sliders))
When the procedure is running, you can move the knob of any slider in the Sensory Devices Drawer, and watch the setting of the corresponding level indicator change in real time.
Wraith Scheme provides some "sense lights" -- in effect, light bulbs on the Wraith Scheme Instrument Panel that are under user control. There are eight of them. They are normally invisible and will remain so unless Wraith Scheme procedures are used to make them show up. When they are visible, they are lined up in a row near the top left corner of the Wraith Scheme Instrument Panel, as shown in the next figure, in which one sense light is set to be invisible.
The Wraith Scheme sense light array, with most of the lights visible.
The sense lights are numbered 0 through 7, from left to right. Each sense light may have one of eight illumination states, and those states are also numbered. In illumination state zero, the sense light is turned "off" -- it is visible, but resembles an unilluminated panel light, as in the second light from the right in the preceding figure. Illumination states 1 through 6 correspond respectively to the light being lit with the color red, orange, yellow, green, cyan, or magenta. In illumination state 7, the light is emitting darkness -- it looks like it is glowing black.
The visibility of each sense light has nothing to do with its illumination state. If you make a visible sense light invisible, it retains whatever illumination state it previously had, and will reappear looking just the same after if you should make it visible again. Similarly, if you change the illumination state of a sense light that is invisible, the sense light does not show up -- it won't do that till you make it visible, but when it does it will have whatever illumination state you have just provided.
I did not create names for the separate colors or illumination states; that is, there is no built-in Wraith Scheme object named "e::red" or anything like that. Feel free to define such auxiliaries if you wish.
Procedures for working with sense lights include:
(e::hide-sense-lights!)
(e::rotate-sense-lights! <integer>)
(e::sense-light-number? <object>)
(e::sense-light-illumination-number? <object>)
(e::set-sense-light-illuminations! <sense-light-illumination-state-number>)
(e::set-sense-light-n-illumination! <sense-light-number> <sense-light-illumination-state-number>)
(e::set-sense-light-n-visibility! <sense-light-number> <boolean>)
(e::set-sense-lights-off!)
(e::show-sense-lights!)
There is no way to read the illumination state or visibility of sense lights from Wraith Scheme.
Note that "e::set-sense-light-n-illumination!" and "e::set-sense-light-n-visibility!" provide full control of sense light operation. The other procedures that affect illumination and visibility are for convenience.
Procedures which change the illumination state or visibility of sense lights are relatively slow to execute. When speed is particularly important, make minimal use of sense lights.
One of the source code example files provided via the "Source Code Examples" submenu of the Wraith Scheme Help Menu contains some demonstrations of the sense lights. To open that file in a browser window, use the "Sense Light Demonstration" menu item of that submenu. Cut and paste all the code in the file into Wraith Scheme, then try
(demonstrate-sense-lights)
You might also find
(cylon)
and
(fuzz)
interesting. They are in that same file. The latter two procedures loop forever, so you will have to reset Wraith Scheme to stop them.
Like Common Lisp, Wraith Scheme maintains several variables that may prove handy should you forget to save an interesting input expression or output result. Their names are closely related to the names of similar variables used in Common Lisp.
Common Lisp Wraith Scheme
=========== =============
- >-<
+ >+<
++ >++<
+++ >+++<
* >*<
** >**<
*** >***<
Wraith Scheme cannot use the exact same variable names as Common Lisp, because there is only one namespace in Scheme, and the symbols "+", "-" and "*" are already bound to the procedures for addition, subtraction and multiplication.
If you use Wraith Scheme's parallel processing enhancements, you will find that each kitten has its own variant of these variables. See the parallel-processing section on Keeping Track of Things for details.
When Wraith Scheme starts running, these variables are all initialized to the empty list.
>+< >++< >+++<
>-<
>*< >**< >***<
The utility of these variables somewhat overlaps the utility of the command-history and scrolling mechanisms available in the Input Panel and in the Main Display Panel.
Wraith Scheme has a mechanism to save the entire content of Scheme main memory, and some other things as well, in a special type of file, that may be reloaded into a running Wraith Scheme process at any future time, and reused. Many Lisp implementations provide such a mechanism; the process is traditionally called "saving and reloading a world", and the saved files are traditionally called "worlds".
Mousing on a saved world, or dragging a saved world on top of the Wraith Scheme app icon, will launch Wraith Scheme. Furthermore, it is possible to create stand-alone Wraith Scheme programs, in the form of saved worlds, that will run when you mouse on them, like any other Macintosh application. We will see how to do that in a few paragraphs.
The icon for a Wraith Scheme world looks like this:

The Wraith Scheme world icon, somewhat larger than normal.
A saved world may be used as many times as you wish. Each time you load it, you will get back the state of Wraith Scheme when the world was created.
Saved worlds can be loaded only into the specific version and release of Wraith Scheme from which they were originally saved. Furthermore, it is possible that for some reason a saved world may not "fit" into a particular Wraith Scheme process; for example, the saved world may require more memory or more kittens than the current Wraith Scheme process has. If you encounter such a problem, change the Wraith Scheme "Preferences" to provide more of the missing resource, then restart Wraith Scheme.
You may load and reload any sequence of saved worlds into any running instance of Wraith Scheme, as long as each of them fits, but each time you load a world it will overwrite the entire content of the previous world. There is no way to "merge worlds".
It usually makes sense to save and load worlds only from top-level in Wraith Scheme, not from the middle of programs that are running: A saved world does not preserve the contents of Wraith Scheme's stack or continuation, or any of the other data that would be required to pick up in the middle of an executing program. Thus a saved world contains only a top-level environment: Once that environment is reloaded, you must evaluate an expression manually, or arrange that Wraith Scheme run a procedure automatically upon loading the world, to get things to start happening.
When a world is loaded, Wraith Scheme finds itself running at the top-level loop, even if the world was saved from within a program, or even if you called the procedure to load it from within an executing program.
Wraith Scheme provides a mechanism to store within a saved world a procedure which will automatically be executed at top level immediately after the world is loaded. By using this mechanism, you can make the act of loading a Wraith Scheme world not only load a particular set of procedures and data into Wraith Scheme, but also start something happening: A saved world becomes something like an autonomous Scheme program, which starts running by itself as soon as it is loaded. That mechanism is described below, in the subsection about "e::main".
Saving a world does not cause Wraith Scheme to stop running. You can continue using a Wraith Scheme process after saving a world, just as if you had not saved the world in the first place.
You may load a Wraith Scheme world by using the "Load World" command from the Interpreter Menu, or by using the "e::load-world!" procedure described below.
You may save a Wraith Scheme world by using the "Save World" command from the Interpreter Menu, or by using the "e::save-world" procedure described below.
Procedures associated with Wraith Scheme world operations include:
(e::main)
If you save a world in which "e::main" is a procedure of no arguments, then whenever that world is loaded into a Wraith Scheme process, "e::main" will be executed immediately after the world has loaded. If you are running parallel Wraith Scheme processes -- more than one kitten -- only the MomCat will execute "e::main".
Use of "e::main" makes it possible to start something happening automatically in a newly-loaded world.
Wraith Scheme will report an error if it loads a world in which "e::main" is bound to a lambda expression that requires one or more arguments. The error will be reported after the world load has completed, and the loaded world will then otherwise be ready for use.
If Wraith Scheme loads a world in which "e::main" is bound to a Wraith Scheme object that is not a lambda expression, it will do nothing with the bound value; in particular, it will not evaluate or print out that value. The world load will then be ready for use.
(e::load-world! <string naming a file>) (e::load-world!)
Loads a "saved world" file, which contains most of what was known to Wraith Scheme when the file was created. If no file name is given, puts up a standard dialog box for selecting a file, and also displays a message telling what world was loaded. Returns #t. Returns control to the top-level loop after the world is loaded, even if the procedure was called from deep within another procedure.
This procedure overwrites everything in Wraith Scheme's memory!
In particular, if you load a world from within a Scheme program, the program will stop executing immediately after the load. If you use the "load" procedure to load a file of Scheme code, and that file loads a world, then nothing more will be read from the file after the world load, because the "load" procedure itself will have stopped.
(e::save-world <string naming a file>) (e::save-world)
Creates a special "saved world" file, that contains almost everything known to Wraith Scheme when the file is created. If no file name is given, puts up a standard file dialog box for selecting a file. Returns #t. This procedure does not overwrite any objects.
In computer slang, an "Easter Egg" is a program feature that is cute or useful but perhaps temperamental or obscure. "Obscure" means that the feature is poorly documented or even not documented at all, and is unlikely to be stumbled upon by chance. There are likely to be features that fit this definition in every release of Wraith Scheme, if only for the following reasons:
I may have put in a feature to aid in the development and release process itself -- something that only a developer would love or use.
I may have been working on a new feature, to be explained and documented subsequently, that wasn't quite ready when I decided to release a new version of Wraith Scheme.
I like cute.
You might wonder why I don't just disable such features for a release. The reason is that disabling one part of a program often breaks another. It's kind of like do-it-yourself plumbing repair, or maybe like trying to pull a "loose thread" off a garment you are wearing: The consequences may be disastrous. Wraith Scheme will be much more stable if I just leave such features in.
Anyhow, here are some hints about some -- but not all -- of the Easter Eggs in Wraith Scheme.
Running Wraith Scheme from a Unix Shell:
This feature will make sense only to those of you who know how to use a Unix shell. Furthermore, this feature may not be as useful as you are hoping for: Mostly, it provides a way for Wraith Scheme to load and execute files of Scheme code under control of Unix shell scripts and the like. If that sounds useful, keep reading ...
To run Wraith Scheme from a Unix command line, open a window of the "Terminal" application, and enter the path to the Wraith Scheme executable. The problems are finding the actual executable, and figuring out how to use a Unix path that contains blank spaces. Let me remind you how to do those things.
The actual Unix executable for Wraith Scheme is buried deep within the "application" -- the thing with the Wraith Scheme icon -- that shows up in Macintosh Finder windows. (That's how Macintosh applications work, it's not just something weird that I put in.) For example, suppose you have placed the Wraith Scheme application in your "Applications" folder. Then the full path to the Unix executable, presented here with sufficient quotation marks for the Unix shell to understand it, is:
/Applications/"Wraith Scheme.app"/Contents/MacOS/"Wraith Scheme"
So what you would type at the command prompt, in a Macintosh Terminal window, using the default shell, to get Wraith Scheme going, is
/Applications/"Wraith Scheme.app"/Contents/MacOS/"Wraith Scheme"
All that does is start the program going, just as if you had clicked on its icon in the Finder, but there's more: Wraith Scheme has a command-line flag that makes it use the Terminal window for input and output. The flag is "-t". (There are some more flags; I will get to them in a few paragraphs.) At the command prompt, enter:
/Applications/"Wraith Scheme.app"/Contents/MacOS/"Wraith Scheme" -t
The usual Wraith Scheme window will open, but all the text that Wraith Scheme would normally have printed to the Main Display Panel will instead be printed in the terminal window, and instead of entering Scheme commands into the Input Panel you will need to type them into the terminal window.
Unfortunately, the "-t" flag does not quite turn Wraith Scheme into a program that behaves well in a Unix shell. There are several gotchas:
When you start Wraith Scheme from a Unix prompt, you must provide the full Unix path, as shown in the examples above. Relative paths will not work -- Wraith Scheme will run, but it won't be able to find the world that it is supposed to load at startup. (You could load the world yourself, if you wished, but it is probably easier just to type the full pathname.)
Output to the terminal shell will be a bit garbled -- there won't be enough "return" characters sent to the shell for everything to look tidy. The results of running a Scheme command will probably start on the same line where the command ended, instead of starting on a new line.
You will have to use the regular Wraith Scheme window for anything you can't do from the Input Panel. Most notably, that includes resetting to the top-level loop. It also includes any use of the Dialog Panel or the Message Panel.
I created this feature so that I could run Wraith Scheme and load files of Scheme source code from a Unix shell script or makefile. I have thereby automated testing of Wraith Scheme. My test scripts consist of a long series of shell commands or makefile commands that look something like this:
echo "(load <path to a test file>)" | /<path to the executable>/"Wraith Scheme" -t <more flags>
All that does is start Wraith Scheme running, with whatever additional command-line flags are provided, and send it the single command:
(load <path to a test file>)
(Note that the Unix "echo" command adds the necessary "newline".)
My files of test code use the Scheme "transcript-on" and "transcript-off" procedures to record output in a file; those work fine -- output is not garbled -- with the "-t" flag.
Other flags useful in connection with "-t" are:
There is this little panel at the top right corner of the Wraith Scheme window ...
Now and then the Wraith Scheme icon may look a little different ...
Every so often, Wraith Scheme may undertake some harmless cat-like behavior ...
Cats are fond of Roman numerals ...
Long ago, in a Macintosh far, far away ...
"Weasel Scheme" is a simplified variant of Wraith Scheme, that runs on the popular Raspberry Pi 400 computer using the garden-variety Linux that the Raspberry Pi folks recommend. (It may run on other versions of the Raspberry Pi, but I have not tested any.) I provide it as part of the Wraith Scheme distribution, in case anyone happens to need such a thing.
Weasel Scheme uses C++'s standard features to read in Scheme commands and report results. It has a very simple single-character interface for asynchronous commands (like "STOP!!" or "quit"), that you invoke by typing control-C. It has no buttons and menus, makes no use of the mouse, and does not do parallel processing.
To get Weasel Scheme to see "control-C", you must type a carriage return after typing control-C.
All functions that are defined in the macOS implementation of Wraith Scheme are present in Weasel Scheme, but the ones that have to do with the Macintosh version of Wraith Scheme's user interface do not work: They do nothing.
The only current documentation for Weasel Scheme is the documentation for Wraith Scheme that is available on line or within the Wraith Scheme application itself. Just remember that if something mentioned therein doesn't look like it will work in Weasel Scheme, it probably won't.
Weasel Scheme allows very simple editing of the line being input, with a user interface based on the popular "emacs" editor: Control-A, control-B, control-D, control-E, control-F, control-K, control-Y, and the "backspace" character all work as they do in emacs, except that the "kill ring" is only one deep. That is, control-K copies the rest of the current line into a buffer and control-Y types it in again. There is no stack of killed text samples, just the last one killed. The behavior of other characters that might perhaps be expected to affect the text being input, is undefined.
The program responds to the command-tail flag "-h" with a conventional "usage" message.
Weasel Scheme does not do parallel processing -- there is just the MomCat, with no kittens.
Weasel Scheme is rather new, so I would be astonished if there were no problems with it. Send me a bug report when you find some.
Weasel was another cat.
Weasel Scheme has several built-in procedures that allow use of the twenty-seven general purpose input-output pins (gpio pins) that every Raspberry Pi possesses. These procedures are present in the corresponding versions of Wraith Scheme, but have no effect on the hardware of any Apple Macintosh: An attempt to use any of them on a Macintosh results in an error. Hence these procedures are discussed here, instead of in the preceding section on Enhancements.
(e::rpi-gpio-connect)
Procedure e::rpi-gpio-connect simply advises Weasel Scheme of the location in the Raspberry Pi hardware memory map, of the registers used to control the gpio pins, and sets up Weasel Scheme to use those registers. This procedure neither reads nor writes any of the control registers: It does not "touch hardware", it merely makes sure that subsequent procedures correctly address the hardware involved.
(e::rpi-gpio-gpio-display-control-registers)
Procedure e::rpi-gpio-gpio-display-control-registers displays a human-readable display of the content of all of the gpio control registers that the Raspberry Pi uses.
(e::rpi-gpio-display-pin <gpio pin number>)
Procedure e::rpi-gpio-display-pin displays the value and function-select field of the specified Raspberry Pi gpio pin. If the pin to be displayed is pin n, then the value displayed is bit n of control register gplev0.
(e::rpi-gpio-display-pins)
Procedure e::rpi-gpio-display-pins displays the value and function-select field of all Raspberry Pi gpio pins. When the pin to be displayed is pin n, then the value displayed is bit n of control register gplev0.
(e::rpi-gpio-pin-select-field <gpio pin number>)
Procedure e::rpi-gpio-pin-select-field returns the three-bit field that specifies the configuration of the indicated gpio pin; that is, the purpose for which it is configured. Configurations include, but are not limited to, use as a logic-level input, which is indicated by a zero, and use as a logic-level output, which is indicated by a one.
(e::rpi-gpio-set-pin-for-output <gpio pin number> <boolean>)
Procedure e::rpi-gpio-set-pin-for-output sets the direction of the specified Raspberry Pi gpio pin to either "input" or "output". As the procedure name may suggest, the "output" direction is specified by an argument of #t, and the "input" direction by #f.
(e::rpi-gpio-read-pin <gpio pin number>)
Procedure e::rpi-gpio-read-pin reads the logic level from the specified Raspberry Pi gpio pin, provided that the direction of that pin has been set to "input".
(e::rpi-gpio-write-pin <gpio pin number> <zero or one>)
Procedure e::rpi-gpio-write-pin writes the specified logic level to the specified Raspberry Pi gpio pin, provided that the direction of that pin has been set to "output".
I am sure Wraith Scheme contains bugs, and I want to hear about them so that I can fix them.
I am particularly worried about the possibility of bugs that are platform dependent, in that they occur on some combinations of Macintosh hardware and operating system and not on others. I do not have a warehouse full of different Macintosh computers to test Wraith Scheme on, so it is logically conceivable -- and it has in fact happened -- that I might release a version of Wraith Scheme containing a bug that I am not equipped to discover.
So by all means, do send in bug reports.
My EMail address is Jay_Reynolds_Freeman@mac.com.
If you ever encounter a fatal or non-fatal error with a message like
"Implementation error ..."
or
"Implementation: ..."
then I would much appreciate a bug report with as many details as you can provide. (In particular, include the entire message.) Such errors indicate that I have inadequately guarded against some anticipatable problem: It's my fault; I will be eager to do better.
The only reason I will release a distribution of Wraith Scheme containing a known bug or a glaring flaw is that there is some reason I cannot fix the problem. I will risk tempting fate by stating that at present, I have none to report.
Read and Print Overflow:
Although Wraith Scheme can store large and complicated data structures in its main memory, it cannot necessarily read them in all at once: Wraith Scheme can read lists that are very long. In testing, I have loaded files whose text included lists of 100 000 items, something like:
'(item-1 item-2 ... item-99999 item-100000)
However, lists that are too deeply nested will cause Wraith Scheme to crash. Such a list might be
'((( ... ((( some-list-item ))) ... )))
in which the "..." stands for tens of thousands of parentheses of the appropriate kind
There is a similar problem in the routines that print long or deeply-nested lists, but I have not tested to determine its extent.
Quitting When Garbage Collection Is Happening:
Wraith Scheme will crash if a kitten exits while garbage collection is in progress. Therefore, if you try to quit from Wraith Scheme (via the "Quit" menu item and the like) while garbage collection is happening, Wraith Scheme will wait till it has finished before quitting. Normally, that is not a problem, but if you are using a large Scheme memory, it may take a long time before Wraith Scheme actually quits. Worse, if there should be some kind of failure during garbage collection (and that would be a serious bug -- let me know about it if it happens), it may be impossible to quit from Wraith Scheme by the usual means. In that case, remember that Apple provides a "Force Quit" command for every application, which you can find by holding down the "option" key while clicking on the application's icon in the dock.
Numerical Exactness:
Wraith Scheme relies in part upon built-in features of macOS and of Macintosh hardware to determine whether or not the result of a floating-point arithmetic calculation is exact; this term refers among other things to what the standard Scheme procedures "exact?" and "inexact?" return. These built-in features vary in capability from one version of macOS to the next, and from one kind of Macintosh hardware to another.
The main consequence here is that sometimes you might expect that a floating-point calculation would return an exact result, but the procedure "exact?" doesn't say that it did. Furthermore, what "exact?" has to say about the result of any given calculation may vary depending on what kind of Mac and which version of macOS you are running.
This mildly inconsistent behavior is not technically a Wraith Scheme bug, since the R5 standard is rather lenient about requiring Scheme implementations to return exact results whenever possible, but it bugs me, so I thought I would report it here.
Numerical Accuracy:
The floating-point algorithms used by the Macintosh may differ from one version of macOS to the next and also from one kind of processor hardware to the next. Thus the numerical results returned by Wraith Scheme floating-point calculations may vary depending on which version of macOS you are running and on what kind of Macintosh you have, even if you perform the same calculation, using the same input data. The differences are typically very small -- down in the least significant digits of the result -- but they are there. The trigonometric and inverse-trigonometric routines are where I have most often noticed such differences.
The bit about "kind of processor" used to matter for earlier versions of Wraith Scheme, which could run both on Macintosh computers with Intel processors and on those with PowerPC processors, and now matters for later versions of Wraith Scheme, which can run on Macintosh computers with Intel processors and on those with "Apple silicon" processors, that are based on the Arm architecture.
Here are a few hints about problems that may happen when you try to run Wraith Scheme:
Make sure you have met the system requirements for Wraith Scheme. If that doesn't help, you might want to try some of the steps listed in the "Elementary Debugging" section. Or you might just want to send me a bug report.
Note in particular that versions of Wraith Scheme up through version 2.25 will not run on Macintosh computers with "Apple silicon" processors, not even under the "Rosetta 2" emulation system.
Check the MacIntosh Console Log for error messages from Wraith Scheme: Wraith Scheme may put error messages there if it encounters a problem early in starting up, before Wraith Scheme's own error-reporting mechanism has gotten going. The console log is somewhere in the "Console" folder of the "Logs" folder of your computer's "Library" folder. On my Macintosh, the Unix path to the console log I look in is "/Library/Logs/Console/501/console.log". (The "Console" folder is organized so that there is one console file for each user who has an account on your Macintosh -- the "501" in the Unix path refers to the folder with the log for the user account I use on my own Macintosh when I am using Wraith Scheme.)
The way macOS handles error messages has changed over time, and I have modified Wraith Scheme's error-handling system to catch up: On versions of Wraith Scheme past 2.25, I have installed a mechanism to record certain fatal error messages in a text file in the Unix "/tmp" directory. The full path to that file is "/tmp/WraithSchemeFatalErrorLog.txt". Wraith Scheme will create that file if it does not exist, and will append new error messages to the existing file if there already is one. If you like, you may delete the file, and Wraith Scheme will create a new one when needed.
Try running Wraith Scheme with less memory requested. See the section, Changing the Startup Defaults.
The likely cause of this problem is that Wraith Scheme is trying to initialize a large main memory, and that does take a while. As a rule of thumb, if the main memory size you have requested exceeds a quarter the size of the physical memory (RAM) installed in your Macintosh, initialization delays may be excessive. The main fix here is just to wait, though it may help if you shut down other applications.
If you don't want to wait, you may force Wraith Scheme to quit via the special menu that appears when you option-click on the Wraith Scheme icon in the dock. If you want Wraith Scheme to forget about trying to use a large memory in the future, find the Wraith Scheme preferences file and delete it, and Wraith Scheme will create a new preferences file with default preferences the next time you start it up:
The preferences file will be named "com.JayReynoldsFreeman.WraithScheme.64.plist" (yes, it will have my name, not yours), and it will be located in the "Preferences" folder of the "Library" folder of your home folder.
Technical Note: If you are willing to be bold, you may edit that preferences file by double-clicking on its icon. That will only work if your Macintosh contains an application -- like Xcode -- that can open a preferences file. Once it is open, click on the small triangular icon near the word "Root", locate the "MainMemorySize" item, click on the number associated with it -- it is in megabytes -- and change it to however many megabytes of memory you want. If things get messed up, just delete the whole file.
The reason you have to modify or delete the preferences file in this circumstance is that when Wraith Scheme is initializing memory, it hasn't yet gotten far enough in starting up so that you can just open the preferences window and change the memory size in a more normal way.
The likely problem is that Wraith Scheme is using a large main memory, in which garbage collection simply takes a long time.
The speed of garbage collection will vary from fast -- when the Wraith Scheme main memories are contained entirely within physical memory chips -- to very slow -- when the Wraith Scheme main memories are in part stored as virtual memory, on disk. It takes a long time to "swap"; that is, to move data back and forth between disk and physical memory. On a 2006 model Macbook, with a 2 GHz Intel Core Duo processor and 1 GByte of memory, with no other user processes but Wraith Scheme running, with a Wraith Scheme main memory size of nearly 1 GByte, with a substantial portion of main memory containing non-garbage, I have seen garbage collection take as long as twenty minutes. More modern Macintosh computers are enormously faster, but that means you can use more memory, and garbage collection will again be slow: On a 2021 Mac Mini, using Apple's "M1" processor, with 8 cores and 8 GBytes of physical memory, I once ran Wraith Scheme with a Scheme main memory size of 64 GBytes, and when that filled up, garbage collection took half an hour.
Have you clicked in the Input Panel, to select that area for typing? The Input Panel is normally the only part of the Wraith Scheme window that will accept typing: If your last mouse click in the Wraith Scheme window was anywhere else, anything you type will be ignored.
The left end of the Input Panel.
These basic primitives, as well as several others, are macros that are only available in the saved world that comes with Wraith Scheme, or in worlds that you have made from it. See the section, Wraith Scheme Startup Actions.
See the Scheme References and Lisp References sections. In order from simplest to most complicated, I recommend (1) Friedman and Felleisen, (2) Springer and Friedman, and (3) Abelson, Sussman and Sussman. And do get a copy of the "R5" report: You will need it sooner or later.
Or, try an Internet search.
Don't forget the help files available via the Wraith Scheme Help Menu.
Open the "Preferences" panel via the Wraith Scheme menu, clear out the text in the window after "Load This Source File After Startup", and press the "Accept These Preferences" button. (Note that the "Choose" button in that panel is to allow you to select another Scheme program to run when Wraith Scheme starts running, if you should wish to do so.)
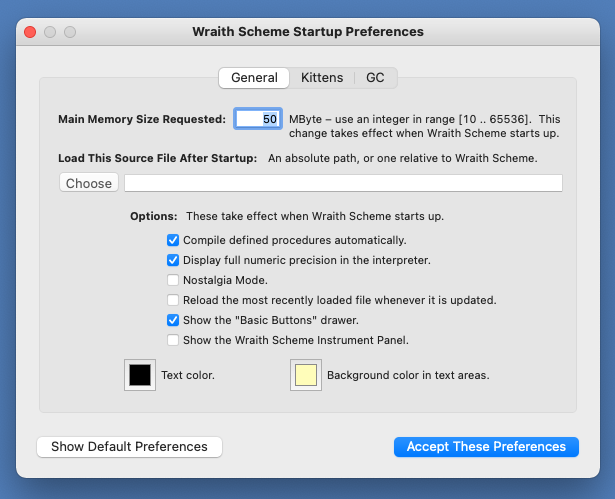
The Preferences Window, with "Load This Source File After Startup" cleared.
Look in the Font Menu for commands to change font size, text color,
and background color. And hey, I like the yellow background. But if you do not, there
are many alternatives ...
Font sizes and colors to suit every mood...
Use any programming editor, text editor, or word processor you like, to create a file containing your source code. Save it as a text document -- Scheme requires ASCII text. Use Wraith Scheme's "Load File" command (in the Interpreter Menu) to load the file, then do what you will with the things your file defines.
If you are debugging code, Wraith Scheme has the commands "Reload Last File" and "Load Recent File..." (all in the Interpreter Menu, and there is a button for "Reload Last File" in the Basic Buttons Drawer) which allow you to get at recent files quickly, without fussing with a browser or a long path name.
There is also the "Automatically Reload Last File After You Save Changes" command in the Interpreter Menu (and there is a button in the Basic Buttons Drawer) that does the same thing). When you check this command, or push the button in, Wraith Scheme will look at the last file you have loaded every few seconds, to see whether you have updated it. If so, Wraith Scheme will reload the file automatically -- in essence, Wraith Scheme will push the "Reload Last File" button for you, whenever you update the file. That way, you can make changes to the file using your favorite editor, save them, and have the newly-changed file loaded by Wraith Scheme automatically, so that your changes will be ready to test when you switch to the Wraith Scheme window.
Letting Wraith Scheme load files this way allows you to create and edit Scheme source-code files using the editor you prefer, instead of using some built-in editor that I happened to like.
Wraith Scheme's internal compiler is indeed fairly slow, and I have no present fix for that problem. Remember that you can turn the compiler off, via the "Compile Defines" menu item in the Interpreter Menu, or by means of procedures described in the State Flags section. Also, be advised that the compiler is much happier dealing with a large number of small procedures than with a small number of large ones.
Welcome to the club. Many programming editors have parenthesis-matching features; I happen to like EMacs, which is no longer provided with Apple's "Xcode" development environment but can be downloaded from various open-source repositories.
Wraith Scheme itself will provide cues about missing parentheses and missing double-quotes when you are entering text directly into the Input Panel: Open the Basic Buttons Drawer, type an expression that doesn't have enough right parentheses -- something like
(+ 2 2
-- and then press "return". A little text panel will appear at the bottom of the Basic Buttons Drawer to remind you about the missing right parenthesis, like this:
For a missing quotation mark, the panel looks like this:
If you encounter a problem while running Wraith Scheme, by all means send me a bug report.
You might want to do a few things on your own before contacting me, both to save your time if the problem turns out not to be Wraith Scheme's fault, and to help me identify and fix any bug that may be present.
Try to pin down what it takes to make the problem happen, as accurately and completely as you can. Unreproducible bugs are almost impossible to fix. They are like the rattle in your car that goes away when you take it to a mechanic, or the things that go bump in the night but are not there when the sun rises.
Here are some things to do, that might help pin down a problem:
If the problem happened when you were running code that you had compiled, try again without compiling the code. That is, turn off the "Compile Defines" option, reload your code without applying "e::compile-form" to any of it, and try again. If the problem does not recur, or recurs in a different way, it may be that the difficulty is with the compiler itself.
Reboot your Macintosh and try again.
Get a fresh copy of Wraith Scheme and try again.
Carefully consider the possibility of a computer virus or similar software abomination. There are no general rules to detect these: No two are alike. Magazine articles, Internet searches, user groups and dealers can help you learn about the latest viruses.
See if you can duplicate the problem on another Macintosh. If so, then you will know that your own computer's hardware and software are not at fault: Perhaps the fault is mine, and you should send me a bug report.
If you do send me a bug report, give your best description of the problem and of what I must do to make it recur for investigation. State what kind of Macintosh you used, how much memory it had, what version of the Apple System Software you used, and whether you were using the compiler. If you suspect a problem with Wraith Scheme's interaction with some other software, tell me about that, too.
It will help me a lot if you do these things and describe what happened, and you may be able to save yourself some time if the problem turns out to be one you can fix.
I may not be able to do much about your bug, though, if I do not have the same kind of Macintosh and the same software that you do: If the problem turns out to have something to do with hardware or software that I do not have, I am unlikely to be able to reproduce it, much less fix it.
This section describes the tests I perform before releasing a version of Wraith Scheme. I include it not to boast about how much testing I do, but to apologize for how little. I want you to be able to read this section if you encounter a problem, and learn immediately whether or not you are using Wraith Scheme in a way I have tested. Don't waste time trying to cope with problems I have had no opportunity to ferret out: Just send a bug report.
Wraith Scheme was originally developed on a 13-inch Macbook with a gigabyte of memory and an 80-gigabyte hard drive, running macOS version 10.4.6 and later. I later acquired a 2008 model Mac Pro, initially running macOS version 10.6.1 but subsequently upgraded, and used that for many years. Now I have a 2019 Mac Pro running macOS 11.6, which I use for development and testing of Wraith Scheme.
I have a test suite comprising millions of Scheme S-expressions, which I run frequently. In general, the tests operate by calling either "load" or "e::set-input-port!" on various files, or by redirecting I/O via command-line options, and record output on transcript files, for subsequent comparison with files that contain correct output for the tests. My suite attempts to exercise each built-in function or macro of Wraith Scheme in at least a few interesting cases, to create every non-fatal error condition that Wraith Scheme can detect, and to perform many tests of Wraith Scheme's numeric input and output routines.
Prior to releasing Wraith Scheme, I run the test suite repeatedly, to verify that Wraith Scheme does not crash and continues to produce correct results.
Not all of the features of Wraith Scheme can be exercised by evaluating expressions: I use a list of manual operations to test Wraith Scheme Instrument Panel commands, Dialog Panel interactions, and so on.
None of this should impress you. I have worked professionally in software/hardware testing, where I have seen person-years of effort and machine-years of computer time spent on testing and debugging systems simpler than Wraith Scheme, without finding all the bugs. I have made only a small fraction of that effort testing Wraith Scheme.
Furthermore, I have little access to other computers for testing.
I would appreciate additional reports of successful use of Wraith Scheme on Macintosh configurations or types that I have had no opportunity to test. I will be particularly eager to hear of any bugs in Wraith Scheme that appear to relate to circumstances that I did not test.
Notwithstanding the formal test suite, probably the most important testing I do is to use Wraith Scheme myself. I have written lots of macros and a compiler in Wraith Scheme: They or the code they generate are part of the distributed world loads, and are exercised in even the simplest Wraith Scheme programs. I have used a checkbook-balancing written and run in Pixie Scheme to manage my own checkbook, and the bank hasn't come after me yet. (That program has been ported to Wraith Scheme, and is available via the "Source Code Examples" menu item of the Help Menu.) I have written or ported a good deal of other software, and it all seems to operate correctly. That's encouraging. But the ultimate test is not whether I find any more bugs in Wraith Scheme, but whether you do. Let me hear from you when that happens.
This section summarizes what is new in Wraith Scheme since the previous release. I omit cosmetic improvements, minor changes in documentation, and minor changes in displays.
Items are listed in more or less the order in which I dealt with them.
The current release is 2.28, the seventeenth release of Wraith Scheme as a 64-bit application, and the seventeenth release under the GNU General Public License.
This section summarizes changes in Wraith Scheme between its first release and the last release but one. It includes changes in the earlier, 32-bit application up to the time I started work on the 64-bit version, but omits bug fixes and small updates made to the 32-bit version since that time. I also omit mention of cosmetic improvements, minor changes in documentation, and minor changes in displays.
Release 2.27 was the sixteenth release of Wraith Scheme as a 64-bit application, and the sixteenth release under the GNU General Public License.
Release 2.25 was the fourteenth release of Wraith Scheme as a 64-bit application, and the fourteenth release under the GNU General Public License.
Release 2.24 was the thirteenth release of Wraith Scheme as a 64-bit application, and the thirteenth release under the GNU General Public License.
Release 2.23 was the twelfth release of Wraith Scheme as a 64-bit application, and the twelfth release under the GNU General Public License.
Release 2.22 was the eleventh release of Wraith Scheme as a 64-bit application, and the eleventh release under the GNU General Public License.
Release 2.21 was the tenth release of Wraith Scheme as a 64-bit application, and the tenth release under the GNU General Public License.
Release 2.15 was the eighth release of Wraith Scheme as a 64-bit application, and the eighth release under the GNU General Public License.
Release 2.14 was the seventh release of Wraith Scheme as a 64-bit application, and the seventh release under the GNU General Public License.
This problem only occurred when the user option "Use smooth scrolling" was selected: That option is controlled by a check box in the "Appearance" pane of the "System Preferences" application.
This problem may have been the actual cause of the "hardware-dependent" bug reported fixed in the release of Wraith Scheme 2.10 (discussed below). I still worry about bugs that only show up in particular combinations of hardware and software.
Release 2.13.1 was the sixth release of Wraith Scheme as a 64-bit application, and the sixth release under the GNU General Public License.
Release 2.13 was the fifth release of Wraith Scheme as a 64-bit application, and the fifth release under the GNU General Public License.
(e::compile-form (e::compile-form (lambda ... )))
did not always produce the correct result. (The outermost "e::compile-form" should have had no effect, but sometimes it did.)
Release 2.12 was the fourth release of Wraith Scheme as a 64-bit application, and the fourth release under the GNU General Public License.
Release 2.11 was the third release of Wraith Scheme as a 64-bit application, and the third release under the GNU General Public License.
Release 2.10 was the second release of Wraith Scheme as a 64-bit application, and the second release under the GNU General Public License.
For a somewhat more detailed introduction to generational garbage collection, see the "Glossary" section of the Wraith Scheme Dictionary.
Release 2.00 was the first release of Wraith Scheme as a 64-bit application, and the first release under the GNU General Public License.
Release 1.34 was the tenth release of Wraith Scheme.
Release 1.33 was the ninth release of Wraith Scheme.
Release 1.32 was the eighth release of Wraith Scheme. Things new in it included:
The war story here is, that I had done previous testing of the parallel implementation of Wraith Scheme on a Macbook 13, that only had two processor cores and in fact ran relatively little code in parallel -- it mostly swapped. In late January, 2008, I bought a high-end Mac Pro, with eight cores; it was more than capable of running several Wraith Scheme processes in parallel, and "shook the tree" sufficiently hard thereby, to expose a handful of bugs that had escaped earlier testing.
They were tough bugs, involving communications and locking between multiple asynchronous processes, and in general never repeated themselves the same way twice. It took three months to get things back to stable. I don't ever want to do that again, but I fear that I shall have to.
Release 1.31 was the seventh release of Wraith Scheme. Things new in it included:
Release 1.30 was the sixth release of Wraith Scheme. Things new in it included:
(set-car! (list '(1 2 3)) <object>) ;; ==> <error message> (set-cdr! (list '(1 2 3)) <object>) ;; ==> <error message>
Both of these error messages were incorrect: Both operations should have worked, and now do.
Release 1.21 was the fifth release of Wraith Scheme. Things new in it included:
Technical Note: C programmers can probably figure out what caused the problem ...
On Macintosh computers that use Intel processors, Wraith Scheme now returns an exact result when the result of the division is exact. For example:
1/2 ;; ==> #e0.5 ;; Exact.
but of course
1/3 ;; ==> 0.33333333333333331 ;; Inexact.
On Macintosh computers that use PowerPC processors, Wraith Scheme still returns an inexact result even if the result of the division is exact. For example:
1/2 ;; ==> 0.5 ;; Inexact.
and of course
1/3 ;; ==> 0.33333333333333331 ;; Inexact.
The philosophy here is that Wraith Scheme will report numbers as inexact unless it can prove that they are exact.
(do ((i 0))
((= i 3) #t)
(display i)
(newline)
(set! i (+ i 1)))
did not work, whereas the seemingly-equivalent
(do ((i 0 (+ i 1)))
((= i 3) #t)
(display i)
(newline))
worked just fine. Now, both work.
Release 1.20 was the fourth release of Wraith Scheme. Things new in it included:
Release 1.10 was the second release of Wraith Scheme. Things new in it included:
Release 1.00 was the first release of Wraith Scheme; it was all new.
Besides fixing bugs and making internal improvements, my wish list for the future of Wraith Scheme includes the following items, which are not necessarily in the order in which I might get around to doing them:
The GNU folks have a library for multiple-precision arithmetic which might allow a relatively straightforward implementation of bignums in Wraith Scheme, and I am tempted to see if I can create one.
The future probably does not hold:
R6 and R7 are much more complicated Scheme standards than R5. I find most of their new features neither interesting nor useful to me personally, and there are other aspects of Scheme that I would prefer to work on. In that context, I simply don't have time enough to develop and maintain an R6 or R7 implementation of the quality that I would like to present as shareware.
There has been a great deal of controversy about these standards in the Scheme community. I hope no one will misconstrue lack of support for them in Wraith Scheme for me taking a position against the new standards and being too cowardly to say so. The plain truth is that I find the new standards overwhelming: They are too complicated for me to support all by myself.
Notwithstanding, I may implement some features of versions of Scheme later than R5, if I find them useful and if they do not conflict too much with existing features of Wraith Scheme.
Many people think the different kinds of numbers are separate, so that no number can be of more than one kind. They think that integers and reals are different kinds of numbers, so that no integer can be real, and so on.
That's false. They overlap. Specifically, every integer is also rational, real and complex; every rational is real and complex; every real is complex; and they're all numbers.
For example, 1 is an integer. It is also a rational (being equal to the quotient of two integers, namely 1/1, or 2/2, or ...), it is on the real line, and it is also in the complex plane -- we could write it as 1 + 0i. Typographic choices, such as the inclusion of a decimal point, an exponent, or trailing zeros, do not alter the mathematics. Thus "1", "1.", "1.0", "1.0e0" and "1.000000000000000" are all ways to write the same mathematical number; namely, the integer "one".
Some wag once said, "A computer scientist is a person who refuses to believe that 1.000 is an integer." Don't you make that mistake.
Much of this confusion is because many computer languages use different kinds of machine storage for numbers given with a decimal point than for numbers given without one. A language might store "1.0" as an IEEE 64-bit floating-point number, yet store "1" as a 32-bit word with just the least-significant bit turned on. It is the integer "one" in either case. Some people think floating-point numbers cannot be integers. That's wrong. What counts is the value, not how it is stored.
If you want to know how Wraith Scheme is storing a particular number, there are some special predicates you can use to find out.
More confusion stems from the fact that typographic conventions are widely used to convey information about the precision of a number when that number is imperfectly known. Thus in science or engineering, use of the string "1.000" to represent a number often means "the number I am talking about is between 0.9995 and 1.0005, but I don't know for sure what it is, so I will use the representative exact value 1 to stand in its place, and will give the value to four significant digits to hint at the level of my ignorance." This convention obscures the mathematics of numeric types: Thus in the example given, the integer 1 might actually be standing for the integer 1, for the rational number 10001/10000, for the irrational number (1 + pi/10000), or for the complex number (1 + i * pi/10000).
The built-in features of Scheme are in any case not powerful enough to support such conventions: You can specify that a number is exact or inexact by means of the "#e" and "#i" prefixes, but Scheme records only that one bit of information. There is no built-in means to tell Scheme how many digits of precision the number has. As far as input to Scheme is concerned, the strings "1.50000" and "1.5" indicate the same number and the same status of the "exact bit". (In the case of Wraith Scheme, that number is the inexact rational 1.5.)
Just for fun, ask yourself (A) Which of the following numbers are complex? (B) Which are real? (C) Rational? (D) Integer?
42 1. -2.000000 345.62e2 9.6149604775e23
Answers: (A) All of them. (B) All of them. (C) All of them. (D) All of them.
Where do I start ...
Wraith Scheme is a descendant of Pixie Scheme, which I wrote for mid-to-late-1980s versions of the Macintosh. Much of Wraith Scheme's technical minutiae stem directly from Pixie Scheme, but for clarity (hah!) I will not always distinguish between Wraith Scheme and Pixie Scheme in this section.
Pixie Scheme was written in C, specifically in Macintosh Programmer's Workshop (MPW) C versions up through 2.0.2. I developed it on a plain vanilla Macintosh II with 1 MByte of memory -- no typo, that's "M" for "mega". It ran fine in one megabyte. (It takes more now -- I suggest 10 MByte.) I later bought some more memory, and ported Pixie Scheme to later versions of MPW C -- the last was 3.2b3.
Many failings or biases in the first release of the program no doubt reflected the specific nature of my environment. For example, 1 MByte wasn't enough memory to test Pixie Scheme adequately under MultiFinder. For example, Apple didn't get around to releasing an MPW C compiler that generated correct 32-bit code until after I had shelved the Pixie Scheme project. (That last was very frustrating. My early Mac II was not a full 32-bit machine in any case; it had an Apple memory-management unit that handled only 24-bit addresses, so the program worked fine for me. Yet I would get bug reports from folks using 32-bit machines that I couldn't so much as duplicate, much less fix. I didn't even know anyone who owned a 32-bit Macintosh at the time.)
More recently, I ported Pixie Scheme to run in a Unix (Terminal Application) window in macOS X on a 2006 Macbook, using the GNU C compiler. That was enough of a change to warrant changing the name of the program, to Wraith Scheme. First I made it run using only the simplest kind of terminal input and output -- the kind of thing that would work on a teletype. Then I got a version going that used the Unix "ncurses" package for terminal output.
The experience of excising the essence of Pixie Scheme from an old-style Macintosh application, and getting it going under Unix with two quite different styles of I/O, gave me a chance carefully to encapsulate the code for a functioning Scheme interpreter separately from the code that let that interpreter communicate with the outside world. I had actually planned it that way -- even when I was writing Pixie Scheme, I anticipated that maybe, some day, it would run in a different I/O environment, and therefore I tried to perform the encapsulation at that time. I was setting up for what is now called the "model-view-controller" pattern of software design and implementation, though I am not sure that the term existed then.
From there, it was straightforward -- I won't say easy -- to wrap a more modern Macintosh-style user interface around the Scheme interpreter. It took about a month of serious effort to get Wraith Scheme going as a Macintosh application. The Macintosh wrapper was a "Cocoa" application that involved not quite three thousand lines of Objective C (more now) and a set of interface classes (".nib" file stuff) built in Apple's Xcode development environment.
After a while, I thought of a way to make Wraith Scheme a parallel Scheme, with many separate Wraith Scheme processes (Unix processes) sharing a common Scheme main memory. It took a fair amount of work to make that work.
Still more recently, I decided to make Wraith Scheme a full 64-bit application, and to use 64-bit pointers in Scheme main memory as well. I also decided to make subsequent versions of Wraith Scheme require macOS 10.6 ("Snow Leopard") or better, which in turn meant that they required a Macintosh with an Intel processor. (The last version before that change, that will run on macOS 10.4 ("Tiger") or better, and that will run on a Macintosh with either an Intel processor or a Power PC processor, is still available; it is Wraith Scheme 1.36. I expect I will support it in the sense of fixing any major bugs that show up.) (Incidentally, I knew that it would in principle be possible to make a 64-bit version of Wraith Scheme that would run on a Macintosh that had a "G5" version of the PowerPC; I did not attempt to create one simply because I did not have a G5 Mac to test it on.)
I changed to 64 bits and to Snow Leopard or better to allow Wraith Scheme to have a larger Scheme memory, and to allow me to use some of the special Macintosh software features that were not available in earlier versions of macOS.
Wraith Scheme 2.26 both raised and lowered the bar for the system requirements for running Wraith Scheme. That version raised the bar by requiring macOS 11.6 (Big Sur) or later, but it lowered the bar by being able to run on both Macintosh computers using Intel processors and Macintosh computers using Apple proprietary processors ("Apple silicon").
Wraith Scheme is a tagged-object Lisp. Each object comprises a 64-bit tag and a 64-bit entity that is either an immediate datum or a pointer. The precise nature of the object is indicated by the tag, which has seven bits of type information, two bits for cdr-coding, two for the garbage collector, and lots more for miscellaneous internal purposes. I do not document the tag bits because the tagging scheme is likely to change in the future.
Pixie Scheme began life as an SECD machine, but it and its descendents soon changed. The present Wraith Scheme implementation stores information equivalent to the contents of the D register on the stack, and uses a stack and a continuation which are separate data structures, not heap objects. It makes copies of the entire stack and of the entire continuation, in the heap, when necessary; for instance, when "call-with-current-continuation" is called.
The virtual machine that describes the implementation includes about a dozen registers. There is a stack pointer, which refers to a stack that is implemented as a data structure separate from the heap. There is a pointer to a list of environments. That entire list is a heap object. A continuation register points to a separate data structure that represents a list of instructions next to be executed; it is essentially the C register of an SECD machine. There is a register for returning tagged-pointer values from functions, a register for the top-level environment, several registers for ports in use, and a couple of scratch or special-purpose registers.
I have touched on the structure of Wraith Scheme's environment list while discussing the debugger, and will not repeat myself here. What gets put on the stack is too complicated and too subject to change to discuss.
Almost all text Wraith Scheme prints out, including most error messages and function names, is stored internally in large arrays of text strings. They used to be Macintosh resources when I was building Pixie Scheme with the old Mac ToolBox. Thus it should be relatively easy for an experienced C programmer, who has access to the source files for the Wraith Scheme program, to create custom versions of Wraith Scheme, or to port the program to another (human) language. Since the only language I speak well is English, I have not tried to do so myself, so I have undoubtedly forgotten to make it easy to alter some things that would need to be changed, but I suspect that what I have done would be helpful in such a project. If anyone is interested in such a port, contact me.
Wraith Scheme is written in a strongly object-oriented fashion. (If there had been a decent C++ or similar object-oriented variant of a C compiler available for the Macintosh at the time I started writing Pixie Scheme, I certainly would have used it.) There is lots of data encapsulation. There are many objects (structs) which contain (pointers to) functions which perform various operations, whose details differ from object to object. Thus I have a generic method for printing objects, which contains no "switch" statement: It merely looks up the "print" method for the object itself. In consequence, for a C program, Wraith Scheme is remarkably easy to modify and maintain. For example, it took only a few hours to add support for IEEE 80-bit floating-point numbers to Pixie Scheme, and most of that time was spent writing functions that actually implement operations on these entities, not in tying 80-bit floats into the control-flow structure of the program.
The view was originally an interface built using Apple's Interface Builder application, together with code for a couple of supporting controllers for specific parts of the view. Now I build it with the features of Apple's Xcode application, that approximate the old Interface Builder.
The main controller -- the one that sits between the model and the view -- has two parts. The first part comprises a fair number of semi-autonomous methods whose actions are triggered by various events, such as typing "return" in the Input Panel or operating one of Wraith Scheme's buttons or menu items. The second part is a timing mechanism, that polls the evaluator thread regularly, to see if it has anything for the controller to do.
The controller and model communicate via two one-way critical sections -- one for data flow in each direction -- with critical-section access controlled by pthread locking mechanisms. (And if critical-section access control were all there were to getting communicating entities to cooperate, my life would be much simpler.)
These items are all from my bookshelves or download directories. Many have more recent editions.
These items are all from my bookshelves. Many have more recent editions.
Letter sent in 1988 to the editors of "The California Tech", California Institute of Technology, Pasadena, California:
Dear Editors:
This June it will be twenty years since I graduated from CalTech. The anniversary has made me think: Possibly my thoughts may be relevant to the present student body.
After CalTech I went to graduate school at the University of California's Berkeley campus. It was like going from a monastery to a madhouse. From the late sixties through the mid seventies, Berkeley was a tumultuous place, full of people who were bound and determined to change the world. What's more, each of them seemed to have a different idea of how to go about it. I could scarcely pass through the campus gates without being accosted by handbill-distributors from every imaginable kind of political, social and economic action group, all bent on modifying civilization to suit themselves. There were libertarians and communists, republicans and democrats, churches both bizarre and familiar, ecological advocates, draft resisters and military recruiters. The campus seemed overflowing with charismatic, impressive leaders, each with a separate agenda for social change.
Often there were demonstrations: I rapidly learned to cut through the back alleys to get to class. Sometimes there was real violence: Once I walked out of the student cafeteria after lunch, only to find a National Guard helicopter spraying the plaza with riot-control gas. I decided I had better go back inside and have dessert.
I was too bewildered to have anything to do with all this. I gravitated toward a small, ever-changing circle of science buffs and technology enthusiasts, people much like myself. We had no charisma and impressed no one. We would go out for pizza and talk. The discussion topics changed as our informal membership varied -- many liked space exploration, one was enthusiastic about computers, and so forth. If pressed, most of us would cautiously admit to some faith that scientific and technical developments were also important agents of social change, but in the midst of widespread turmoil of a different kind, I found such a belief ever less tenable. As the years passed, it seemed increasingly that the things I was interested in could scarcely matter in comparison to those other, more powerful forces.
Yet in retrospect, it is remarkable how little came from the social and political movements of that time and place. I no longer remember the names of any of the Berkeley people who were out to change the world. I scarcely recall what they wanted to do. After a decade or two I must look hard to find our planet any different for their efforts. It seems that in the long run, they mattered all but naught.
To my embarrassment, I have even forgotten most of the people in our group of pizza-eaters. Only recently did someone remind me of the name of the fellow who came to a few meetings and talked with such zeal about the prospect of small computers and their likely capabilities.
His name was Steve Wozniak.
Keep the faith.
Jay Reynolds Freeman
BS (Physics) '68
May 1, 1988
The following excuses may help explain flaws or omissions in Wraith Scheme:
I do not possess your level of wisdom, insight or experience.
My computers have included Mac Pros, a Mac Mini, several kinds of Macbooks, and a G3 iBook. I did not test Wraith Scheme extensively on other kinds of Macintosh.
I didn't think of that.
I was interested in writing a Lisp system, not a (choose one or more)
text editor.
ToolBox interface.
NS object interface.
whizzy graphics package.
...
I did not test Wraith Scheme under older versions of Apple's system software.
I didn't know how.
I thought I knew how, but I was wrong.
I was too lazy to do it right.
I did it the the way the R5 report says it should be done.
I did it my way.
< long, long pause ... >
To begin with, I know of no programming language better than Lisp for building large programs rapidly: Lisp has been described as the best language in the world for building castles in the air, single-handed, overnight. Furthermore, I am interested in various technical details of implementing Lisp, in possible future Lisps and Lisp-like languages, and in blazing fast compilers.
Given my fondness for Lisp programming, obviously I wanted a Lisp system around. Given my interest in internal details, developments and modifications, obviously I needed a system with source code, and I needed to be thoroughly familiar with that code. There were (and still are) several Lisps available with source, but the best means I know to become familiar with all the details of a large piece of code is to write it.
Scheme is a small modern Lisp, well in the forefront of research in Lisp-like languages, whose nature allows it easily to be compiled.
Common Lisp is much larger than Scheme, in the sense of lines of code and time required to write them. Furthermore, in my opinion, Common Lisp is not nearly as elegant as Scheme.
I had cat named "Wraith" whom I dearly loved.
It makes as much sense as naming a computer after a raincoat. (Mee-yow!!)
(For the record, evidently Jeff Raskin deliberately misspelled "McIntosh" -- which is a variety of apple -- when he named Apple's new "computer for the rest of us". But so what -- it's still named after a raincoat!)
It rhymes with "faith".
To those who understand, no explanation is necessary; to those who do not understand, no explanation is possible. Besides, they remind me that love can be unconditional, that innocence is worth protecting, and that curious optimism may discover a solution when greater minds would give up in despair.
If you can't make it insanely great, at least make it greatly insane. Besides, where else would I find a captive audience for my jokes?
Who said anything about future versions? Oh, excuse me, I did. Well, there's an old Russian proverb: "Hope for the best, and expect the worst; thus you shall never be disappointed." What you should expect is very little, perhaps not even bug fixes if I get busy or distracted. One might hope for a faster and better compiler, more speed in general, a more powerful interface to the file system, a better debugger, and access to a small selection of whizzy Macintosh special features. I doubt there will be a built-in editor, a graphics package, or anything like a complete interface to all the NS functions in known space.
Use a text editor, and load the file. I use EMacs, but many others would do as well. On a Macintosh, cut-and-past and drag-and-drop work very well for moving small bits of text into or out of the Wraith Scheme window, as do the various buttons and menu items for loading recent files and for loading files when updated.
Note that the "Automatically Reload Last File After You Save Changes" menu item of the Interpreter Menu, and the button of the same name in the Basic Buttons drawer, provide a way to load a file whenever it is updated. Thus you may use whatever editor you like to work on a file, and have Wraith Scheme load it for you automatically, as soon as you save your changes.
Portions of the source code embarrass me: How many cooks -- even good cooks -- want people to see what their kitchen looks like? (For me, cooking is not so much an art as a survival skill -- how to stay alive in the kitchen.) Besides, I did not wish to deprive you of the chance to write your own 80000-line program ...
It was a clear case of laziness versus masochism. Laziness won.
For any chance of commercial success, I would have to do a compiler with a decent native-code code generator. Otherwise, the system's speed will not be competitive. I'm not sure I want to bother; I am interested in other aspects of compilation.
Besides, I do not sense that the world is waiting with bated breath for yet another artificial-intelligence programming-language implementation just now. (Too bad -- I know a lot of people who could use some more intelligence, artificial or otherwise, perhaps most notably me ...)
Wraith Scheme is a direct descendant of "Pixie Scheme", which I developed in the late 1980s and early 1990s. Pixie was another cat. Pixie Scheme ran on Apple Macintosh computers of that vintage, was available as shareware -- I asked for a shareware donation of one dollar -- and was actually used here and there. I shelved the Pixie Scheme project in 1991, because it had grown to the point where it was pushing on the limits of my original-model Mac II and of my development software. In 2006, I finally got a new Macintosh, and decided to do a port of Pixie Scheme to run in a Unix terminal shell on my Macbook under macOS X. First I got it to run using the GNU C compiler, then subsequently the GNU C++ compiler, then I wrapped a contemporary Macintosh interface around it. Those changes seemed enough to warrant a new name; hence "Wraith Scheme".
My "Wraith Scheme" files include over 80 000 lines of source code -- C++, Objective C and Scheme -- and more than a million lines of test programs and expected answers to those tests. It took the equivalent of several years of my professional time to create Wraith Scheme, in isolated intense bursts spread over the five years 1987-1991, and in the period from late 2006 to date. I am a moderately experienced C and Lisp programmer (I have probably written over 300 000 lines of finished code of the former, including C++, and 75 000 lines of the latter), but Pixie/Wraith Scheme is by far my most complicated program ever.
Pixie Scheme was my first stand-alone Macintosh application. (I must have learned something: It took less than twenty minutes to write the second one.) As Macintosh applications go, Pixie/Wraith Scheme is a little weird: For example, it sort of does not have a main event loop. (Pixie Scheme really didn't have one; Wraith Scheme uses one for the user interface, but not for the Scheme interpreter itself.)
The greatest single break I had in this project was that I did not have access to a personal computer when I started working on Pixie Scheme: I spent over six months in design and analysis without writing a single line of code. I am certain that without so spending this time, I would not now be nearly as far along with Wraith Scheme as I am, and I strongly suspect that I would have given up on Pixie Scheme in the first place.
In developing Pixie Scheme, I missed a utility like Unix's "lint". I missed a C compiler that accepted function prototypes. I missed a lot of sleep. I missed a source-level debugger. I used MacsBug now and then. The combination of Apple's Xcode development environment and GNU tools that I use for Wraith Scheme, is a whole lot better than what Apple provided in the late 1980s.
I have one good war story: I gave the booleans #t and #f each an identifying tag, so it didn't matter what the datum part of one was. When I wanted a Pixie Scheme routine to return #t or #f, I would just set the tag of the return value appropriately, and ignore the rest. But then I made a mistake in the routines that compared them for equivalence; they tested not only the tag but also the 32-bit datum with which it was associated. I had inadvertently created 2 to the 32 kinds of #t, all printing alike but no two equal. And I had done the same for #f. I was reminded of Arthur C. Clarke's short story, "The Nine Billion Names of God". And I was pleased to have modeled reality well, by creating almost enough kinds of truth for every human alive to have a different version. That might be sufficient even for politicians, religious authorities, and business executives.
The on-line documentation for Wraith Scheme comprises approximately 200 000 words. War and Peace runs about 460 000 words in English translation, so I still have a way to go. Pride and Prejudice has only about 124 000 words, so there may be hope. (And my cats have included Darcy, Willoughby, Emma, Elinor and Knightley.)
Er, ah, um... because! That's why -- because! Seriously, I bought my Macintosh II because it was almost surely the most powerful personal computer system then available (in the second quarter of 1987), particularly for programs that required easy access to much memory. I knew C well, and there were good C development systems available for the Mac II. The only decent object-oriented language available for the Mac at that time was Apple's Object Pascal, but I have never particularly liked Pascal. So I developed Pixie Scheme as a C program, using the Apple "Macintosh Programmer's Workshop" environment and compilers. There were no decent C++ compilers for the Macintosh when I started the Pixie Scheme project, so C++ was not an option at the time. (The GNU folks were working on what was to become g++, but it was still pretty buggy and no one had yet ported it to the Macintosh. The C compiler that I started out with was not even ANSI-standard C.)
Java provides no access to the low-level Unix utilities that I have used to make Wraith Scheme a parallel implementation and to provide its foreign-function interface. Furthermore, I find Java poorly suited to object-oriented programming, and I am quite certain that without a strongly object-oriented approach to design and implementation, my Scheme implementation would have died stillborn.
Cobol would have been, ah, fascinating.
Well, neener, neener, neener. And what's more, there isn't any Santa Claus.
I think it should be you who decides what my software is worth.
I might not even ask for shareware donations at all, except that I am curious who uses Wraith Scheme, and where, and for what. I can get some idea of the first two by tracking shareware donations. Basically, I provide Wraith Scheme as a public service: I won't go on about how I think people ought to make some such use of their time and energy, but I do think so. I work professionally in computer science and am presently doing okay (knock on wood). Putting a useful piece of software into the field is one way of saying "thank you" to a lot of people who have made things easier for me, and is perhaps a way to acknowledge and encourage many others who have missed various boats that I have been lucky enough to catch. The present implementation of Wraith Scheme will set no records for high performance and will overwhelm no one with exotic features, but a reasonable, inexpensive Scheme implementation, on a computer as widely used and as easy to use as the Macintosh, is likely to be interesting to computer hobbyists and enthusiasts, and perhaps even useful for students and educators. So enjoy. And pass it on.
And if you are feeling guilty about not sending me a shareware donation, send me some EMail, and tell me how much you like Wraith Scheme. Or if you don't like it, tell me why not and what I can do about it.
As I said before, there is an old Russian proverb: "Hope for the best, and expect the worst; thus you shall never be disappointed."
It's poor for the wallet but great for the ego. During the first few months after the initial release of Pixie Scheme I barely received enough shareware donations to buy dinner in a cheap place. By dividing the total shareware donations I received by the time I spent on the project, I find I was working for about two cents an hour -- a rate that Scrooge McDuck might have paid. But for a month or so after each release, I made an offer over the "usenet" computer network, to provide a copy of the program to anyone who mailed me a disk, a return mailer, and sufficient postage. I received requests from places as remote as Finland and New Zealand: Pixie Scheme truly achieved world-wide distribution, long before the Internet came of age. I was also pleased to find that the Boston Computer Society Macintosh Users Group (BMUG) had put the first release of Pixie Scheme on one of their "developer" disks, and had also included it on a CD ROM of public domain and shareware software.
What's more, it turned out that a modest proportion of the folks who did send me a shareware donation didn't send just the dollar that I suggested for Pixie Scheme; frequently they sent as much as ten dollars. Thus I can demonstrate on the basis of actual experience that my software was worth more money than I asked for it. Who else in the software-development industry can make such a claim? Usually it is very much the other way around.
I was an "Apple Associate" during the latter part of the time I was working on Pixie Scheme. I was an Apple developer with an ADC "Select" membership from 2007 till 2010, when Apple changed its developer categories. Now I am an undifferentiated Apple Developer.
Each year they sent out several GBytes of interesting stuff on CD-ROM, as well as lots of printed documents. If I had wanted to upgrade my system, I could have done so at a discount. The folks at Developer Technical Support were very helpful. It took longer than I expected to get a reply to my application to register some of the resource types used in Pixie Scheme. I sent them a product: Perhaps they were more accustomed to vaporware.
Pixie Scheme III is a port and downgrade of Wraith Scheme to the Apple iPad™. I was intrigued by the user interface Apple was touting for the iPad -- a Scheme interpreter in that style would look much like the original Pixie Scheme of the 1980s.
At that time -- June 2010 -- Apple's rules and procedures for App Store applications were quite restrictive, so it seemed unlikely that my prospective port could make it in: I figured it would be just for me to use. That would have been sad, because I believed in public service, and surely any program-development environment for the iPad would be useful to many people. Yet I was intrigued even so.
I did not then own an iPad, so in order to play with the interface inexpensively and on familiar turf, I first wrote Pixie Scheme II, a Macintosh application with a user interface as close to the iPad style as I could manage to create. I liked its look and feel, so I then began work on the the iPad application itself, testing it on Apple's iPad simulator rather than on an actual iPad. When the app ran well enough on the simulator, I bought an iPad and made it run there as well.
About that time -- September, 2010 -- Apple changed its App Store rules so that my app might be able to get in. I dithered and made excuses for a month and a half, then submitted it, and it was accepted. Knock on wood ...
I decided to sell it for a dollar because supporting it well would mean occasionally buying more Apple portable devices to test it on, and also because I was curious about who was using it, and where. Yet Pixie Scheme III is open-source: People with the proper software tools can download it and build the app to run on their own iPads.
Life happens while you are making other plans: I am a retread astrophysicist who has worked as flight instructor, consultant to the U. S. Department of Energy, and computer scientist. My doctoral thesis project used a spacecraft instrument (1975 Apollo-Soyuz Test Project) to study the interstellar medium. My last job before retiring was in the Flight Software Group at SpaceX.
My introduction to computer science was writing small Fortran programs to reduce thesis data. (I thought they were big Fortran programs at the time.) I have spend most of my career working on parallel processing -- SIMD and MIMD, hardware and software. I once helped build a CyberSpace interface. I have worked in what marketeers call "artificial intelligence" but is better termed "system programming in Lisp". And I have won Rogue many times, without resorting to Wizard mode to do so.
I am a science fiction fan, an English Regency ballroom dancer, and an occasional bicyclist, rose grower and amateur astronomer. I play guitar and now and then build simple musical instruments. I live in Fillmore, California, with too many cats and not enough time.
I have a personal web site: http://JayReynoldsFreeman.com.
I am active on Second Life as "CeeJay Tigerpaw".
Answers to commonly-asked personal questions: blue, chocolate, chunky, single, and only if the esteem is mutual.
It was the least unsatisfactory personal computer I knew of, but that was an easy win, considering the competition. It needed a real operating system, decent graphics, and a decent user interface. Programming with the old ToolBox was like trying to wash your hands with rubber cement. And oh, yes, they should have given them away free, so everybody could have had one.
It is the least unsatisfactory personal computer I know of, but that's an easy win, considering the competition. The operating system, graphics, and user interface are much improved. Programming with the current Apple development environment is still pretty Byzantine, but if you can make it through the maze of twisty little class definitions, interfaces, and secret passageways, all alike, you have the full might and majesty of the entire Byzantine Empire -- that would be Apple -- on your side, and there is something to be said for that. And they still should give them away free, so everybody could have one.
Well, the garden needs some work, and... oh, you meant programming projects. Let's just say that I have had lots of cats.
Do you believe in users? Never mind. Anyway, remember, "lambda" is spelled with a 'b'. And I was just kidding about Santa Claus.
(Pretty much in alphabetical order, except for the cats, who of course have the last word.)
Apple Incorporated, for providing excellent software development environments and numerous examples of code, all for free.
The members of the Silicon Valley "Cocoaheads" group, for advice about the Wraith Scheme user interface.
The creators of the various "Rn" Scheme reports, for providing much clear explanatory text and numerous examples -- both simple and subtle -- of how the language is supposed to work. I am particularly grateful for the example implementations of derived expression types in section 7.3 of the R5 report, which formed the basis of the implementation of most of those types in Wraith Scheme.
Mike Deering, for lengthy discussions of tagged-pointer Lisps.
Sandy Lerner, for encouragement in development and advice on commercial prospects.
Tim May, for humor, and for the chance to play with his computer, software and other toys.
Charles Smith, for hiring me into a major artificial-intelligence laboratory.
Pixie, Wraith, Socks, Weasel, and numerous other cats, for love and purrs, and for the sharing of their ineffable names.
Notwithstanding the honest acknowledgments and grateful thanks given above, I am confident that all errors and misfeatures in Wraith Scheme are nobody's fault but mine.
-- Jay Reynolds Freeman, March 2023